 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMeshMimic: Geometry-Aware Humanoid Motion Learning through 3D Scene Reconstruction
Feb 17, 2026Humanoid motion control has witnessed significant breakthroughs in recent years, with deep reinforcement learning (RL) emerging as a primary catalyst for achieving complex, human-like behaviors. However, the high dimensionality and intricate dynamics of humanoid robots make manual motion design impractical, leading to a heavy reliance on expensive motion capture (MoCap) data. These datasets are not only costly to acquire but also frequently lack the necessary geometric context of the surrounding physical environment. Consequently, existing motion synthesis frameworks often suffer from a decoupling of motion and scene, resulting in physical inconsistencies such as contact slippage or mesh penetration during terrain-aware tasks. In this work, we present MeshMimic, an innovative framework that bridges 3D scene reconstruction and embodied intelligence to enable humanoid robots to learn coupled "motion-terrain" interactions directly from video. By leveraging state-of-the-art 3D vision models, our framework precisely segments and reconstructs both human trajectories and the underlying 3D geometry of terrains and objects. We introduce an optimization algorithm based on kinematic consistency to extract high-quality motion data from noisy visual reconstructions, alongside a contact-invariant retargeting method that transfers human-environment interaction features to the humanoid agent. Experimental results demonstrate that MeshMimic achieves robust, highly dynamic performance across diverse and challenging terrains. Our approach proves that a low-cost pipeline utilizing only consumer-grade monocular sensors can facilitate the training of complex physical interactions, offering a scalable path toward the autonomous evolution of humanoid robots in unstructured environments.
RoboStriker: Hierarchical Decision-Making for Autonomous Humanoid Boxing
Jan 30, 2026Achieving human-level competitive intelligence and physical agility in humanoid robots remains a major challenge, particularly in contact-rich and highly dynamic tasks such as boxing. While Multi-Agent Reinforcement Learning (MARL) offers a principled framework for strategic interaction, its direct application to humanoid control is hindered by high-dimensional contact dynamics and the absence of strong physical motion priors. We propose RoboStriker, a hierarchical three-stage framework that enables fully autonomous humanoid boxing by decoupling high-level strategic reasoning from low-level physical execution. The framework first learns a comprehensive repertoire of boxing skills by training a single-agent motion tracker on human motion capture data. These skills are subsequently distilled into a structured latent manifold, regularized by projecting the Gaussian-parameterized distribution onto a unit hypersphere. This topological constraint effectively confines exploration to the subspace of physically plausible motions. In the final stage, we introduce Latent-Space Neural Fictitious Self-Play (LS-NFSP), where competing agents learn competitive tactics by interacting within the latent action space rather than the raw motor space, significantly stabilizing multi-agent training. Experimental results demonstrate that RoboStriker achieves superior competitive performance in simulation and exhibits sim-to-real transfer. Our website is available at RoboStriker.
Unveiling the Impact of Data and Model Scaling on High-Level Control for Humanoid Robots
Nov 12, 2025
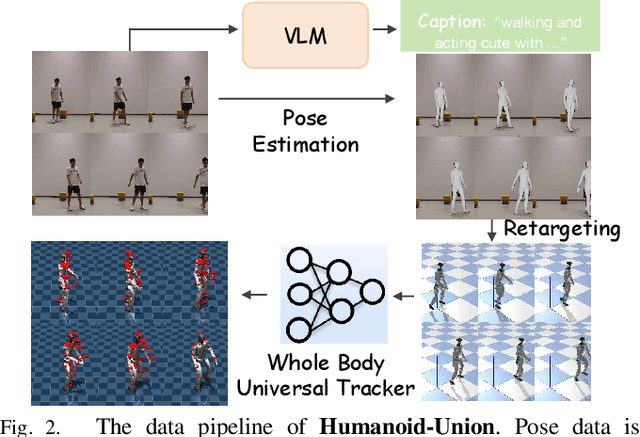
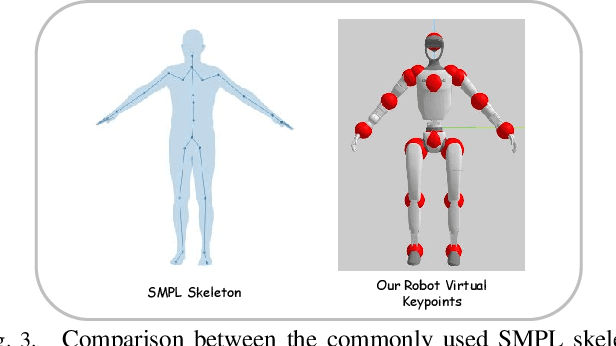
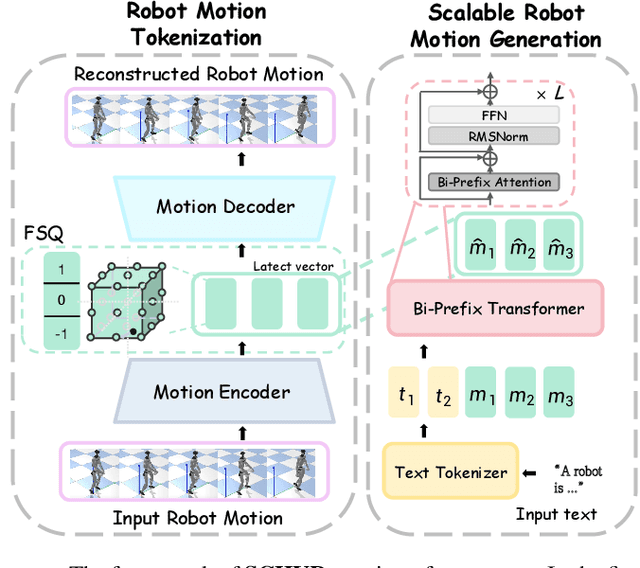
Data scaling has long remained a critical bottleneck in robot learning. For humanoid robots, human videos and motion data are abundant and widely available, offering a free and large-scale data source. Besides, the semantics related to the motions enable modality alignment and high-level robot control learning. However, how to effectively mine raw video, extract robot-learnable representations, and leverage them for scalable learning remains an open problem. To address this, we introduce Humanoid-Union, a large-scale dataset generated through an autonomous pipeline, comprising over 260 hours of diverse, high-quality humanoid robot motion data with semantic annotations derived from human motion videos. The dataset can be further expanded via the same pipeline. Building on this data resource, we propose SCHUR, a scalable learning framework designed to explore the impact of large-scale data on high-level control in humanoid robots. Experimental results demonstrate that SCHUR achieves high robot motion generation quality and strong text-motion alignment under data and model scaling, with 37\% reconstruction improvement under MPJPE and 25\% alignment improvement under FID comparing with previous methods. Its effectiveness is further validated through deployment in real-world humanoid robot.
Towards Adaptable Humanoid Control via Adaptive Motion Tracking
Oct 16, 2025Humanoid robots are envisioned to adapt demonstrated motions to diverse real-world conditions while accurately preserving motion patterns. Existing motion prior approaches enable well adaptability with a few motions but often sacrifice imitation accuracy, whereas motion-tracking methods achieve accurate imitation yet require many training motions and a test-time target motion to adapt. To combine their strengths, we introduce AdaMimic, a novel motion tracking algorithm that enables adaptable humanoid control from a single reference motion. To reduce data dependence while ensuring adaptability, our method first creates an augmented dataset by sparsifying the single reference motion into keyframes and applying light editing with minimal physical assumptions. A policy is then initialized by tracking these sparse keyframes to generate dense intermediate motions, and adapters are subsequently trained to adjust tracking speed and refine low-level actions based on the adjustment, enabling flexible time warping that further improves imitation accuracy and adaptability. We validate these significant improvements in our approach in both simulation and the real-world Unitree G1 humanoid robot in multiple tasks across a wide range of adaptation conditions. Videos and code are available at https://taohuang13.github.io/adamimic.github.io/.
UniTracker: Learning Universal Whole-Body Motion Tracker for Humanoid Robots
Jul 10, 2025Humanoid robots must achieve diverse, robust, and generalizable whole-body control to operate effectively in complex, human-centric environments. However, existing methods, particularly those based on teacher-student frameworks often suffer from a loss of motion diversity during policy distillation and exhibit limited generalization to unseen behaviors. In this work, we present UniTracker, a simplified yet powerful framework that integrates a Conditional Variational Autoencoder (CVAE) into the student policy to explicitly model the latent diversity of human motion. By leveraging a learned CVAE prior, our method enables the student to retain expressive motion characteristics while improving robustness and adaptability under partial observations. The result is a single policy capable of tracking a wide spectrum of whole-body motions with high fidelity and stability. Comprehensive experiments in both simulation and real-world deployments demonstrate that UniTracker significantly outperforms MLP-based DAgger baselines in motion quality, generalization to unseen references, and deployment robustness, offering a practical and scalable solution for expressive humanoid control.
Tri-Modal Motion Retrieval by Learning a Joint Embedding Space
Mar 01, 2024



Information retrieval is an ever-evolving and crucial research domain. The substantial demand for high-quality human motion data especially in online acquirement has led to a surge in human motion research works. Prior works have mainly concentrated on dual-modality learning, such as text and motion tasks, but three-modality learning has been rarely explored. Intuitively, an extra introduced modality can enrich a model's application scenario, and more importantly, an adequate choice of the extra modality can also act as an intermediary and enhance the alignment between the other two disparate modalities. In this work, we introduce LAVIMO (LAnguage-VIdeo-MOtion alignment), a novel framework for three-modality learning integrating human-centric videos as an additional modality, thereby effectively bridging the gap between text and motion. Moreover, our approach leverages a specially designed attention mechanism to foster enhanced alignment and synergistic effects among text, video, and motion modalities. Empirically, our results on the HumanML3D and KIT-ML datasets show that LAVIMO achieves state-of-the-art performance in various motion-related cross-modal retrieval tasks, including text-to-motion, motion-to-text, video-to-motion and motion-to-video.
NIPD: A Federated Learning Person Detection Benchmark Based on Real-World Non-IID Data
Jun 28, 2023Federated learning (FL), a privacy-preserving distributed machine learning, has been rapidly applied in wireless communication networks. FL enables Internet of Things (IoT) clients to obtain well-trained models while preventing privacy leakage. Person detection can be deployed on edge devices with limited computing power if combined with FL to process the video data directly at the edge. However, due to the different hardware and deployment scenarios of different cameras, the data collected by the camera present non-independent and identically distributed (non-IID), and the global model derived from FL aggregation is less effective. Meanwhile, existing research lacks public data set for real-world FL object detection, which is not conducive to studying the non-IID problem on IoT cameras. Therefore, we open source a non-IID IoT person detection (NIPD) data set, which is collected from five different cameras. To our knowledge, this is the first true device-based non-IID person detection data set. Based on this data set, we explain how to establish a FL experimental platform and provide a benchmark for non-IID person detection. NIPD is expected to promote the application of FL and the security of smart city.
A Multi-task Joint Framework for Real-time Person Search
Dec 11, 2020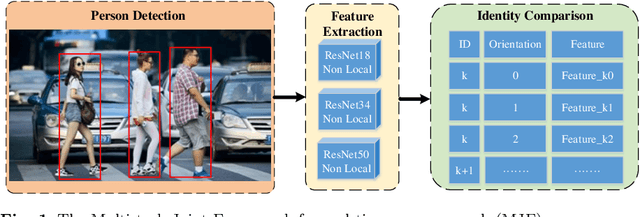
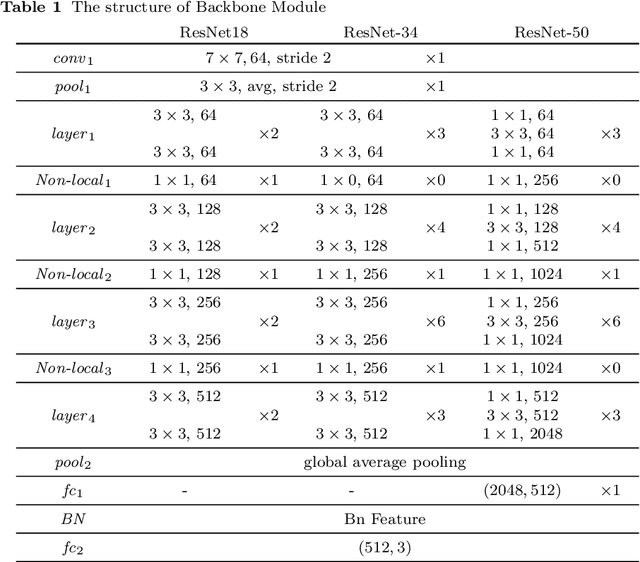
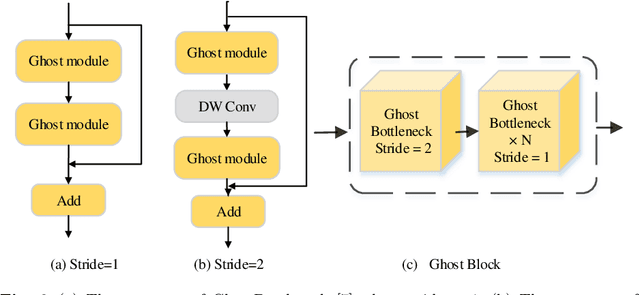

Person search generally involves three important parts: person detection, feature extraction and identity comparison. However, person search integrating detection, extraction and comparison has the following drawbacks. Firstly, the accuracy of detection will affect the accuracy of comparison. Secondly, it is difficult to achieve real-time in real-world applications. To solve these problems, we propose a Multi-task Joint Framework for real-time person search (MJF), which optimizes the person detection, feature extraction and identity comparison respectively. For the person detection module, we proposed the YOLOv5-GS model, which is trained with person dataset. It combines the advantages of the Ghostnet and the Squeeze-and-Excitation (SE) block, and improves the speed and accuracy. For the feature extraction module, we design the Model Adaptation Architecture (MAA), which could select different network according to the number of people. It could balance the relationship between accuracy and speed. For identity comparison, we propose a Three Dimension (3D) Pooled Table and a matching strategy to improve identification accuracy. On the condition of 1920*1080 resolution video and 500 IDs table, the identification rate (IR) and frames per second (FPS) achieved by our method could reach 93.6% and 25.7,