 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeICDARTS: Improving the Stability and Performance of Cyclic DARTS
Sep 01, 2023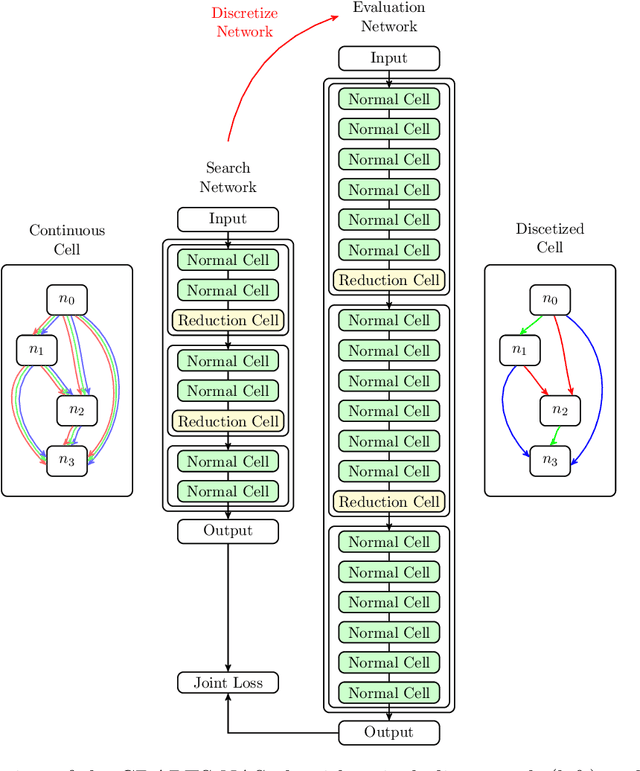
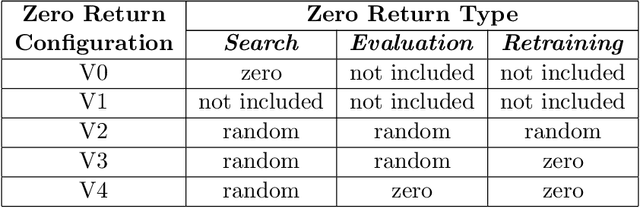
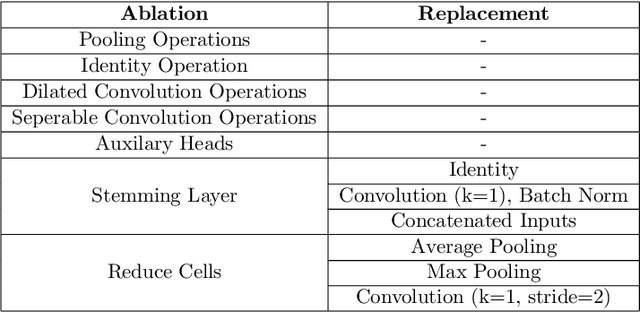
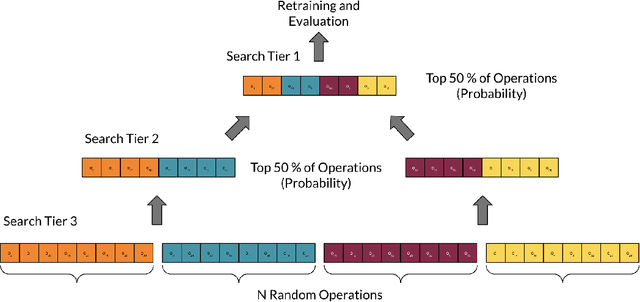
This work introduces improvements to the stability and generalizability of Cyclic DARTS (CDARTS). CDARTS is a Differentiable Architecture Search (DARTS)-based approach to neural architecture search (NAS) that uses a cyclic feedback mechanism to train search and evaluation networks concurrently. This training protocol aims to optimize the search process by enforcing that the search and evaluation networks produce similar outputs. However, CDARTS introduces a loss function for the evaluation network that is dependent on the search network. The dissimilarity between the loss functions used by the evaluation networks during the search and retraining phases results in a search-phase evaluation network that is a sub-optimal proxy for the final evaluation network that is utilized during retraining. We present ICDARTS, a revised approach that eliminates the dependency of the evaluation network weights upon those of the search network, along with a modified process for discretizing the search network's \textit{zero} operations that allows these operations to be retained in the final evaluation networks. We pair the results of these changes with ablation studies on ICDARTS' algorithm and network template. Finally, we explore methods for expanding the search space of ICDARTS by expanding its operation set and exploring alternate methods for discretizing its continuous search cells. These experiments resulted in networks with improved generalizability and the implementation of a novel method for incorporating a dynamic search space into ICDARTS.
Fast, Simple Calcium Imaging Segmentation with Fully Convolutional Networks
Jul 19, 2017
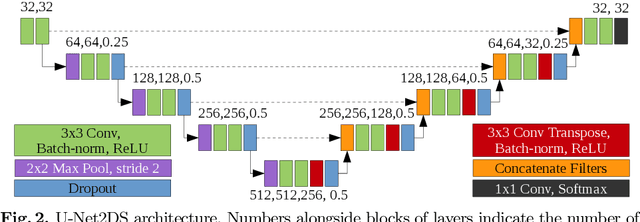

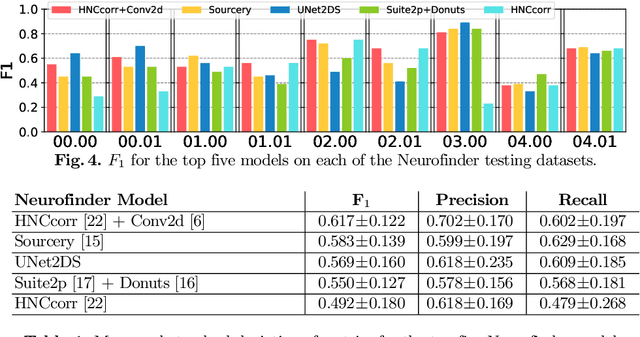
Calcium imaging is a technique for observing neuron activity as a series of images showing indicator fluorescence over time. Manually segmenting neurons is time-consuming, leading to research on automated calcium imaging segmentation (ACIS). We evaluated several deep learning models for ACIS on the Neurofinder competition datasets and report our best model: U-Net2DS, a fully convolutional network that operates on 2D mean summary images. U-Net2DS requires minimal domain-specific pre/post-processing and parameter adjustment, and predictions are made on full $512\times512$ images at $\approx$9K images per minute. It ranks third in the Neurofinder competition ($F_1=0.569$) and is the best model to exclusively use deep learning. We also demonstrate useful segmentations on data from outside the competition. The model's simplicity, speed, and quality results make it a practical choice for ACIS and a strong baseline for more complex models in the future.
Gradient Driven Learning for Pooling in Visual Pipeline Feature Extraction Models
Jan 16, 2013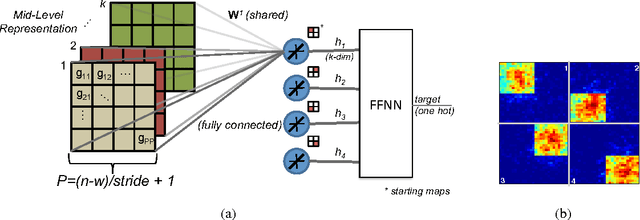
Hyper-parameter selection remains a daunting task when building a pattern recognition architecture which performs well, particularly in recently constructed visual pipeline models for feature extraction. We re-formulate pooling in an existing pipeline as a function of adjustable pooling map weight parameters and propose the use of supervised error signals from gradient descent to tune the established maps within the model. This technique allows us to learn what would otherwise be a design choice within the model and specialize the maps to aggregate areas of invariance for the task presented. Preliminary results show moderate potential gains in classification accuracy and highlight areas of importance within the intermediate feature representation space.