 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLow-Rank Approximations for Conditional Feedforward Computation in Deep Neural Networks
Jan 28, 2014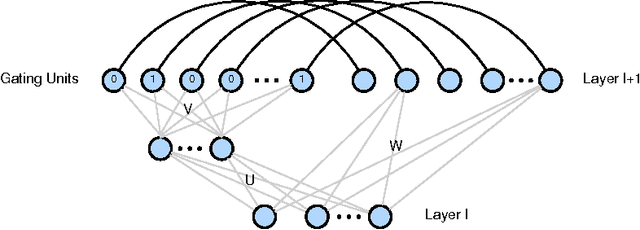
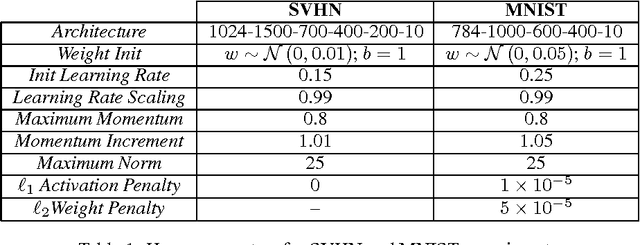
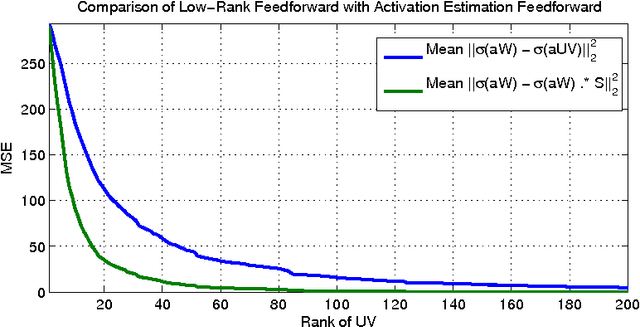
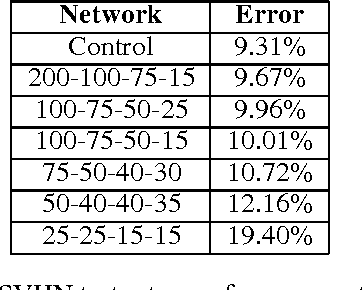
Scalability properties of deep neural networks raise key research questions, particularly as the problems considered become larger and more challenging. This paper expands on the idea of conditional computation introduced by Bengio, et. al., where the nodes of a deep network are augmented by a set of gating units that determine when a node should be calculated. By factorizing the weight matrix into a low-rank approximation, an estimation of the sign of the pre-nonlinearity activation can be efficiently obtained. For networks using rectified-linear hidden units, this implies that the computation of a hidden unit with an estimated negative pre-nonlinearity can be ommitted altogether, as its value will become zero when nonlinearity is applied. For sparse neural networks, this can result in considerable speed gains. Experimental results using the MNIST and SVHN data sets with a fully-connected deep neural network demonstrate the performance robustness of the proposed scheme with respect to the error introduced by the conditional computation process.
Gradient Driven Learning for Pooling in Visual Pipeline Feature Extraction Models
Jan 16, 2013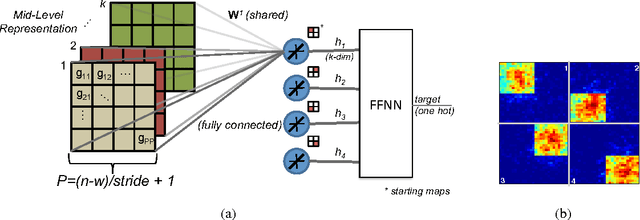
Hyper-parameter selection remains a daunting task when building a pattern recognition architecture which performs well, particularly in recently constructed visual pipeline models for feature extraction. We re-formulate pooling in an existing pipeline as a function of adjustable pooling map weight parameters and propose the use of supervised error signals from gradient descent to tune the established maps within the model. This technique allows us to learn what would otherwise be a design choice within the model and specialize the maps to aggregate areas of invariance for the task presented. Preliminary results show moderate potential gains in classification accuracy and highlight areas of importance within the intermediate feature representation space.
Recurrent Online Clustering as a Spatio-Temporal Feature Extractor in DeSTIN
Jan 16, 2013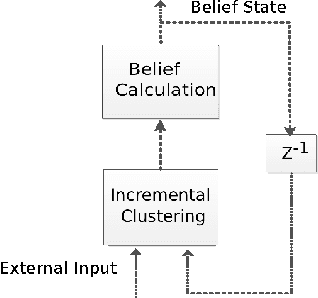
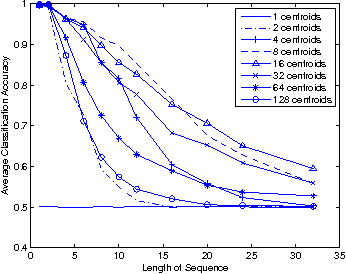
This paper presents a basic enhancement to the DeSTIN deep learning architecture by replacing the explicitly calculated transition tables that are used to capture temporal features with a simpler, more scalable mechanism. This mechanism uses feedback of state information to cluster over a space comprised of both the spatial input and the current state. The resulting architecture achieves state-of-the-art results on the MNIST classification benchmark.