 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLow-Rank Approximations for Conditional Feedforward Computation in Deep Neural Networks
Paper and Code
Jan 28, 2014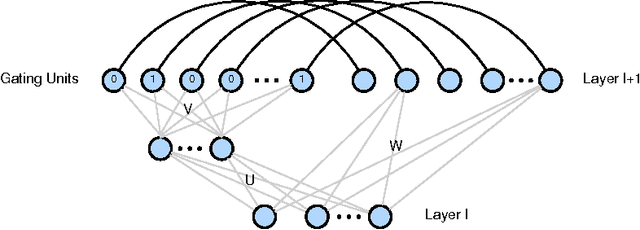
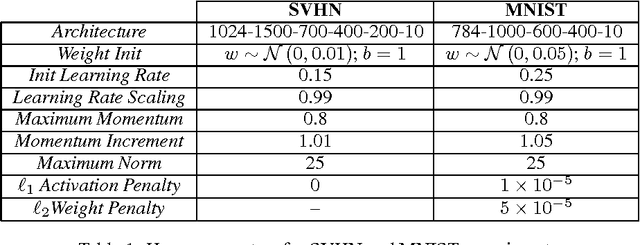
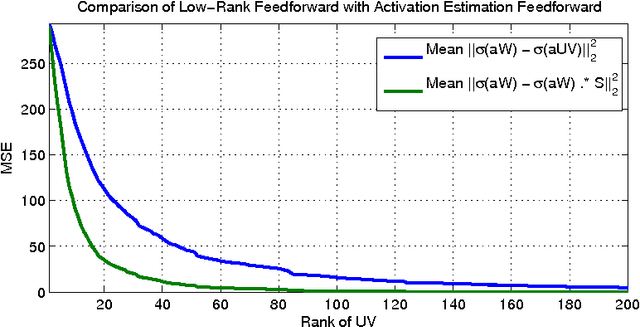
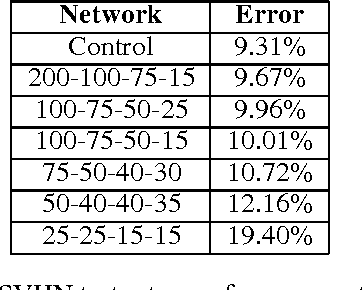
Scalability properties of deep neural networks raise key research questions, particularly as the problems considered become larger and more challenging. This paper expands on the idea of conditional computation introduced by Bengio, et. al., where the nodes of a deep network are augmented by a set of gating units that determine when a node should be calculated. By factorizing the weight matrix into a low-rank approximation, an estimation of the sign of the pre-nonlinearity activation can be efficiently obtained. For networks using rectified-linear hidden units, this implies that the computation of a hidden unit with an estimated negative pre-nonlinearity can be ommitted altogether, as its value will become zero when nonlinearity is applied. For sparse neural networks, this can result in considerable speed gains. Experimental results using the MNIST and SVHN data sets with a fully-connected deep neural network demonstrate the performance robustness of the proposed scheme with respect to the error introduced by the conditional computation process.