 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCLIPVehicle: A Unified Framework for Vision-based Vehicle Search
Aug 06, 2025



Vehicles, as one of the most common and significant objects in the real world, the researches on which using computer vision technologies have made remarkable progress, such as vehicle detection, vehicle re-identification, etc. To search an interested vehicle from the surveillance videos, existing methods first pre-detect and store all vehicle patches, and then apply vehicle re-identification models, which is resource-intensive and not very practical. In this work, we aim to achieve the joint detection and re-identification for vehicle search. However, the conflicting objectives between detection that focuses on shared vehicle commonness and re-identification that focuses on individual vehicle uniqueness make it challenging for a model to learn in an end-to-end system. For this problem, we propose a new unified framework, namely CLIPVehicle, which contains a dual-granularity semantic-region alignment module to leverage the VLMs (Vision-Language Models) for vehicle discrimination modeling, and a multi-level vehicle identification learning strategy to learn the identity representation from global, instance and feature levels. We also construct a new benchmark, including a real-world dataset CityFlowVS, and two synthetic datasets SynVS-Day and SynVS-All, for vehicle search. Extensive experimental results demonstrate that our method outperforms the state-of-the-art methods of both vehicle Re-ID and person search tasks.
From Synthetic to Real: Unveiling the Power of Synthetic Data for Video Person Re-ID
Feb 03, 2024
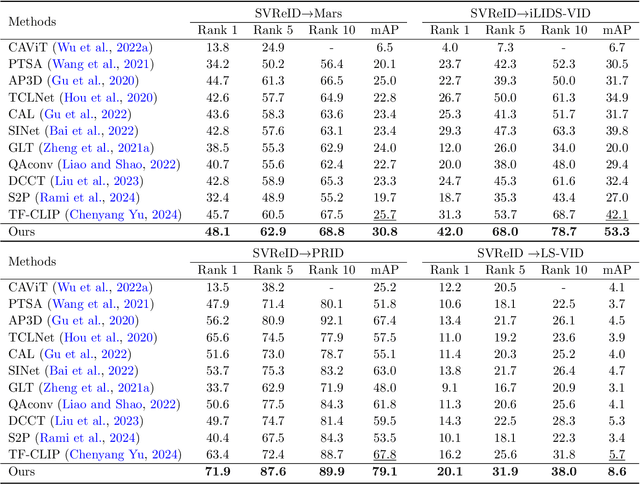
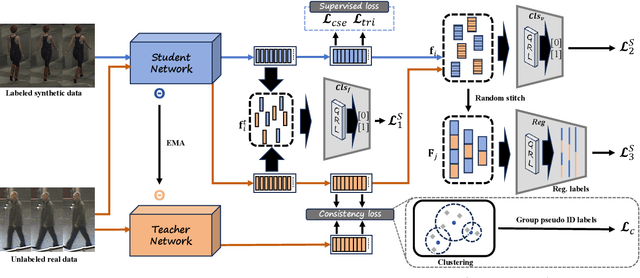
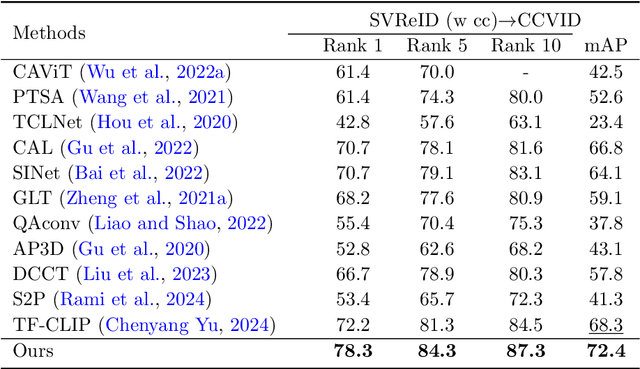
In this paper, we study a new problem of cross-domain video based person re-identification (Re-ID). Specifically, we take the synthetic video dataset as the source domain for training and use the real-world videos for testing, which significantly reduces the dependence on real training data collection and annotation. To unveil the power of synthetic data for video person Re-ID, we first propose a self-supervised domain invariant feature learning strategy for both static and temporal features. Then, to further improve the person identification ability in the target domain, we develop a mean-teacher scheme with the self-supervised ID consistency loss. Experimental results on four real datasets verify the rationality of cross-synthetic-real domain adaption and the effectiveness of our method. We are also surprised to find that the synthetic data performs even better than the real data in the cross-domain setting.
A Benchmark of Video-Based Clothes-Changing Person Re-Identification
Nov 21, 2022



Person re-identification (Re-ID) is a classical computer vision task and has achieved great progress so far. Recently, long-term Re-ID with clothes-changing has attracted increasing attention. However, existing methods mainly focus on image-based setting, where richer temporal information is overlooked. In this paper, we focus on the relatively new yet practical problem of clothes-changing video-based person re-identification (CCVReID), which is less studied. We systematically study this problem by simultaneously considering the challenge of the clothes inconsistency issue and the temporal information contained in the video sequence for the person Re-ID problem. Based on this, we develop a two-branch confidence-aware re-ranking framework for handling the CCVReID problem. The proposed framework integrates two branches that consider both the classical appearance features and cloth-free gait features through a confidence-guided re-ranking strategy. This method provides the baseline method for further studies. Also, we build two new benchmark datasets for CCVReID problem, including a large-scale synthetic video dataset and a real-world one, both containing human sequences with various clothing changes. We will release the benchmark and code in this work to the public.