 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEvent Classification with Multi-step Machine Learning
Jun 04, 2021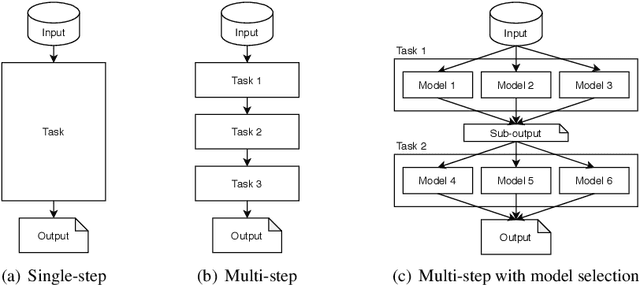
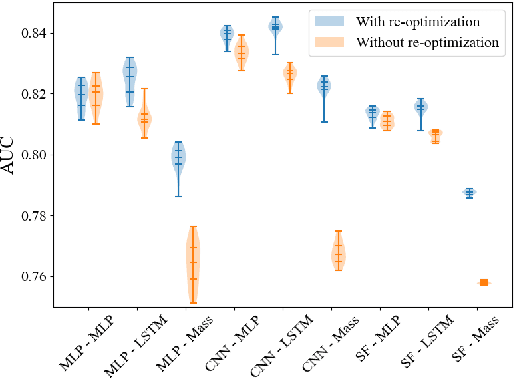

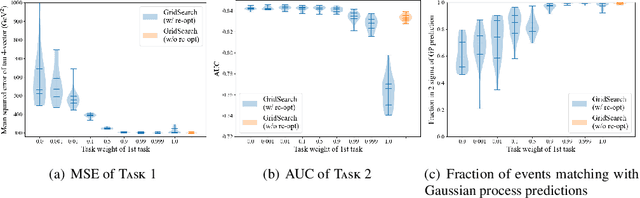
The usefulness and value of Multi-step Machine Learning (ML), where a task is organized into connected sub-tasks with known intermediate inference goals, as opposed to a single large model learned end-to-end without intermediate sub-tasks, is presented. Pre-optimized ML models are connected and better performance is obtained by re-optimizing the connected one. The selection of an ML model from several small ML model candidates for each sub-task has been performed by using the idea based on Neural Architecture Search (NAS). In this paper, Differentiable Architecture Search (DARTS) and Single Path One-Shot NAS (SPOS-NAS) are tested, where the construction of loss functions is improved to keep all ML models smoothly learning. Using DARTS and SPOS-NAS as an optimization and selection as well as the connections for multi-step machine learning systems, we find that (1) such a system can quickly and successfully select highly performant model combinations, and (2) the selected models are consistent with baseline algorithms, such as grid search, and their outputs are well controlled.
An Improvement of Object Detection Performance using Multi-step Machine Learnings
Jan 19, 2021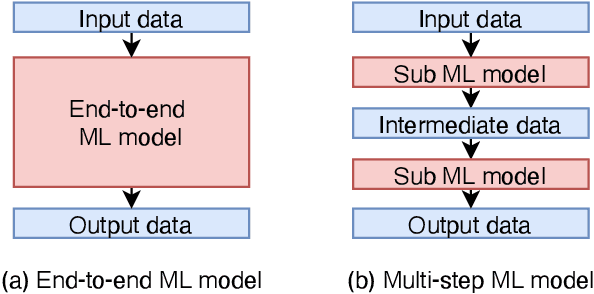


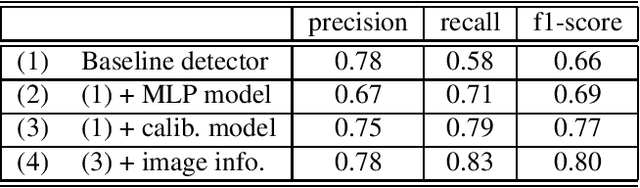
Connecting multiple machine learning models into a pipeline is effective for handling complex problems. By breaking down the problem into steps, each tackled by a specific component model of the pipeline, the overall solution can be made accurate and explainable. This paper describes an enhancement of object detection based on this multi-step concept, where a post-processing step called the calibration model is introduced. The calibration model consists of a convolutional neural network, and utilizes rich contextual information based on the domain knowledge of the input. Improvements of object detection performance by 0.8-1.9 in average precision metric over existing object detectors have been observed using the new model.
Fast convolutional neural networks on FPGAs with hls4ml
Jan 13, 2021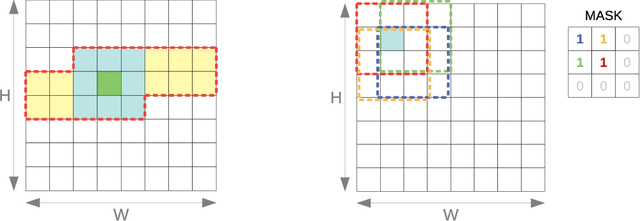
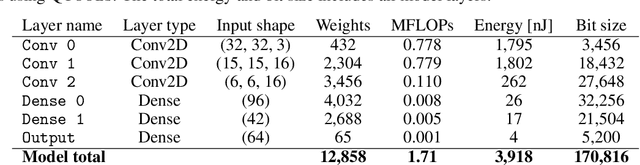
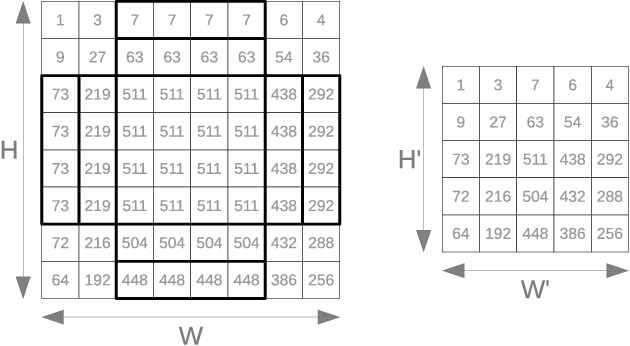

We introduce an automated tool for deploying ultra low-latency, low-power deep neural networks with large convolutional layers on FPGAs. By extending the hls4ml library, we demonstrate how to achieve inference latency of $5\,\mu$s using convolutional architectures, while preserving state-of-the-art model performance. Considering benchmark models trained on the Street View House Numbers Dataset, we demonstrate various methods for model compression in order to fit the computational constraints of a typical FPGA device. In particular, we discuss pruning and quantization-aware training, and demonstrate how resource utilization can be reduced by over 90% while maintaining the original model accuracy.
Distance-Weighted Graph Neural Networks on FPGAs for Real-Time Particle Reconstruction in High Energy Physics
Aug 08, 2020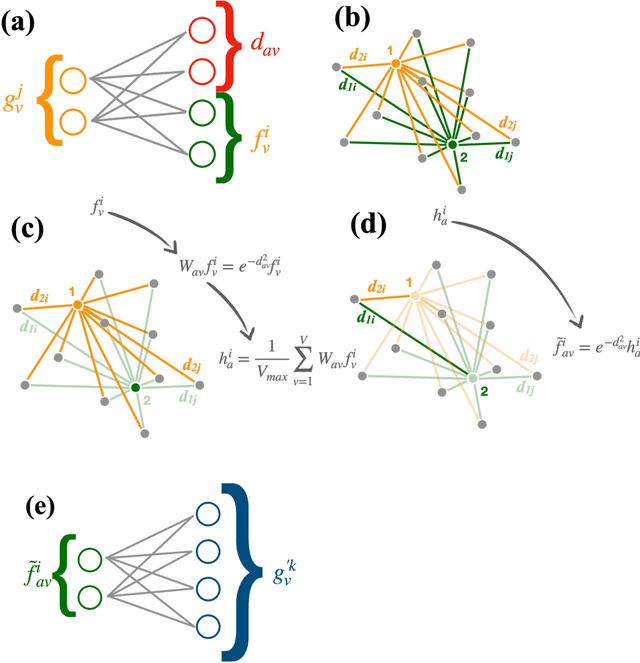


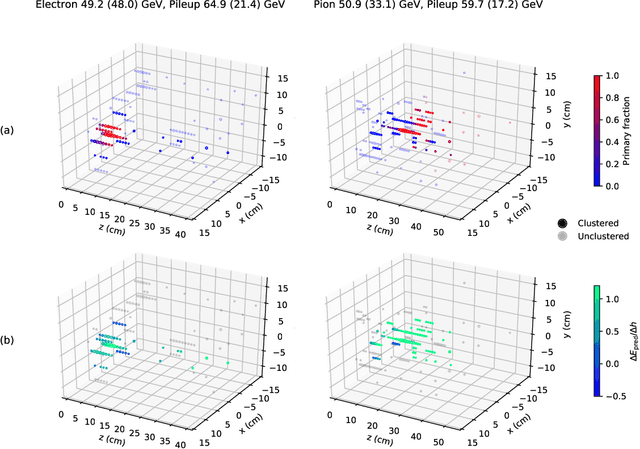
Graph neural networks have been shown to achieve excellent performance for several crucial tasks in particle physics, such as charged particle tracking, jet tagging, and clustering. An important domain for the application of these networks is the FGPA-based first layer of real-time data filtering at the CERN Large Hadron Collider, which has strict latency and resource constraints. We discuss how to design distance-weighted graph networks that can be executed with a latency of less than 1$\mu\mathrm{s}$ on an FPGA. To do so, we consider a representative task associated to particle reconstruction and identification in a next-generation calorimeter operating at a particle collider. We use a graph network architecture developed for such purposes, and apply additional simplifications to match the computing constraints of Level-1 trigger systems, including weight quantization. Using the $\mathtt{hls4ml}$ library, we convert the compressed models into firmware to be implemented on an FPGA. Performance of the synthesized models is presented both in terms of inference accuracy and resource usage.
Learning representations of irregular particle-detector geometry with distance-weighted graph networks
Feb 21, 2019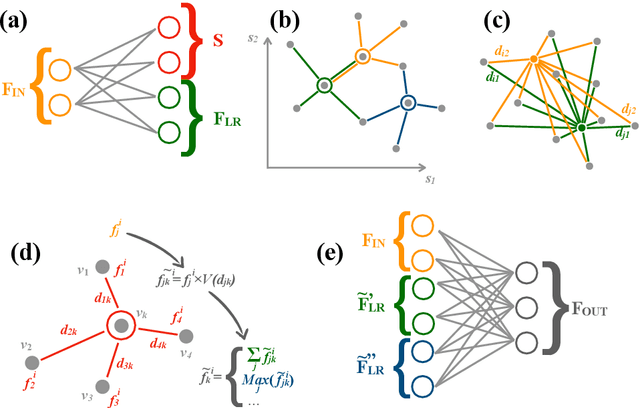

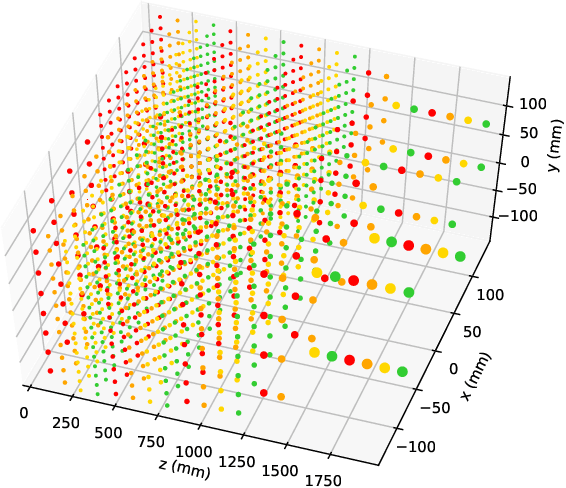
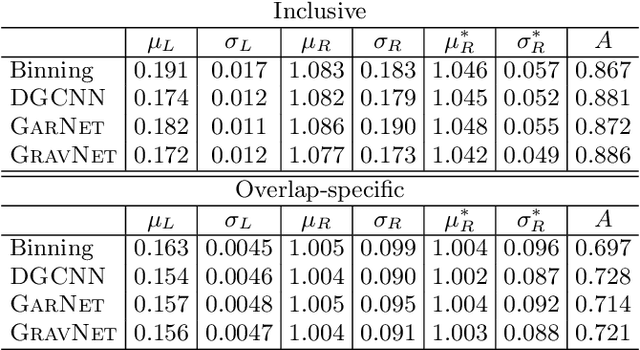
We explore the use of graph networks to deal with irregular-geometry detectors in the context of particle reconstruction. Thanks to their representation-learning capabilities, graph networks can exploit the full detector granularity, while natively managing the event sparsity and arbitrarily complex detector geometries. We introduce two distance-weighted graph network architectures, dubbed GarNet and GravNet layers, and apply them to a typical particle reconstruction task. The performance of the new architectures is evaluated on a data set of simulated particle interactions on a toy model of a highly granular calorimeter, loosely inspired by the endcap calorimeter to be installed in the CMS detector for the High-Luminosity LHC phase. We study the clustering of energy depositions, which is the basis for calorimetric particle reconstruction, and provide a quantitative comparison to alternative approaches. The proposed algorithms outperform existing methods or reach competitive performance with lower computing-resource consumption. Being geometry-agnostic, the new architectures are not restricted to calorimetry and can be easily adapted to other use cases, such as tracking in silicon detectors.