 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOVT-B: A New Large-Scale Benchmark for Open-Vocabulary Multi-Object Tracking
Oct 23, 2024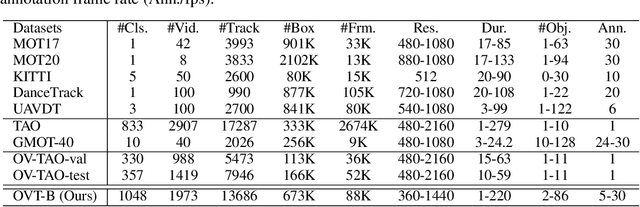



Open-vocabulary object perception has become an important topic in artificial intelligence, which aims to identify objects with novel classes that have not been seen during training. Under this setting, open-vocabulary object detection (OVD) in a single image has been studied in many literature. However, open-vocabulary object tracking (OVT) from a video has been studied less, and one reason is the shortage of benchmarks. In this work, we have built a new large-scale benchmark for open-vocabulary multi-object tracking namely OVT-B. OVT-B contains 1,048 categories of objects and 1,973 videos with 637,608 bounding box annotations, which is much larger than the sole open-vocabulary tracking dataset, i.e., OVTAO-val dataset (200+ categories, 900+ videos). The proposed OVT-B can be used as a new benchmark to pave the way for OVT research. We also develop a simple yet effective baseline method for OVT. It integrates the motion features for object tracking, which is an important feature for MOT but is ignored in previous OVT methods. Experimental results have verified the usefulness of the proposed benchmark and the effectiveness of our method. We have released the benchmark to the public at https://github.com/Coo1Sea/OVT-B-Dataset.