 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEmbodiedBrain: Expanding Performance Boundaries of Task Planning for Embodied Intelligence
Oct 23, 2025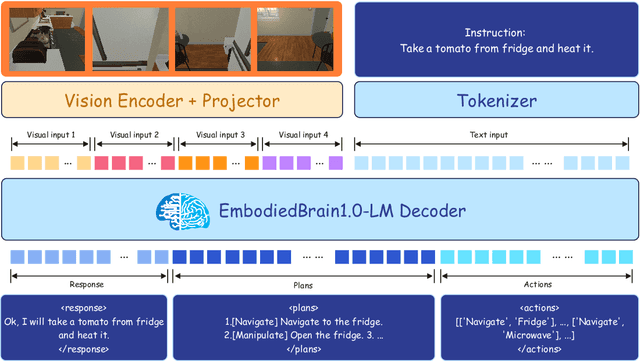
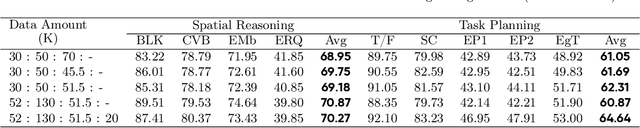

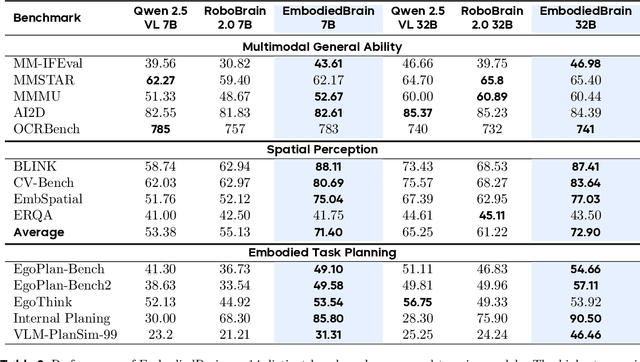
The realization of Artificial General Intelligence (AGI) necessitates Embodied AI agents capable of robust spatial perception, effective task planning, and adaptive execution in physical environments. However, current large language models (LLMs) and multimodal LLMs (MLLMs) for embodied tasks suffer from key limitations, including a significant gap between model design and agent requirements, an unavoidable trade-off between real-time latency and performance, and the use of unauthentic, offline evaluation metrics. To address these challenges, we propose EmbodiedBrain, a novel vision-language foundation model available in both 7B and 32B parameter sizes. Our framework features an agent-aligned data structure and employs a powerful training methodology that integrates large-scale Supervised Fine-Tuning (SFT) with Step-Augumented Group Relative Policy Optimization (Step-GRPO), which boosts long-horizon task success by integrating preceding steps as Guided Precursors. Furthermore, we incorporate a comprehensive reward system, including a Generative Reward Model (GRM) accelerated at the infrastructure level, to improve training efficiency. For enable thorough validation, we establish a three-part evaluation system encompassing General, Planning, and End-to-End Simulation Benchmarks, highlighted by the proposal and open-sourcing of a novel, challenging simulation environment. Experimental results demonstrate that EmbodiedBrain achieves superior performance across all metrics, establishing a new state-of-the-art for embodied foundation models. Towards paving the way for the next generation of generalist embodied agents, we open-source all of our data, model weight, and evaluating methods, which are available at https://zterobot.github.io/EmbodiedBrain.github.io.
Unveiling the Power of Self-supervision for Multi-view Multi-human Association and Tracking
Jan 31, 2024Multi-view multi-human association and tracking (MvMHAT), is a new but important problem for multi-person scene video surveillance, aiming to track a group of people over time in each view, as well as to identify the same person across different views at the same time, which is different from previous MOT and multi-camera MOT tasks only considering the over-time human tracking. This way, the videos for MvMHAT require more complex annotations while containing more information for self learning. In this work, we tackle this problem with a self-supervised learning aware end-to-end network. Specifically, we propose to take advantage of the spatial-temporal self-consistency rationale by considering three properties of reflexivity, symmetry and transitivity. Besides the reflexivity property that naturally holds, we design the self-supervised learning losses based on the properties of symmetry and transitivity, for both appearance feature learning and assignment matrix optimization, to associate the multiple humans over time and across views. Furthermore, to promote the research on MvMHAT, we build two new large-scale benchmarks for the network training and testing of different algorithms. Extensive experiments on the proposed benchmarks verify the effectiveness of our method. We have released the benchmark and code to the public.
From a Bird's Eye View to See: Joint Camera and Subject Registration without the Camera Calibration
Dec 19, 2022



We tackle a new problem of multi-view camera and subject registration in the bird's eye view (BEV) without pre-given camera calibration. This is a very challenging problem since its only input is several RGB images from different first-person views (FPVs) for a multi-person scene, without the BEV image and the calibration of the FPVs, while the output is a unified plane with the localization and orientation of both the subjects and cameras in a BEV. We propose an end-to-end framework solving this problem, whose main idea can be divided into following parts: i) creating a view-transform subject detection module to transform the FPV to a virtual BEV including localization and orientation of each pedestrian, ii) deriving a geometric transformation based method to estimate camera localization and view direction, i.e., the camera registration in a unified BEV, iii) making use of spatial and appearance information to aggregate the subjects into the unified BEV. We collect a new large-scale synthetic dataset with rich annotations for evaluation. The experimental results show the remarkable effectiveness of our proposed method.
Towards Toxic and Narcotic Medication Detection with Rotated Object Detector
Oct 19, 2021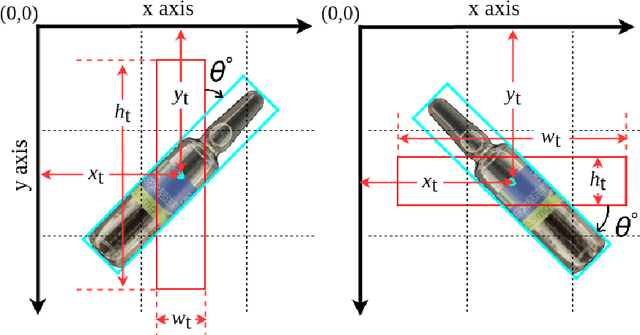

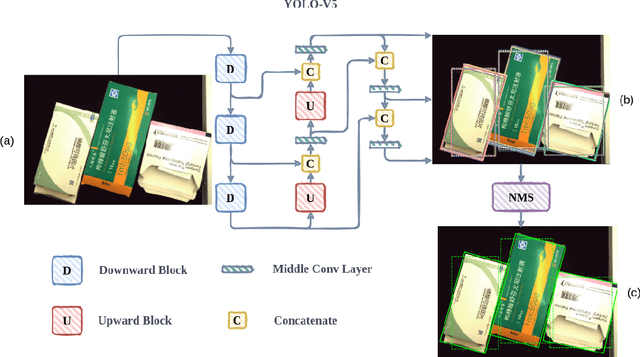
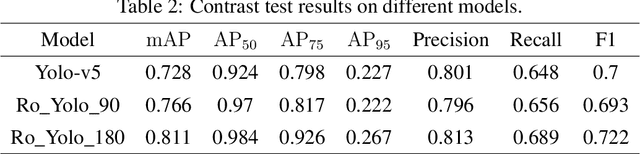
Recent years have witnessed the advancement of deep learning vision technologies and applications in the medical industry. Intelligent devices for special medication management are in great need of, which requires more precise detection algorithms to identify the specifications and locations. In this work, YOLO (You only look once) based object detectors are tailored for toxic and narcotic medications detection tasks. Specifically, a more flexible annotation with rotated degree ranging from $0^\circ$ to $90^\circ$ and a mask-mapping-based non-maximum suppression method are proposed to achieve a feasible and efficient medication detector aiming at arbitrarily oriented bounding boxes. Extensive experiments demonstrate that the rotated YOLO detectors are more suitable for identifying densely arranged drugs. The best shot mean average precision of the proposed network reaches 0.811 while the inference time is less than 300ms.
Neural Architecture Search for Gliomas Segmentation on Multimodal Magnetic Resonance Imaging
May 20, 2020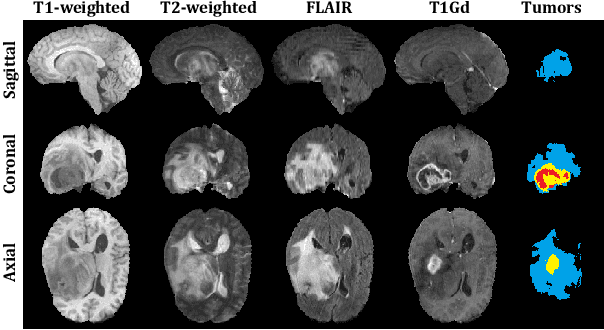

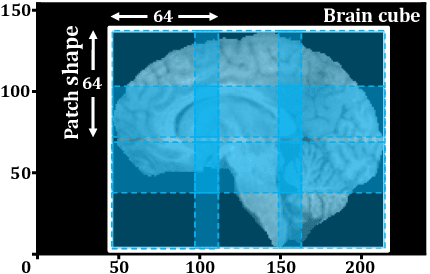

Past few years have witnessed the artificial intelligence inspired evolution in various medical fields. The diagnosis and treatment of gliomas -- one of the most commonly seen brain tumors with low survival rate -- rely heavily on the computer assisted segmentation process undertaken on the magnetic resonance imaging (MRI) scans. Although the encoder-decoder shaped deep learning networks have been the de facto standard style for semantic segmentation tasks in medical imaging analysis, enormous effort is still required to be spent on designing the detailed architecture of the down-sampling and up-sampling blocks. In this work, we propose a neural architecture search (NAS) based solution to brain tumor segmentation tasks on multimodal volumetric MRI scans. Three sets of candidate operations are composed respectively for three kinds of basic building blocks in which each operation is assigned with a specific probabilistic parameter to be learned. Through alternately updating the weights of operations and the other parameters in the network, the searching mechanism ends up with two optimal structures for the upward and downward blocks. Moreover, the developed solution also integrates normalization and patching strategies tailored for brain MRI processing. Extensive comparative experiments on the BraTS 2019 dataset demonstrate that the proposed algorithm not only could relieve the pressure of fabricating block architectures but also possesses competitive feasibility and scalability.
Brain-wise Tumor Segmentation and Patient Overall Survival Prediction
Sep 15, 2019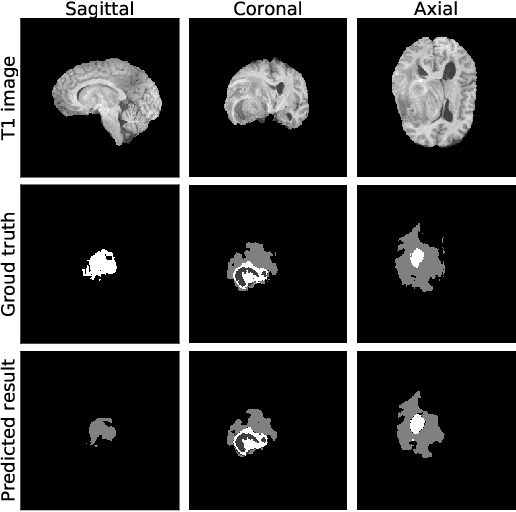


Past few years have witnessed the prevalence of deep learning in many application scenarios, among which is medical image processing. Diagnosis and treatment of brain tumors require a delicate segmentation of brain tumors as a prerequisite. However, such kind of work conventionally costs cerebral surgeons a lot of precious time. Computer vision techniques could provide surgeons a relief from the tedious marking procedure. In this paper, a 3D U-net based deep learning model has been trained with the help of brain-wise normalization and patching strategies for the brain tumor segmentation task in BraTS 2019 competition. Dice coefficients for enhancing tumor, tumor core, and the whole tumor are 0.737, 0.807 and 0.894 respectively on validation dataset. Furthermore, numerical features extracted from predicted tumor labels have been used for the overall survival days prediction task. The prediction accuracy on validation dataset is 0.448.