 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeUnsupervised Identification of Study Descriptors in Toxicology Research: An Experimental Study
Paper and Code

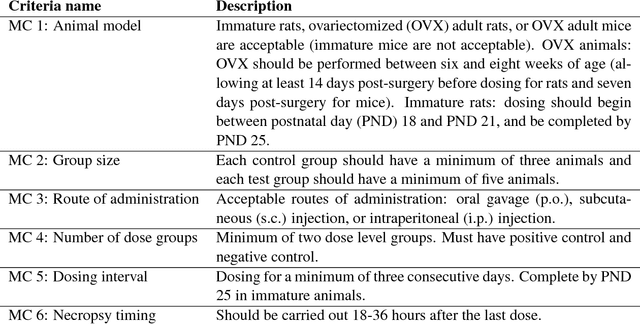
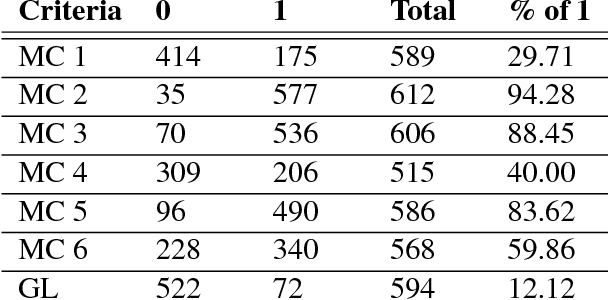
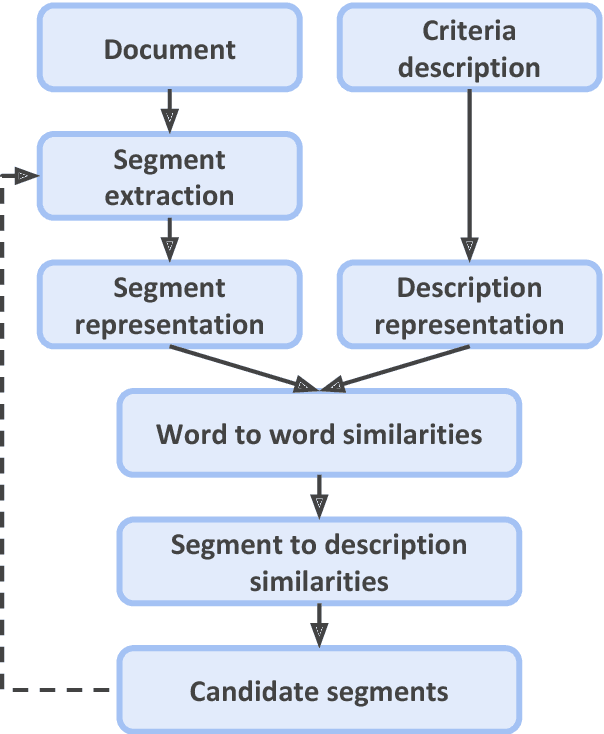
Identifying and extracting data elements such as study descriptors in publication full texts is a critical yet manual and labor-intensive step required in a number of tasks. In this paper we address the question of identifying data elements in an unsupervised manner. Specifically, provided a set of criteria describing specific study parameters, such as species, route of administration, and dosing regimen, we develop an unsupervised approach to identify text segments (sentences) relevant to the criteria. A binary classifier trained to identify publications that met the criteria performs better when trained on the candidate sentences than when trained on sentences randomly picked from the text, supporting the intuition that our method is able to accurately identify study descriptors.