 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDeepFilters: Scattering-Aware Pupil Engineering with Learned Digital Filter Reconstruction for Extended Depth of Field Microscopy
May 13, 2026Extended depth of field microscopy encodes axial information into a single acquisition through engineered point spread functions, but conventional and deep optics approaches are subject to degradation in scattering tissue. We introduce DeepFilters, a scattering-aware deep optics framework that jointly optimizes a parameterized pupil filter and a digital-filter-based reconstruction network through a calibrated differentiable forward model to achieve broad generalization without retraining. Incorporating empirical scattering kernels, physics-guided regularization, and a hybrid genetic-gradient initialization strategy, DeepFilters extends the PSF from 16 micron to >400 micron in clear media and enables signal recovery beyond 120 micron deep in biological tissues, validated across fixed brain slices and sea urchin embryos.
Investigating Accuracy-Novelty Performance for Graph-based Collaborative Filtering
Apr 27, 2022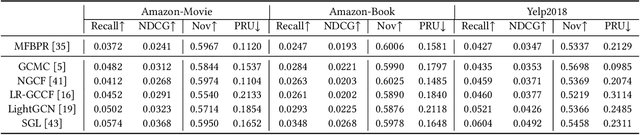
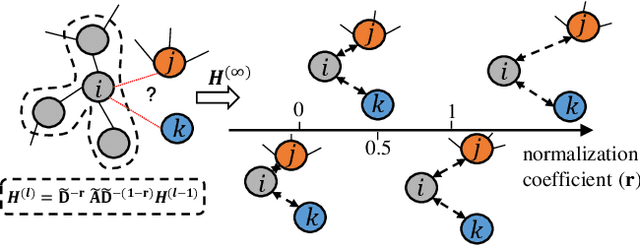
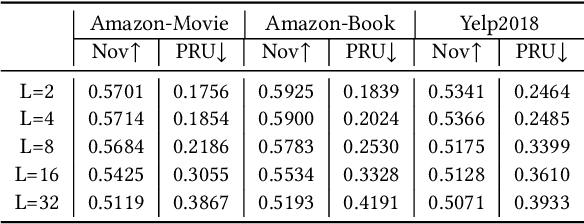
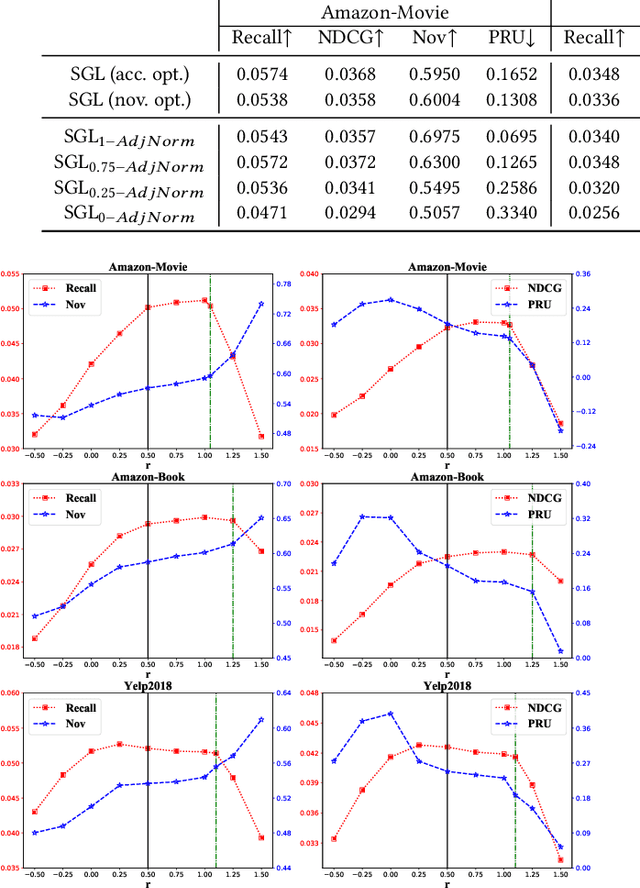
Recent years have witnessed the great accuracy performance of graph-based Collaborative Filtering (CF) models for recommender systems. By taking the user-item interaction behavior as a graph, these graph-based CF models borrow the success of Graph Neural Networks (GNN), and iteratively perform neighborhood aggregation to propagate the collaborative signals. While conventional CF models are known for facing the challenges of the popularity bias that favors popular items, one may wonder "Whether the existing graph-based CF models alleviate or exacerbate popularity bias of recommender systems?" To answer this question, we first investigate the two-fold performances w.r.t. accuracy and novelty for existing graph-based CF methods. The empirical results show that symmetric neighborhood aggregation adopted by most existing graph-based CF models exacerbate the popularity bias and this phenomenon becomes more serious as the depth of graph propagation increases. Further, we theoretically analyze the cause of popularity bias for graph-based CF. Then, we propose a simple yet effective plugin, namely r-AdjNorm, to achieve an accuracy-novelty trade-off by controlling the normalization strength in the neighborhood aggregation process. Meanwhile, r-AdjNorm can be smoothly applied to the existing graph-based CF backbones without additional computation. Finally, experimental results on three benchmark datasets show that our proposed method can improve novelty without sacrificing accuracy under various graph-based CF backbones.
RL4RS: A Real-World Benchmark for Reinforcement Learning based Recommender System
Oct 18, 2021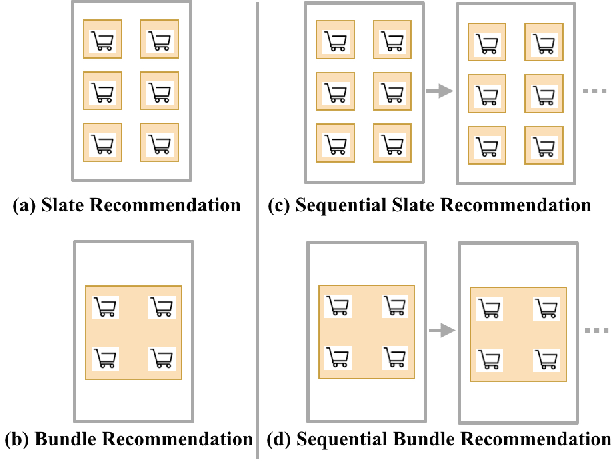
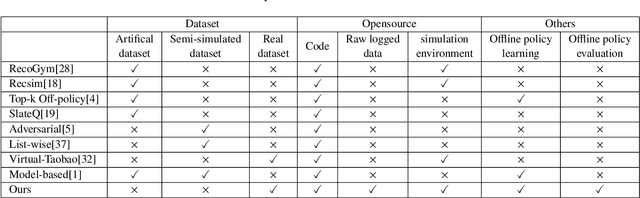
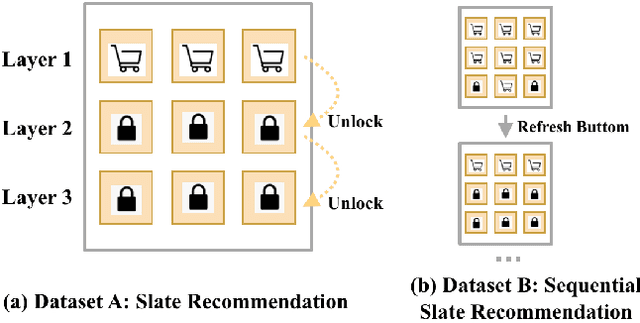
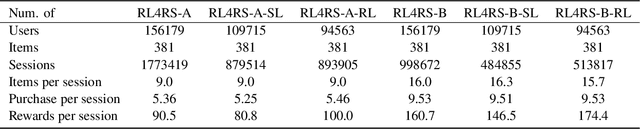
Reinforcement learning based recommender systems (RL-based RS) aims at learning a good policy from a batch of collected data, with casting sequential recommendation to multi-step decision-making tasks. However, current RL-based RS benchmarks commonly have a large reality gap, because they involve artificial RL datasets or semi-simulated RS datasets, and the trained policy is directly evaluated in the simulation environment. In real-world situations, not all recommendation problems are suitable to be transformed into reinforcement learning problems. Unlike previous academic RL researches, RL-based RS suffer from extrapolation error and the difficulties of being well validated before deployment. In this paper, we introduce the RL4RS (Reinforcement Learning for Recommender Systems) benchmark - a new resource fully collected from industrial applications to train and evaluate RL algorithms with special concerns on the above issues. It contains two datasets, tuned simulation environments, related advanced RL baselines, data understanding tools, and counterfactual policy evaluation algorithms. The RL4RS suit can be found at https://github.com/fuxiAIlab/RL4RS. In addition to the RL-based recommender systems, we expect the resource to contribute to research in reinforcement learning and neural combinatorial optimization.
Personalized Bundle Recommendation in Online Games
Apr 12, 2021

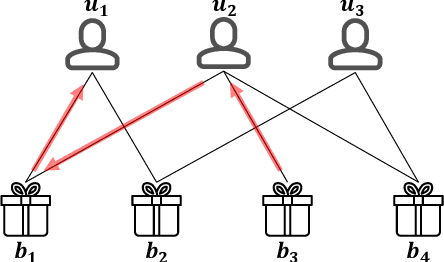
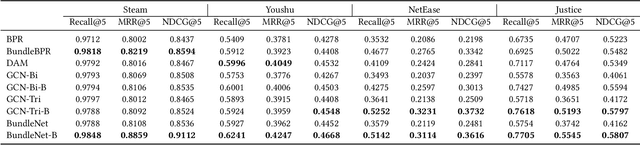
In business domains, \textit{bundling} is one of the most important marketing strategies to conduct product promotions, which is commonly used in online e-commerce and offline retailers. Existing recommender systems mostly focus on recommending individual items that users may be interested in. In this paper, we target at a practical but less explored recommendation problem named bundle recommendation, which aims to offer a combination of items to users. To tackle this specific recommendation problem in the context of the \emph{virtual mall} in online games, we formalize it as a link prediction problem on a user-item-bundle tripartite graph constructed from the historical interactions, and solve it with a neural network model that can learn directly on the graph-structure data. Extensive experiments on three public datasets and one industrial game dataset demonstrate the effectiveness of the proposed method. Further, the bundle recommendation model has been deployed in production for more than one year in a popular online game developed by Netease Games, and the launch of the model yields more than 60\% improvement on conversion rate of bundles, and a relative improvement of more than 15\% on gross merchandise volume (GMV).
Reinforcement Learning with a Disentangled Universal Value Function for Item Recommendation
Apr 11, 2021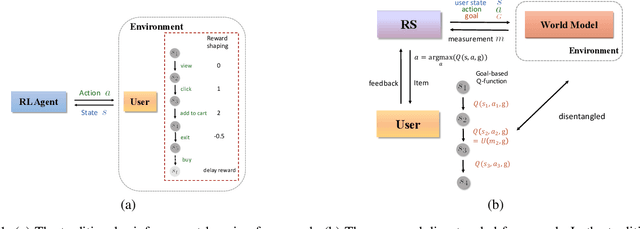
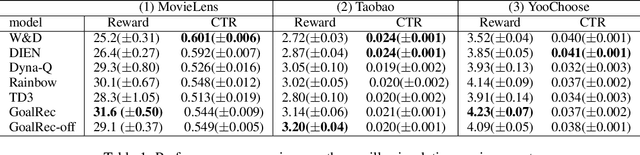
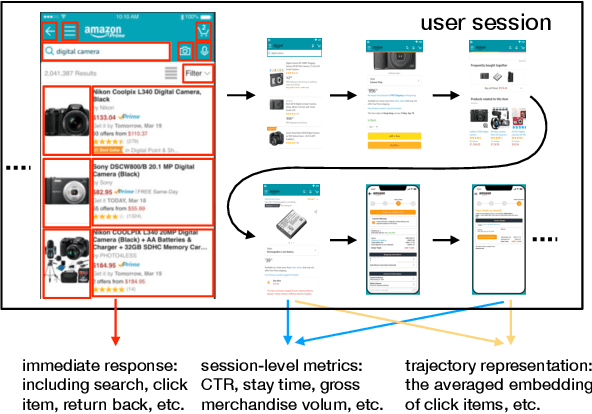

In recent years, there are great interests as well as challenges in applying reinforcement learning (RL) to recommendation systems (RS). In this paper, we summarize three key practical challenges of large-scale RL-based recommender systems: massive state and action spaces, high-variance environment, and the unspecific reward setting in recommendation. All these problems remain largely unexplored in the existing literature and make the application of RL challenging. We develop a model-based reinforcement learning framework, called GoalRec. Inspired by the ideas of world model (model-based), value function estimation (model-free), and goal-based RL, a novel disentangled universal value function designed for item recommendation is proposed. It can generalize to various goals that the recommender may have, and disentangle the stochastic environmental dynamics and high-variance reward signals accordingly. As a part of the value function, free from the sparse and high-variance reward signals, a high-capacity reward-independent world model is trained to simulate complex environmental dynamics under a certain goal. Based on the predicted environmental dynamics, the disentangled universal value function is related to the user's future trajectory instead of a monolithic state and a scalar reward. We demonstrate the superiority of GoalRec over previous approaches in terms of the above three practical challenges in a series of simulations and a real application.