 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTempDiffReg: Temporal Diffusion Model for Non-Rigid 2D-3D Vascular Registration
Jan 26, 2026Transarterial chemoembolization (TACE) is a preferred treatment option for hepatocellular carcinoma and other liver malignancies, yet it remains a highly challenging procedure due to complex intra-operative vascular navigation and anatomical variability. Accurate and robust 2D-3D vessel registration is essential to guide microcatheter and instruments during TACE, enabling precise localization of vascular structures and optimal therapeutic targeting. To tackle this issue, we develop a coarse-to-fine registration strategy. First, we introduce a global alignment module, structure-aware perspective n-point (SA-PnP), to establish correspondence between 2D and 3D vessel structures. Second, we propose TempDiffReg, a temporal diffusion model that performs vessel deformation iteratively by leveraging temporal context to capture complex anatomical variations and local structural changes. We collected data from 23 patients and constructed 626 paired multi-frame samples for comprehensive evaluation. Experimental results demonstrate that the proposed method consistently outperforms state-of-the-art (SOTA) methods in both accuracy and anatomical plausibility. Specifically, our method achieves a mean squared error (MSE) of 0.63 mm and a mean absolute error (MAE) of 0.51 mm in registration accuracy, representing 66.7\% lower MSE and 17.7\% lower MAE compared to the most competitive existing approaches. It has the potential to assist less-experienced clinicians in safely and efficiently performing complex TACE procedures, ultimately enhancing both surgical outcomes and patient care. Code and data are available at: \textcolor{blue}{https://github.com/LZH970328/TempDiffReg.git}
Surgical Scene Segmentation using a Spike-Driven Video Transformer with Real-Time Potential
Dec 24, 2025Modern surgical systems increasingly rely on intelligent scene understanding to provide timely situational awareness for enhanced intra-operative safety. Within this pipeline, surgical scene segmentation plays a central role in accurately perceiving operative events. Although recent deep learning models, particularly large-scale foundation models, achieve remarkable segmentation accuracy, their substantial computational demands and power consumption hinder real-time deployment in resource-constrained surgical environments. To address this limitation, we explore the emerging SNN as a promising paradigm for highly efficient surgical intelligence. However, their performance is still constrained by the scarcity of labeled surgical data and the inherently sparse nature of surgical video representations. To this end, we propose \textit{SpikeSurgSeg}, the first spike-driven video Transformer framework tailored for surgical scene segmentation with real-time potential on non-GPU platforms. To address the limited availability of surgical annotations, we introduce a surgical-scene masked autoencoding pretraining strategy for SNNs that enables robust spatiotemporal representation learning via layer-wise tube masking. Building on this pretrained backbone, we further adopt a lightweight spike-driven segmentation head that produces temporally consistent predictions while preserving the low-latency characteristics of SNNs. Extensive experiments on EndoVis18 and our in-house SurgBleed dataset demonstrate that SpikeSurgSeg achieves mIoU comparable to SOTA ANN-based models while reducing inference latency by at least $8\times$. Notably, it delivers over $20\times$ acceleration relative to most foundation-model baselines, underscoring its potential for time-critical surgical scene segmentation.
Semantics-Aware Human Motion Generation from Audio Instructions
May 29, 2025Recent advances in interactive technologies have highlighted the prominence of audio signals for semantic encoding. This paper explores a new task, where audio signals are used as conditioning inputs to generate motions that align with the semantics of the audio. Unlike text-based interactions, audio provides a more natural and intuitive communication method. However, existing methods typically focus on matching motions with music or speech rhythms, which often results in a weak connection between the semantics of the audio and generated motions. We propose an end-to-end framework using a masked generative transformer, enhanced by a memory-retrieval attention module to handle sparse and lengthy audio inputs. Additionally, we enrich existing datasets by converting descriptions into conversational style and generating corresponding audio with varied speaker identities. Experiments demonstrate the effectiveness and efficiency of the proposed framework, demonstrating that audio instructions can convey semantics similar to text while providing more practical and user-friendly interactions.
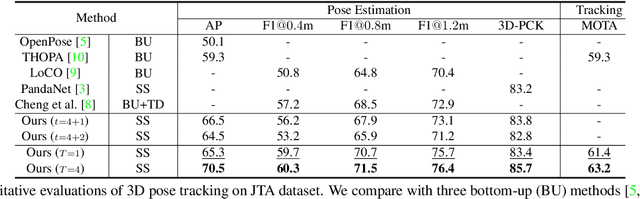
SpikeVideoFormer: An Efficient Spike-Driven Video Transformer with Hamming Attention and $\mathcal{O}(T)$ Complexity
May 15, 2025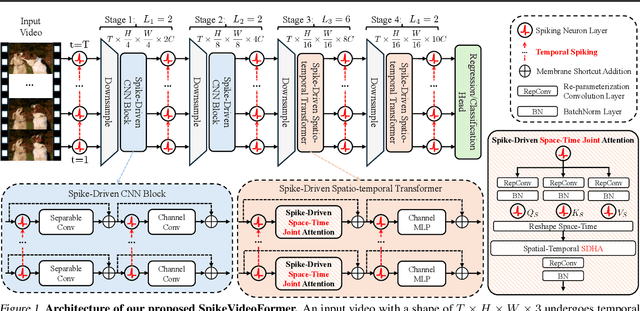
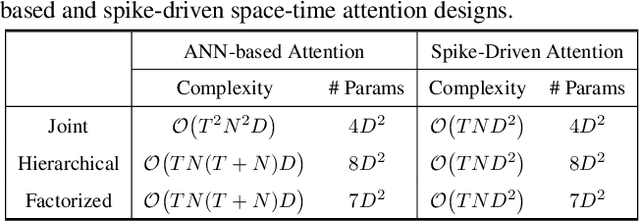

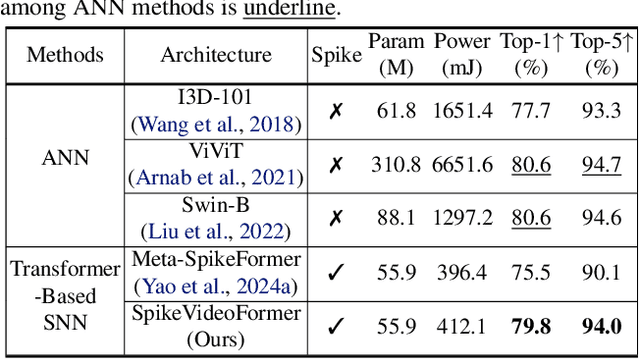
Spiking Neural Networks (SNNs) have shown competitive performance to Artificial Neural Networks (ANNs) in various vision tasks, while offering superior energy efficiency. However, existing SNN-based Transformers primarily focus on single-image tasks, emphasizing spatial features while not effectively leveraging SNNs' efficiency in video-based vision tasks. In this paper, we introduce SpikeVideoFormer, an efficient spike-driven video Transformer, featuring linear temporal complexity $\mathcal{O}(T)$. Specifically, we design a spike-driven Hamming attention (SDHA) which provides a theoretically guided adaptation from traditional real-valued attention to spike-driven attention. Building on SDHA, we further analyze various spike-driven space-time attention designs and identify an optimal scheme that delivers appealing performance for video tasks, while maintaining only linear temporal complexity. The generalization ability and efficiency of our model are demonstrated across diverse downstream video tasks, including classification, human pose tracking, and semantic segmentation. Empirical results show our method achieves state-of-the-art (SOTA) performance compared to existing SNN approaches, with over 15\% improvement on the latter two tasks. Additionally, it matches the performance of recent ANN-based methods while offering significant efficiency gains, achieving $\times 16$, $\times 10$ and $\times 5$ improvements on the three tasks. https://github.com/JimmyZou/SpikeVideoFormer
Tri-Modal Motion Retrieval by Learning a Joint Embedding Space
Mar 01, 2024



Information retrieval is an ever-evolving and crucial research domain. The substantial demand for high-quality human motion data especially in online acquirement has led to a surge in human motion research works. Prior works have mainly concentrated on dual-modality learning, such as text and motion tasks, but three-modality learning has been rarely explored. Intuitively, an extra introduced modality can enrich a model's application scenario, and more importantly, an adequate choice of the extra modality can also act as an intermediary and enhance the alignment between the other two disparate modalities. In this work, we introduce LAVIMO (LAnguage-VIdeo-MOtion alignment), a novel framework for three-modality learning integrating human-centric videos as an additional modality, thereby effectively bridging the gap between text and motion. Moreover, our approach leverages a specially designed attention mechanism to foster enhanced alignment and synergistic effects among text, video, and motion modalities. Empirically, our results on the HumanML3D and KIT-ML datasets show that LAVIMO achieves state-of-the-art performance in various motion-related cross-modal retrieval tasks, including text-to-motion, motion-to-text, video-to-motion and motion-to-video.
Multimodal Prompt Transformer with Hybrid Contrastive Learning for Emotion Recognition in Conversation
Oct 04, 2023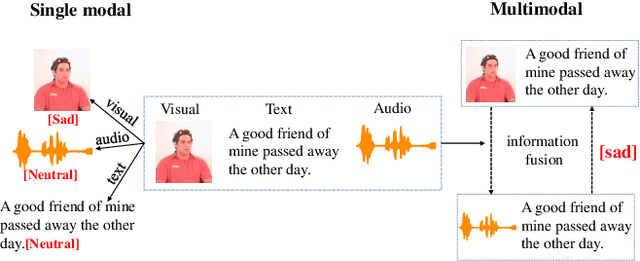
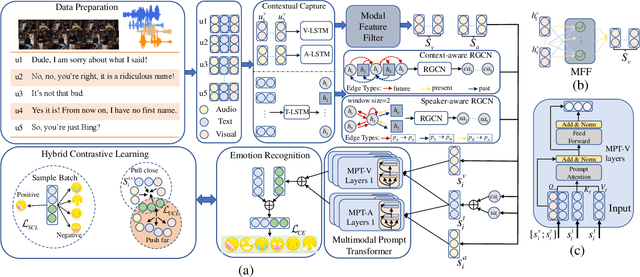

Emotion Recognition in Conversation (ERC) plays an important role in driving the development of human-machine interaction. Emotions can exist in multiple modalities, and multimodal ERC mainly faces two problems: (1) the noise problem in the cross-modal information fusion process, and (2) the prediction problem of less sample emotion labels that are semantically similar but different categories. To address these issues and fully utilize the features of each modality, we adopted the following strategies: first, deep emotion cues extraction was performed on modalities with strong representation ability, and feature filters were designed as multimodal prompt information for modalities with weak representation ability. Then, we designed a Multimodal Prompt Transformer (MPT) to perform cross-modal information fusion. MPT embeds multimodal fusion information into each attention layer of the Transformer, allowing prompt information to participate in encoding textual features and being fused with multi-level textual information to obtain better multimodal fusion features. Finally, we used the Hybrid Contrastive Learning (HCL) strategy to optimize the model's ability to handle labels with few samples. This strategy uses unsupervised contrastive learning to improve the representation ability of multimodal fusion and supervised contrastive learning to mine the information of labels with few samples. Experimental results show that our proposed model outperforms state-of-the-art models in ERC on two benchmark datasets.
Event-based Human Pose Tracking by Spiking Spatiotemporal Transformer
Mar 31, 2023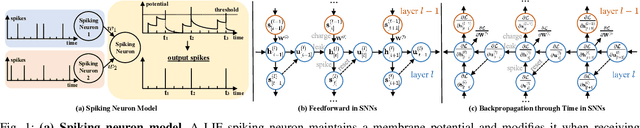
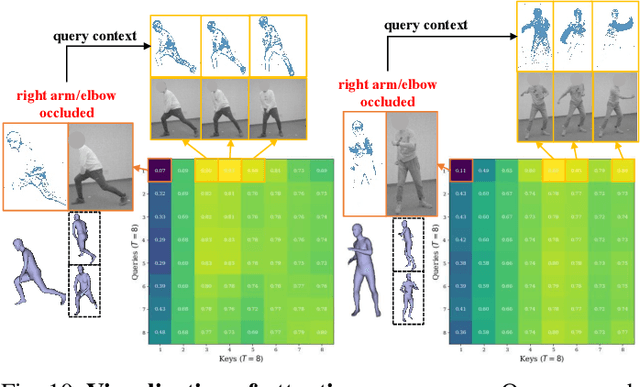
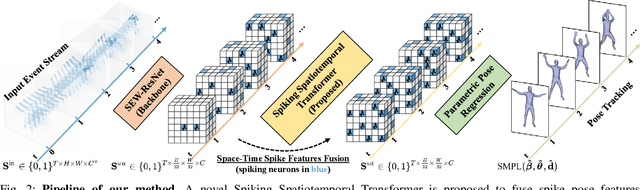
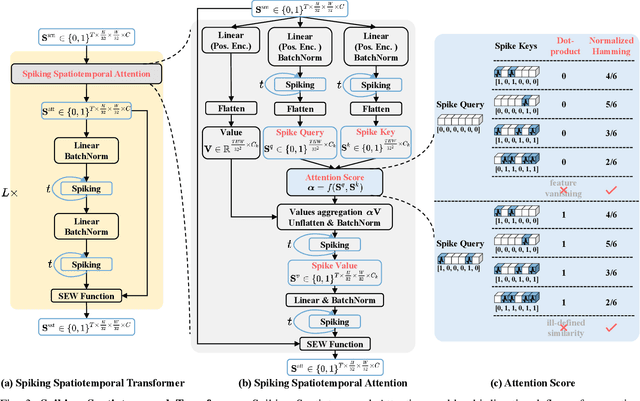
Event camera, as an emerging biologically-inspired vision sensor for capturing motion dynamics, presents new potential for 3D human pose tracking, or video-based 3D human pose estimation. However, existing works in pose tracking either require the presence of additional gray-scale images to establish a solid starting pose, or ignore the temporal dependencies all together by collapsing segments of event streams to form static event frames. Meanwhile, although the effectiveness of Artificial Neural Networks (ANNs, a.k.a. dense deep learning) has been showcased in many event-based tasks, the use of ANNs tends to neglect the fact that compared to the dense frame-based image sequences, the occurrence of events from an event camera is spatiotemporally much sparser. Motivated by the above mentioned issues, we present in this paper a dedicated end-to-end sparse deep learning approach for event-based pose tracking: 1) to our knowledge this is the first time that 3D human pose tracking is obtained from events only, thus eliminating the need of accessing to any frame-based images as part of input; 2) our approach is based entirely upon the framework of Spiking Neural Networks (SNNs), which consists of Spike-Element-Wise (SEW) ResNet and a novel Spiking Spatiotemporal Transformer; 3) a large-scale synthetic dataset is constructed that features a broad and diverse set of annotated 3D human motions, as well as longer hours of event stream data, named SynEventHPD. Empirical experiments demonstrate that, with superior performance over the state-of-the-art (SOTA) ANNs counterparts, our approach also achieves a significant computation reduction of 80% in FLOPS. Furthermore, our proposed method also outperforms SOTA SNNs in the regression task of human pose tracking. Our implementation is available at https://github.com/JimmyZou/HumanPoseTracking_SNN and dataset will be released upon paper acceptance.
Snipper: A Spatiotemporal Transformer for Simultaneous Multi-Person 3D Pose Estimation Tracking and Forecasting on a Video Snippet
Jul 13, 2022
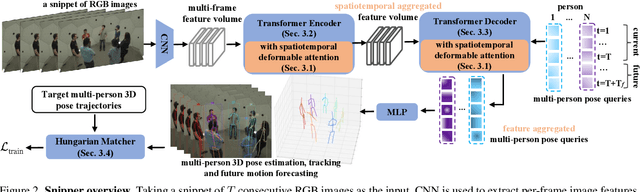
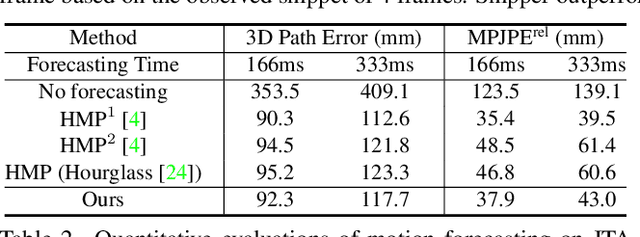
Multi-person pose understanding from RGB videos includes three complex tasks: pose estimation, tracking and motion forecasting. Among these three tasks, pose estimation and tracking are correlated, and tracking is crucial to motion forecasting. Most existing works either focus on a single task or employ cascaded methods to solve each individual task separately. In this paper, we propose Snipper, a framework to perform multi-person 3D pose estimation, tracking and motion forecasting simultaneously in a single inference. Specifically, we first propose a deformable attention mechanism to aggregate spatiotemporal information from video snippets. Building upon this deformable attention, a visual transformer is learned to encode the spatiotemporal features from multi-frame images and to decode informative pose features to update multi-person pose queries. Last, these queries are regressed to predict multi-person pose trajectories and future motions in one forward pass. In the experiments, we show the effectiveness of Snipper on three challenging public datasets where a generic model rivals specialized state-of-art baselines for pose estimation, tracking, and forecasting. Code is available at https://github.com/JimmyZou/Snipper
Action2video: Generating Videos of Human 3D Actions
Nov 12, 2021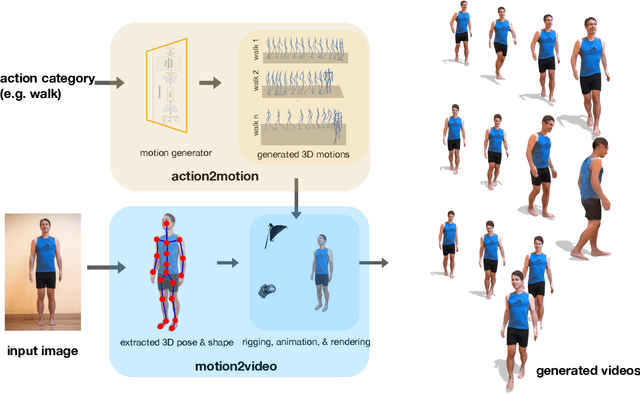
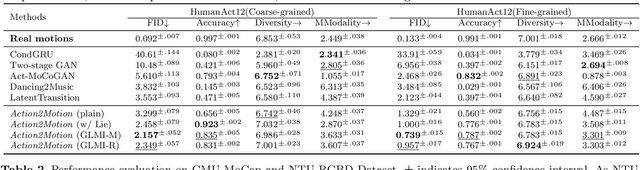
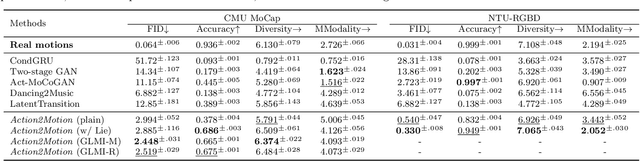
We aim to tackle the interesting yet challenging problem of generating videos of diverse and natural human motions from prescribed action categories. The key issue lies in the ability to synthesize multiple distinct motion sequences that are realistic in their visual appearances. It is achieved in this paper by a two-step process that maintains internal 3D pose and shape representations, action2motion and motion2video. Action2motion stochastically generates plausible 3D pose sequences of a prescribed action category, which are processed and rendered by motion2video to form 2D videos. Specifically, the Lie algebraic theory is engaged in representing natural human motions following the physical law of human kinematics; a temporal variational auto-encoder (VAE) is developed that encourages diversity of output motions. Moreover, given an additional input image of a clothed human character, an entire pipeline is proposed to extract his/her 3D detailed shape, and to render in videos the plausible motions from different views. This is realized by improving existing methods to extract 3D human shapes and textures from single 2D images, rigging, animating, and rendering to form 2D videos of human motions. It also necessitates the curation and reannotation of 3D human motion datasets for training purpose. Thorough empirical experiments including ablation study, qualitative and quantitative evaluations manifest the applicability of our approach, and demonstrate its competitiveness in addressing related tasks, where components of our approach are compared favorably to the state-of-the-arts.
Human Pose and Shape Estimation from Single Polarization Images
Aug 15, 2021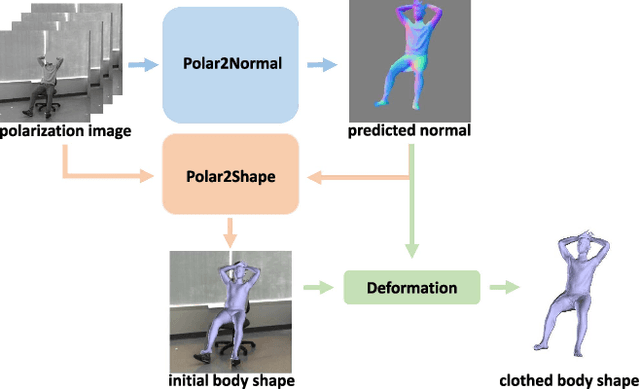
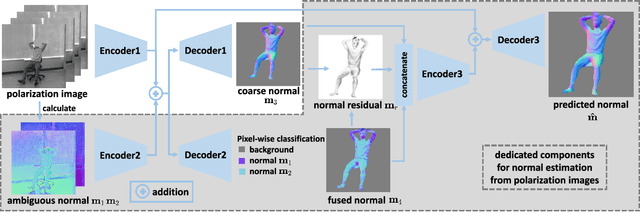
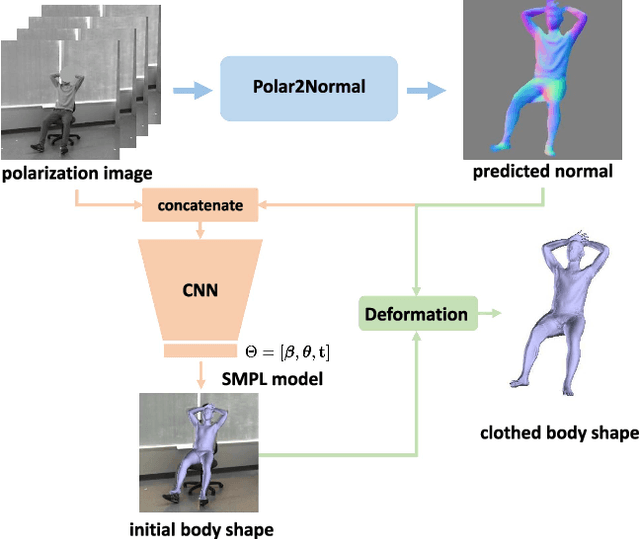
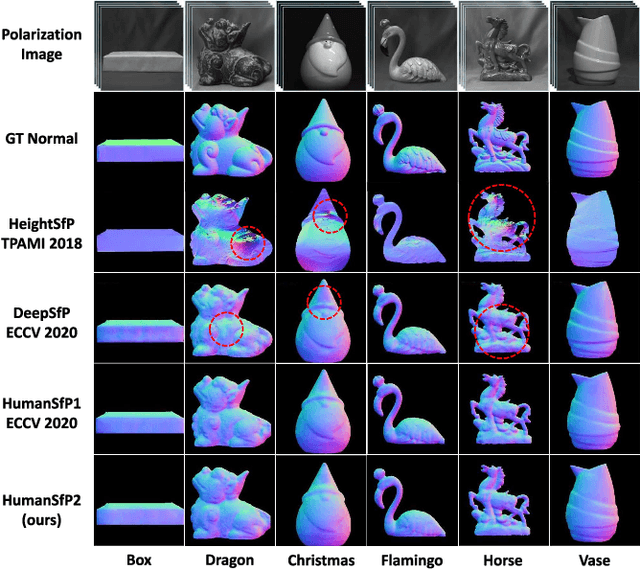
This paper focuses on a new problem of estimating human pose and shape from single polarization images. Polarization camera is known to be able to capture the polarization of reflected lights that preserves rich geometric cues of an object surface. Inspired by the recent applications in surface normal reconstruction from polarization images, in this paper, we attempt to estimate human pose and shape from single polarization images by leveraging the polarization-induced geometric cues. A dedicated two-stage pipeline is proposed: given a single polarization image, stage one (Polar2Normal) focuses on the fine detailed human body surface normal estimation; stage two (Polar2Shape) then reconstructs clothed human shape from the polarization image and the estimated surface normal. To empirically validate our approach, a dedicated dataset (PHSPD) is constructed, consisting of over 500K frames with accurate pose and shape annotations. Empirical evaluations on this real-world dataset as well as a synthetic dataset, SURREAL, demonstrate the effectiveness of our approach. It suggests polarization camera as a promising alternative to the more conventional RGB camera for human pose and shape estimation.