 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeVoxCPM2 Technical Report
Jun 05, 2026We present VoxCPM2, a https://info.arxiv.org/help/prep#abstractsfully open-source multilingual and controllable speech generation foundation model that extends the hierarchical diffusion-autoregressive modeling paradigm of VoxCPM. VoxCPM2 advances the framework in three key dimensions: (i) capability, by unifying 30 languages, 9 Chinese dialects, natural-language voice design, style-controllable voice cloning, and high-fidelity continuation cloning within a single backbone; (ii) quality, through an asymmetric AudioVAE that encodes at 16 kHz and reconstructs at 48 kHz, enabling implicit super-resolution with high encoding efficiency; and (iii) scale, by jointly scaling the model to 2B parameters and the training data to over 2 million hours of multilingual speech. To support these diverse capabilities within one model, we introduce a unified sequence organization that expresses all generation modes through different arrangements of the same input building blocks, allowing joint training under a single set of parameters and objective. VoxCPM2 achieves state-of-the-art or competitive performance on public zero-shot and instruction-following TTS benchmarks. On our internal 30-language evaluation set, it attains an average WER of 1.68%. These results demonstrate that hierarchical continuous-latent modeling, without relying on any external discrete speech tokenizer, offers a viable and powerful foundation for large-scale multilingual and controllable speech generation. The model weights, fine-tuning code, and inference tools are publicly released under the Apache 2.0 license to foster community research and development.
PHKT:Personalized Dynamic Hypergraph-enhanced KAN-Transformer for Multi-behavior Sequential Recommendation
Jun 04, 2026In multi-behavior recommendation, auxiliary behaviors such as clicks, add-to-cart, and purchases can provide richer supervisory information for predicting target behaviors. Although existing graph and hypergraph methods are capable of modeling high-order relationships among users, items, and behaviors, they still have limitations in heterogeneous semantics, user-specific weighting, and sequence dependency modeling. While standard Transformers excel at sequence modeling, their shared feedforward mapping struggles to accommodate the differentiated requirements of heterogeneous latent patterns in multi-behavior scenarios. To address this, this paper proposes the Personalized Hypergraph-enhanced Kolmogorov-Arnold Network Transformer (PHKT). Specifically, we design a personalized dynamic hypergraph module that performs behavior-aware weighting of item similarities based on users' historical behavior sequences to capture user-specific heterogeneous high-order relationships. Meanwhile, a Transformer is used as the temporal backbone to model the evolution of short- and long-term preferences, and KAN is introduced to replace the traditional MLP in the feedforward network to enhance fine-grained modeling capability for nonlinear responses to different latent patterns. Experiments on three real datasets, Tmall, RetailRocket, and IJCAI, show that PHKT consistently outperforms nine strong baseline models across multiple evaluation metrics, demonstrating its effectiveness in multi-behavior preference modeling and target behavior prediction.
Collaborative Multi-LoRA Experts with Achievement-based Multi-Tasks Loss for Unified Multimodal Information Extraction
May 08, 2025Multimodal Information Extraction (MIE) has gained attention for extracting structured information from multimedia sources. Traditional methods tackle MIE tasks separately, missing opportunities to share knowledge across tasks. Recent approaches unify these tasks into a generation problem using instruction-based T5 models with visual adaptors, optimized through full-parameter fine-tuning. However, this method is computationally intensive, and multi-task fine-tuning often faces gradient conflicts, limiting performance. To address these challenges, we propose collaborative multi-LoRA experts with achievement-based multi-task loss (C-LoRAE) for MIE tasks. C-LoRAE extends the low-rank adaptation (LoRA) method by incorporating a universal expert to learn shared multimodal knowledge from cross-MIE tasks and task-specific experts to learn specialized instructional task features. This configuration enhances the model's generalization ability across multiple tasks while maintaining the independence of various instruction tasks and mitigating gradient conflicts. Additionally, we propose an achievement-based multi-task loss to balance training progress across tasks, addressing the imbalance caused by varying numbers of training samples in MIE tasks. Experimental results on seven benchmark datasets across three key MIE tasks demonstrate that C-LoRAE achieves superior overall performance compared to traditional fine-tuning methods and LoRA methods while utilizing a comparable number of training parameters to LoRA.
MSTS: A Multimodal Safety Test Suite for Vision-Language Models
Jan 17, 2025Vision-language models (VLMs), which process image and text inputs, are increasingly integrated into chat assistants and other consumer AI applications. Without proper safeguards, however, VLMs may give harmful advice (e.g. how to self-harm) or encourage unsafe behaviours (e.g. to consume drugs). Despite these clear hazards, little work so far has evaluated VLM safety and the novel risks created by multimodal inputs. To address this gap, we introduce MSTS, a Multimodal Safety Test Suite for VLMs. MSTS comprises 400 test prompts across 40 fine-grained hazard categories. Each test prompt consists of a text and an image that only in combination reveal their full unsafe meaning. With MSTS, we find clear safety issues in several open VLMs. We also find some VLMs to be safe by accident, meaning that they are safe because they fail to understand even simple test prompts. We translate MSTS into ten languages, showing non-English prompts to increase the rate of unsafe model responses. We also show models to be safer when tested with text only rather than multimodal prompts. Finally, we explore the automation of VLM safety assessments, finding even the best safety classifiers to be lacking.
Introducing v0.5 of the AI Safety Benchmark from MLCommons
Apr 18, 2024



This paper introduces v0.5 of the AI Safety Benchmark, which has been created by the MLCommons AI Safety Working Group. The AI Safety Benchmark has been designed to assess the safety risks of AI systems that use chat-tuned language models. We introduce a principled approach to specifying and constructing the benchmark, which for v0.5 covers only a single use case (an adult chatting to a general-purpose assistant in English), and a limited set of personas (i.e., typical users, malicious users, and vulnerable users). We created a new taxonomy of 13 hazard categories, of which 7 have tests in the v0.5 benchmark. We plan to release version 1.0 of the AI Safety Benchmark by the end of 2024. The v1.0 benchmark will provide meaningful insights into the safety of AI systems. However, the v0.5 benchmark should not be used to assess the safety of AI systems. We have sought to fully document the limitations, flaws, and challenges of v0.5. This release of v0.5 of the AI Safety Benchmark includes (1) a principled approach to specifying and constructing the benchmark, which comprises use cases, types of systems under test (SUTs), language and context, personas, tests, and test items; (2) a taxonomy of 13 hazard categories with definitions and subcategories; (3) tests for seven of the hazard categories, each comprising a unique set of test items, i.e., prompts. There are 43,090 test items in total, which we created with templates; (4) a grading system for AI systems against the benchmark; (5) an openly available platform, and downloadable tool, called ModelBench that can be used to evaluate the safety of AI systems on the benchmark; (6) an example evaluation report which benchmarks the performance of over a dozen openly available chat-tuned language models; (7) a test specification for the benchmark.
Finetuning Text-to-Image Diffusion Models for Fairness
Nov 11, 2023



The rapid adoption of text-to-image diffusion models in society underscores an urgent need to address their biases. Without interventions, these biases could propagate a distorted worldview and limit opportunities for minority groups. In this work, we frame fairness as a distributional alignment problem. Our solution consists of two main technical contributions: (1) a distributional alignment loss that steers specific characteristics of the generated images towards a user-defined target distribution, and (2) biased direct finetuning of diffusion model's sampling process, which leverages a biased gradient to more effectively optimize losses defined on the generated images. Empirically, our method markedly reduces gender, racial, and their intersectional biases for occupational prompts. Gender bias is significantly reduced even when finetuning just five soft tokens. Crucially, our method supports diverse perspectives of fairness beyond absolute equality, which is demonstrated by controlling age to a $75\%$ young and $25\%$ old distribution while simultaneously debiasing gender and race. Finally, our method is scalable: it can debias multiple concepts at once by simply including these prompts in the finetuning data. We hope our work facilitates the social alignment of T2I generative AI. We will share code and various debiased diffusion model adaptors.
Multimodal Prompt Transformer with Hybrid Contrastive Learning for Emotion Recognition in Conversation
Oct 04, 2023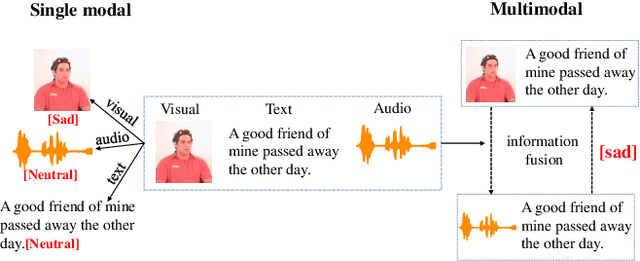
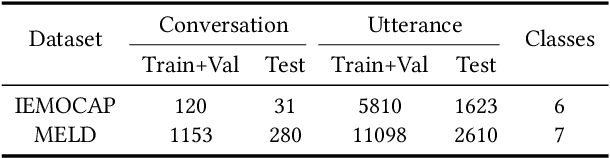
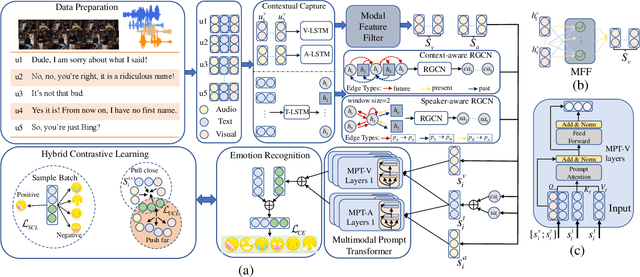

Emotion Recognition in Conversation (ERC) plays an important role in driving the development of human-machine interaction. Emotions can exist in multiple modalities, and multimodal ERC mainly faces two problems: (1) the noise problem in the cross-modal information fusion process, and (2) the prediction problem of less sample emotion labels that are semantically similar but different categories. To address these issues and fully utilize the features of each modality, we adopted the following strategies: first, deep emotion cues extraction was performed on modalities with strong representation ability, and feature filters were designed as multimodal prompt information for modalities with weak representation ability. Then, we designed a Multimodal Prompt Transformer (MPT) to perform cross-modal information fusion. MPT embeds multimodal fusion information into each attention layer of the Transformer, allowing prompt information to participate in encoding textual features and being fused with multi-level textual information to obtain better multimodal fusion features. Finally, we used the Hybrid Contrastive Learning (HCL) strategy to optimize the model's ability to handle labels with few samples. This strategy uses unsupervised contrastive learning to improve the representation ability of multimodal fusion and supervised contrastive learning to mine the information of labels with few samples. Experimental results show that our proposed model outperforms state-of-the-art models in ERC on two benchmark datasets.
Towards Regulatable AI Systems: Technical Gaps and Policy Opportunities
Jun 22, 2023There is increasing attention being given to how to regulate AI systems. As governing bodies grapple with what values to encapsulate into regulation, we consider the technical half of the question: To what extent can AI experts vet an AI system for adherence to regulatory requirements? We investigate this question through two public sector procurement checklists, identifying what we can do now, what we should be able to do with technical innovation in AI, and what requirements necessitate a more interdisciplinary approach.
Inverse Scaling: When Bigger Isn't Better
Jun 15, 2023



Work on scaling laws has found that large language models (LMs) show predictable improvements to overall loss with increased scale (model size, training data, and compute). Here, we present evidence for the claim that LMs may show inverse scaling, or worse task performance with increased scale, e.g., due to flaws in the training objective and data. We present empirical evidence of inverse scaling on 11 datasets collected by running a public contest, the Inverse Scaling Prize, with a substantial prize pool. Through analysis of the datasets, along with other examples found in the literature, we identify four potential causes of inverse scaling: (i) preference to repeat memorized sequences over following in-context instructions, (ii) imitation of undesirable patterns in the training data, (iii) tasks containing an easy distractor task which LMs could focus on, rather than the harder real task, and (iv) correct but misleading few-shot demonstrations of the task. We release the winning datasets at https://inversescaling.com/data to allow for further investigation of inverse scaling. Our tasks have helped drive the discovery of U-shaped and inverted-U scaling trends, where an initial trend reverses, suggesting that scaling trends are less reliable at predicting the behavior of larger-scale models than previously understood. Overall, our results suggest that there are tasks for which increased model scale alone may not lead to progress, and that more careful thought needs to go into the data and objectives for training language models.
Beyond the Imitation Game: Quantifying and extrapolating the capabilities of language models
Jun 10, 2022Language models demonstrate both quantitative improvement and new qualitative capabilities with increasing scale. Despite their potentially transformative impact, these new capabilities are as yet poorly characterized. In order to inform future research, prepare for disruptive new model capabilities, and ameliorate socially harmful effects, it is vital that we understand the present and near-future capabilities and limitations of language models. To address this challenge, we introduce the Beyond the Imitation Game benchmark (BIG-bench). BIG-bench currently consists of 204 tasks, contributed by 442 authors across 132 institutions. Task topics are diverse, drawing problems from linguistics, childhood development, math, common-sense reasoning, biology, physics, social bias, software development, and beyond. BIG-bench focuses on tasks that are believed to be beyond the capabilities of current language models. We evaluate the behavior of OpenAI's GPT models, Google-internal dense transformer architectures, and Switch-style sparse transformers on BIG-bench, across model sizes spanning millions to hundreds of billions of parameters. In addition, a team of human expert raters performed all tasks in order to provide a strong baseline. Findings include: model performance and calibration both improve with scale, but are poor in absolute terms (and when compared with rater performance); performance is remarkably similar across model classes, though with benefits from sparsity; tasks that improve gradually and predictably commonly involve a large knowledge or memorization component, whereas tasks that exhibit "breakthrough" behavior at a critical scale often involve multiple steps or components, or brittle metrics; social bias typically increases with scale in settings with ambiguous context, but this can be improved with prompting.