 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMem4D: Decoupling Static and Dynamic Memory for Dynamic Scene Reconstruction
Aug 12, 2025Reconstructing dense geometry for dynamic scenes from a monocular video is a critical yet challenging task. Recent memory-based methods enable efficient online reconstruction, but they fundamentally suffer from a Memory Demand Dilemma: The memory representation faces an inherent conflict between the long-term stability required for static structures and the rapid, high-fidelity detail retention needed for dynamic motion. This conflict forces existing methods into a compromise, leading to either geometric drift in static structures or blurred, inaccurate reconstructions of dynamic objects. To address this dilemma, we propose Mem4D, a novel framework that decouples the modeling of static geometry and dynamic motion. Guided by this insight, we design a dual-memory architecture: 1) The Transient Dynamics Memory (TDM) focuses on capturing high-frequency motion details from recent frames, enabling accurate and fine-grained modeling of dynamic content; 2) The Persistent Structure Memory (PSM) compresses and preserves long-term spatial information, ensuring global consistency and drift-free reconstruction for static elements. By alternating queries to these specialized memories, Mem4D simultaneously maintains static geometry with global consistency and reconstructs dynamic elements with high fidelity. Experiments on challenging benchmarks demonstrate that our method achieves state-of-the-art or competitive performance while maintaining high efficiency. Codes will be publicly available.
Personalized Bundle Recommendation in Online Games
Apr 12, 2021

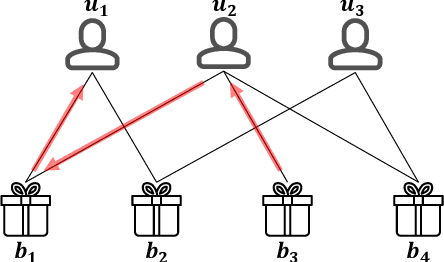
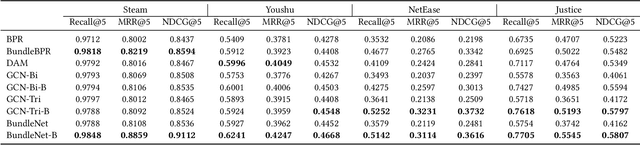
In business domains, \textit{bundling} is one of the most important marketing strategies to conduct product promotions, which is commonly used in online e-commerce and offline retailers. Existing recommender systems mostly focus on recommending individual items that users may be interested in. In this paper, we target at a practical but less explored recommendation problem named bundle recommendation, which aims to offer a combination of items to users. To tackle this specific recommendation problem in the context of the \emph{virtual mall} in online games, we formalize it as a link prediction problem on a user-item-bundle tripartite graph constructed from the historical interactions, and solve it with a neural network model that can learn directly on the graph-structure data. Extensive experiments on three public datasets and one industrial game dataset demonstrate the effectiveness of the proposed method. Further, the bundle recommendation model has been deployed in production for more than one year in a popular online game developed by Netease Games, and the launch of the model yields more than 60\% improvement on conversion rate of bundles, and a relative improvement of more than 15\% on gross merchandise volume (GMV).
Reinforcement Learning with a Disentangled Universal Value Function for Item Recommendation
Apr 11, 2021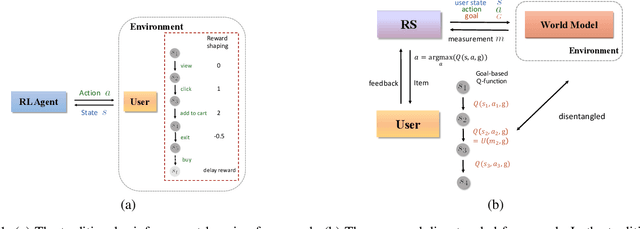
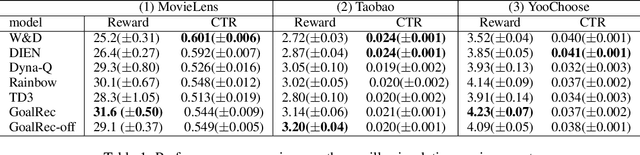
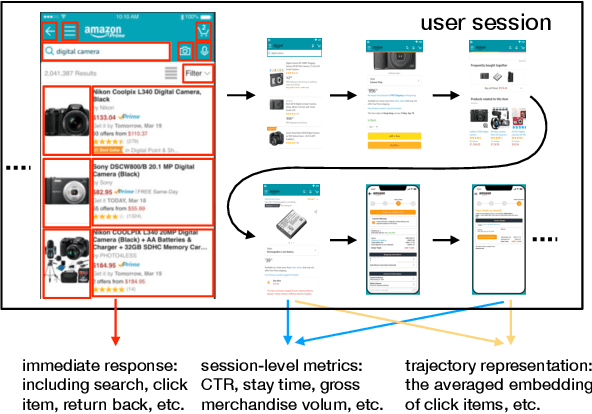

In recent years, there are great interests as well as challenges in applying reinforcement learning (RL) to recommendation systems (RS). In this paper, we summarize three key practical challenges of large-scale RL-based recommender systems: massive state and action spaces, high-variance environment, and the unspecific reward setting in recommendation. All these problems remain largely unexplored in the existing literature and make the application of RL challenging. We develop a model-based reinforcement learning framework, called GoalRec. Inspired by the ideas of world model (model-based), value function estimation (model-free), and goal-based RL, a novel disentangled universal value function designed for item recommendation is proposed. It can generalize to various goals that the recommender may have, and disentangle the stochastic environmental dynamics and high-variance reward signals accordingly. As a part of the value function, free from the sparse and high-variance reward signals, a high-capacity reward-independent world model is trained to simulate complex environmental dynamics under a certain goal. Based on the predicted environmental dynamics, the disentangled universal value function is related to the user's future trajectory instead of a monolithic state and a scalar reward. We demonstrate the superiority of GoalRec over previous approaches in terms of the above three practical challenges in a series of simulations and a real application.
Learning Decomposed Representation for Counterfactual Inference
Jun 12, 2020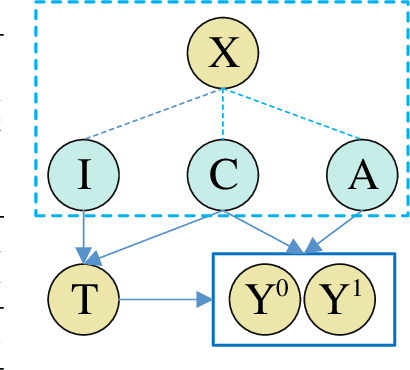
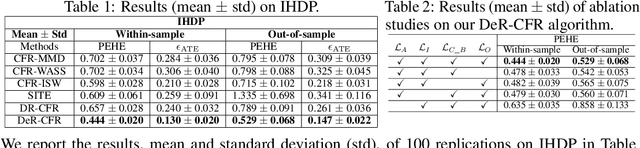
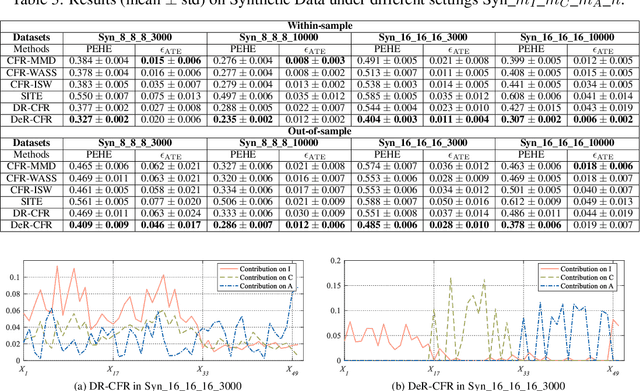
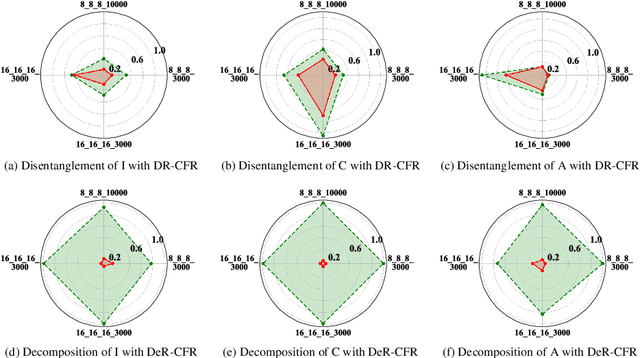
One fundamental problem in the learning treatment effect from observational data is confounder identification and balancing. Most of the previous methods realized confounder balancing by treating all observed variables as confounders, ignoring the identification of confounders and non-confounders. In general, not all the observed variables are confounders which are the common causes of both the treatment and the outcome, some variables only contribute to the treatment and some contribute to the outcome. Balancing those non-confounders would generate additional bias for treatment effect estimation. By modeling the different relations among variables, treatment and outcome, we propose a synergistic learning framework to 1) identify and balance confounders by learning decomposed representation of confounders and non-confounders, and simultaneously 2) estimate the treatment effect in observational studies via counterfactual inference. Our empirical results demonstrate that the proposed method can precisely identify and balance confounders, while the estimation of the treatment effect performs better than the state-of-the-art methods on both synthetic and real-world datasets.
Stable Prediction via Leveraging Seed Variable
Jun 09, 2020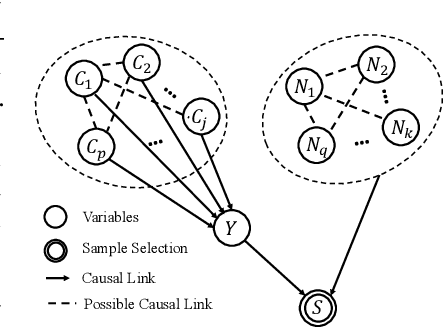
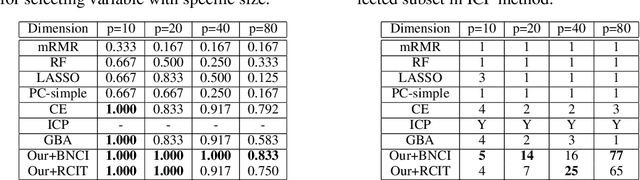
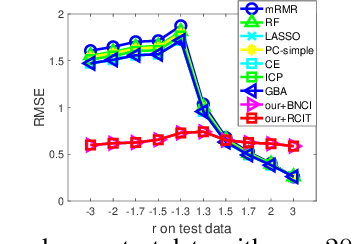

In this paper, we focus on the problem of stable prediction across unknown test data, where the test distribution is agnostic and might be totally different from the training one. In such a case, previous machine learning methods might exploit subtly spurious correlations in training data induced by non-causal variables for prediction. Those spurious correlations are changeable across data, leading to instability of prediction across data. By assuming the relationships between causal variables and response variable are invariant across data, to address this problem, we propose a conditional independence test based algorithm to separate those causal variables with a seed variable as priori, and adopt them for stable prediction. By assuming the independence between causal and non-causal variables, we show, both theoretically and with empirical experiments, that our algorithm can precisely separate causal and non-causal variables for stable prediction across test data. Extensive experiments on both synthetic and real-world datasets demonstrate that our algorithm outperforms state-of-the-art methods for stable prediction.