 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEvent-based Human Pose Tracking by Spiking Spatiotemporal Transformer
Paper and Code
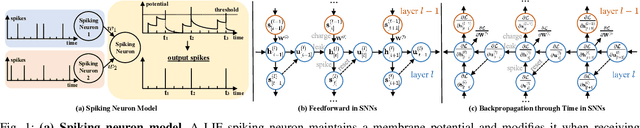
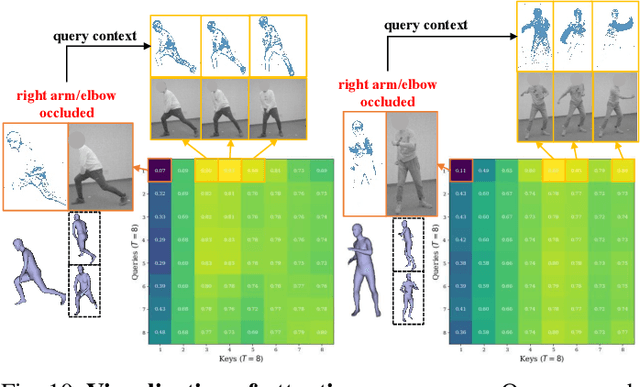
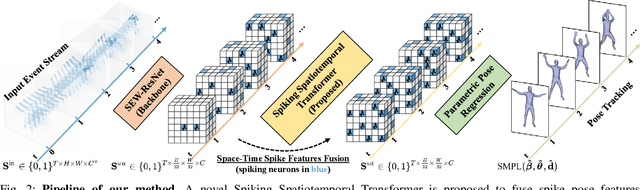
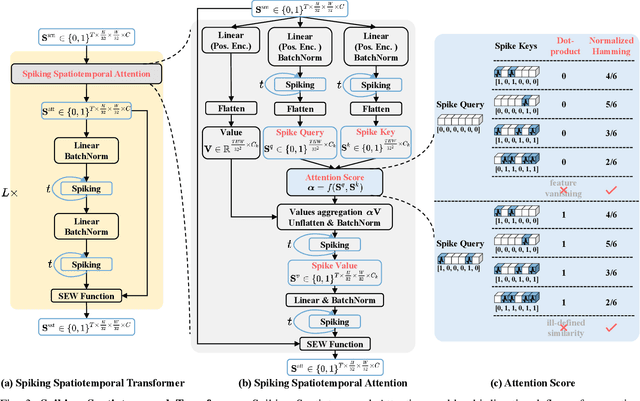
Event camera, as an emerging biologically-inspired vision sensor for capturing motion dynamics, presents new potential for 3D human pose tracking, or video-based 3D human pose estimation. However, existing works in pose tracking either require the presence of additional gray-scale images to establish a solid starting pose, or ignore the temporal dependencies all together by collapsing segments of event streams to form static event frames. Meanwhile, although the effectiveness of Artificial Neural Networks (ANNs, a.k.a. dense deep learning) has been showcased in many event-based tasks, the use of ANNs tends to neglect the fact that compared to the dense frame-based image sequences, the occurrence of events from an event camera is spatiotemporally much sparser. Motivated by the above mentioned issues, we present in this paper a dedicated end-to-end sparse deep learning approach for event-based pose tracking: 1) to our knowledge this is the first time that 3D human pose tracking is obtained from events only, thus eliminating the need of accessing to any frame-based images as part of input; 2) our approach is based entirely upon the framework of Spiking Neural Networks (SNNs), which consists of Spike-Element-Wise (SEW) ResNet and a novel Spiking Spatiotemporal Transformer; 3) a large-scale synthetic dataset is constructed that features a broad and diverse set of annotated 3D human motions, as well as longer hours of event stream data, named SynEventHPD. Empirical experiments demonstrate that, with superior performance over the state-of-the-art (SOTA) ANNs counterparts, our approach also achieves a significant computation reduction of 80% in FLOPS. Furthermore, our proposed method also outperforms SOTA SNNs in the regression task of human pose tracking. Our implementation is available at https://github.com/JimmyZou/HumanPoseTracking_SNN and dataset will be released upon paper acceptance.