 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEfficient Parallel Genetic Algorithm for Perturbed Substructure Optimization in Complex Network
Dec 30, 2024



Evolutionary computing, particularly genetic algorithm (GA), is a combinatorial optimization method inspired by natural selection and the transmission of genetic information, which is widely used to identify optimal solutions to complex problems through simulated programming and iteration. Due to its strong adaptability, flexibility, and robustness, GA has shown significant performance and potentiality on perturbed substructure optimization (PSSO), an important graph mining problem that achieves its goals by modifying network structures. However, the efficiency and practicality of GA-based PSSO face enormous challenges due to the complexity and diversity of application scenarios. While some research has explored acceleration frameworks in evolutionary computing, their performance on PSSO remains limited due to a lack of scenario generalizability. Based on these, this paper is the first to present the GA-based PSSO Acceleration framework (GAPA), which simplifies the GA development process and supports distributed acceleration. Specifically, it reconstructs the genetic operation and designs a development framework for efficient parallel acceleration. Meanwhile, GAPA includes an extensible library that optimizes and accelerates 10 PSSO algorithms, covering 4 crucial tasks for graph mining. Comprehensive experiments on 18 datasets across 4 tasks and 10 algorithms effectively demonstrate the superiority of GAPA, achieving an average of 4x the acceleration of Evox. The repository is in https://github.com/NetAlsGroup/GAPA.
AutoMLP: Automated MLP for Sequential Recommendations
Mar 11, 2023



Sequential recommender systems aim to predict users' next interested item given their historical interactions. However, a long-standing issue is how to distinguish between users' long/short-term interests, which may be heterogeneous and contribute differently to the next recommendation. Existing approaches usually set pre-defined short-term interest length by exhaustive search or empirical experience, which is either highly inefficient or yields subpar results. The recent advanced transformer-based models can achieve state-of-the-art performances despite the aforementioned issue, but they have a quadratic computational complexity to the length of the input sequence. To this end, this paper proposes a novel sequential recommender system, AutoMLP, aiming for better modeling users' long/short-term interests from their historical interactions. In addition, we design an automated and adaptive search algorithm for preferable short-term interest length via end-to-end optimization. Through extensive experiments, we show that AutoMLP has competitive performance against state-of-the-art methods, while maintaining linear computational complexity.
Dynamic Spatial-temporal Hypergraph Convolutional Network for Skeleton-based Action Recognition
Feb 17, 2023



Skeleton-based action recognition relies on the extraction of spatial-temporal topological information. Hypergraphs can establish prior unnatural dependencies for the skeleton. However, the existing methods only focus on the construction of spatial topology and ignore the time-point dependence. This paper proposes a dynamic spatial-temporal hypergraph convolutional network (DST-HCN) to capture spatial-temporal information for skeleton-based action recognition. DST-HCN introduces a time-point hypergraph (TPH) to learn relationships at time points. With multiple spatial static hypergraphs and dynamic TPH, our network can learn more complete spatial-temporal features. In addition, we use the high-order information fusion module (HIF) to fuse spatial-temporal information synchronously. Extensive experiments on NTU RGB+D, NTU RGB+D 120, and NW-UCLA datasets show that our model achieves state-of-the-art, especially compared with hypergraph methods.
Skeleton-based Action Recognition via Temporal-Channel Aggregation
May 31, 2022



Skeleton-based action recognition methods are limited by the semantic extraction of spatio-temporal skeletal maps. However, current methods have difficulty in effectively combining features from both temporal and spatial graph dimensions and tend to be thick on one side and thin on the other. In this paper, we propose a Temporal-Channel Aggregation Graph Convolutional Networks (TCA-GCN) to learn spatial and temporal topologies dynamically and efficiently aggregate topological features in different temporal and channel dimensions for skeleton-based action recognition. We use the Temporal Aggregation module to learn temporal dimensional features and the Channel Aggregation module to efficiently combine spatial dynamic topological features learned using Channel-wise with temporal dynamic topological features. In addition, we extract multi-scale skeletal features on temporal modeling and fuse them with priori skeletal knowledge with an attention mechanism. Extensive experiments show that our model results outperform state-of-the-art methods on the NTU RGB+D, NTU RGB+D 120, and NW-UCLA datasets.
Investigating Accuracy-Novelty Performance for Graph-based Collaborative Filtering
Apr 27, 2022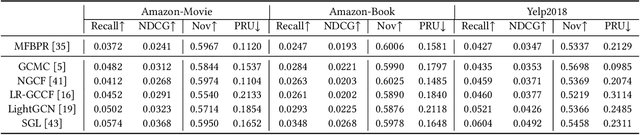
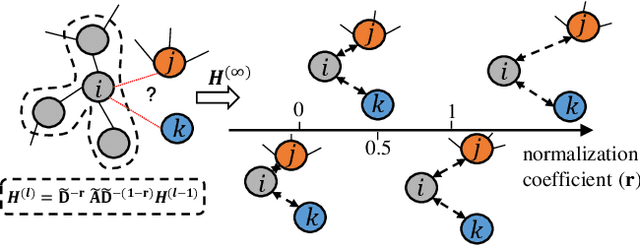
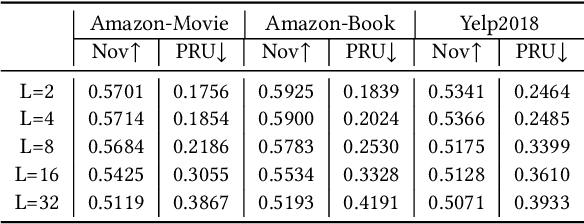
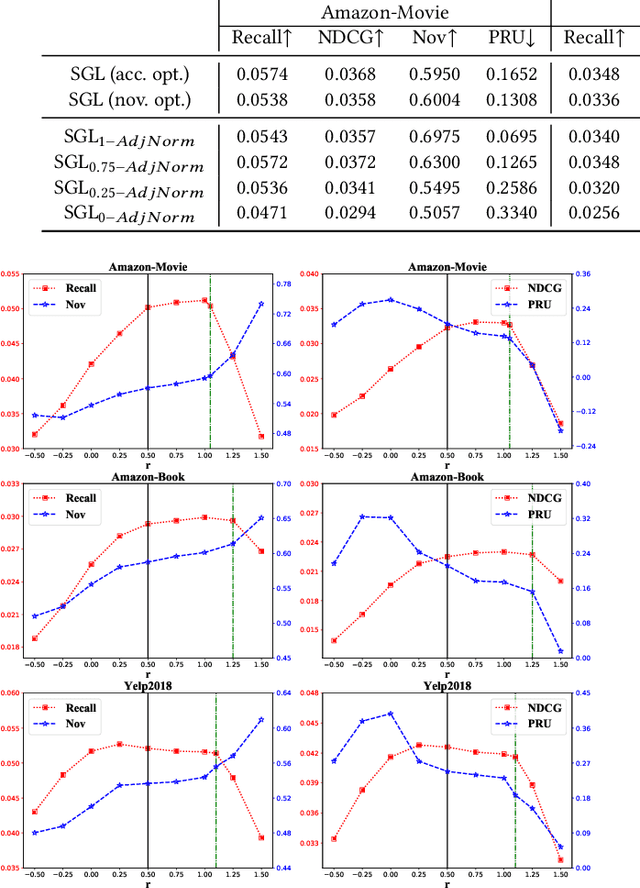
Recent years have witnessed the great accuracy performance of graph-based Collaborative Filtering (CF) models for recommender systems. By taking the user-item interaction behavior as a graph, these graph-based CF models borrow the success of Graph Neural Networks (GNN), and iteratively perform neighborhood aggregation to propagate the collaborative signals. While conventional CF models are known for facing the challenges of the popularity bias that favors popular items, one may wonder "Whether the existing graph-based CF models alleviate or exacerbate popularity bias of recommender systems?" To answer this question, we first investigate the two-fold performances w.r.t. accuracy and novelty for existing graph-based CF methods. The empirical results show that symmetric neighborhood aggregation adopted by most existing graph-based CF models exacerbate the popularity bias and this phenomenon becomes more serious as the depth of graph propagation increases. Further, we theoretically analyze the cause of popularity bias for graph-based CF. Then, we propose a simple yet effective plugin, namely r-AdjNorm, to achieve an accuracy-novelty trade-off by controlling the normalization strength in the neighborhood aggregation process. Meanwhile, r-AdjNorm can be smoothly applied to the existing graph-based CF backbones without additional computation. Finally, experimental results on three benchmark datasets show that our proposed method can improve novelty without sacrificing accuracy under various graph-based CF backbones.
MLP4Rec: A Pure MLP Architecture for Sequential Recommendations
Apr 25, 2022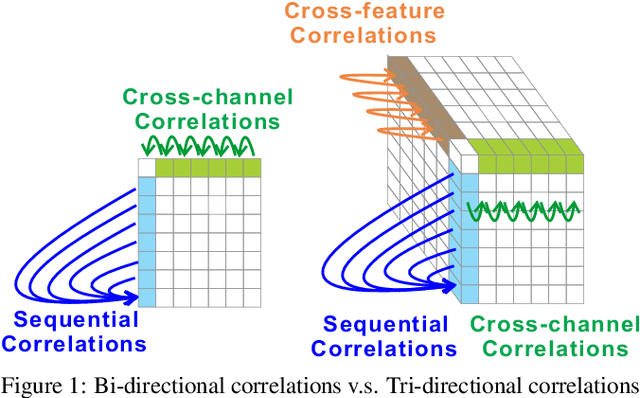
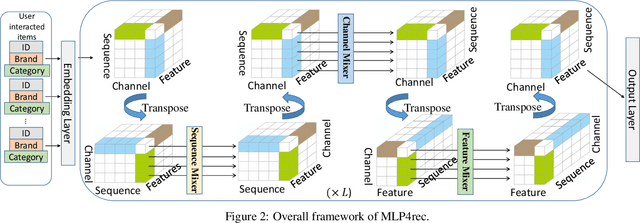

Self-attention models have achieved state-of-the-art performance in sequential recommender systems by capturing the sequential dependencies among user-item interactions. However, they rely on positional embeddings to retain the sequential information, which may break the semantics of item embeddings. In addition, most existing works assume that such sequential dependencies exist solely in the item embeddings, but neglect their existence among the item features. In this work, we propose a novel sequential recommender system (MLP4Rec) based on the recent advances of MLP-based architectures, which is naturally sensitive to the order of items in a sequence. To be specific, we develop a tri-directional fusion scheme to coherently capture sequential, cross-channel and cross-feature correlations. Extensive experiments demonstrate the effectiveness of MLP4Rec over various representative baselines upon two benchmark datasets. The simple architecture of MLP4Rec also leads to the linear computational complexity as well as much fewer model parameters than existing self-attention methods.
RL4RS: A Real-World Benchmark for Reinforcement Learning based Recommender System
Oct 18, 2021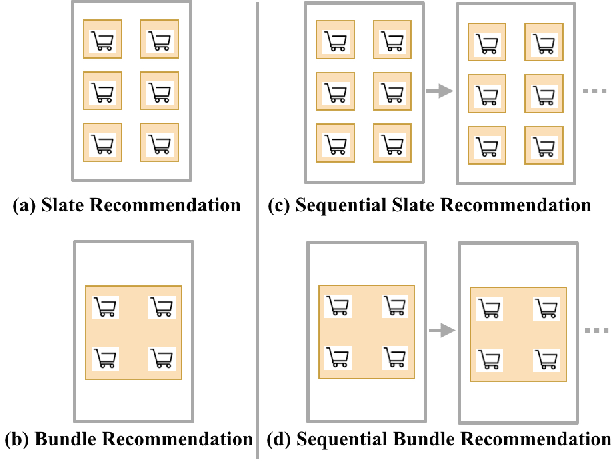
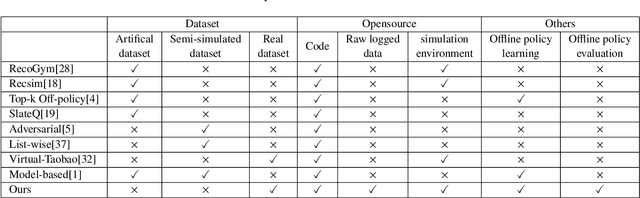
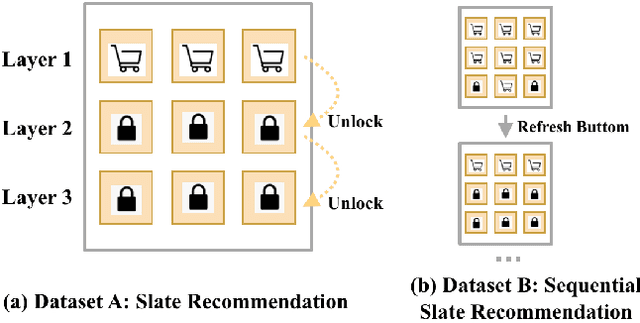
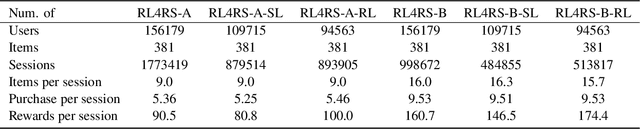
Reinforcement learning based recommender systems (RL-based RS) aims at learning a good policy from a batch of collected data, with casting sequential recommendation to multi-step decision-making tasks. However, current RL-based RS benchmarks commonly have a large reality gap, because they involve artificial RL datasets or semi-simulated RS datasets, and the trained policy is directly evaluated in the simulation environment. In real-world situations, not all recommendation problems are suitable to be transformed into reinforcement learning problems. Unlike previous academic RL researches, RL-based RS suffer from extrapolation error and the difficulties of being well validated before deployment. In this paper, we introduce the RL4RS (Reinforcement Learning for Recommender Systems) benchmark - a new resource fully collected from industrial applications to train and evaluate RL algorithms with special concerns on the above issues. It contains two datasets, tuned simulation environments, related advanced RL baselines, data understanding tools, and counterfactual policy evaluation algorithms. The RL4RS suit can be found at https://github.com/fuxiAIlab/RL4RS. In addition to the RL-based recommender systems, we expect the resource to contribute to research in reinforcement learning and neural combinatorial optimization.
Spirit Distillation: A Model Compression Method with Multi-domain Knowledge Transfer
Apr 29, 2021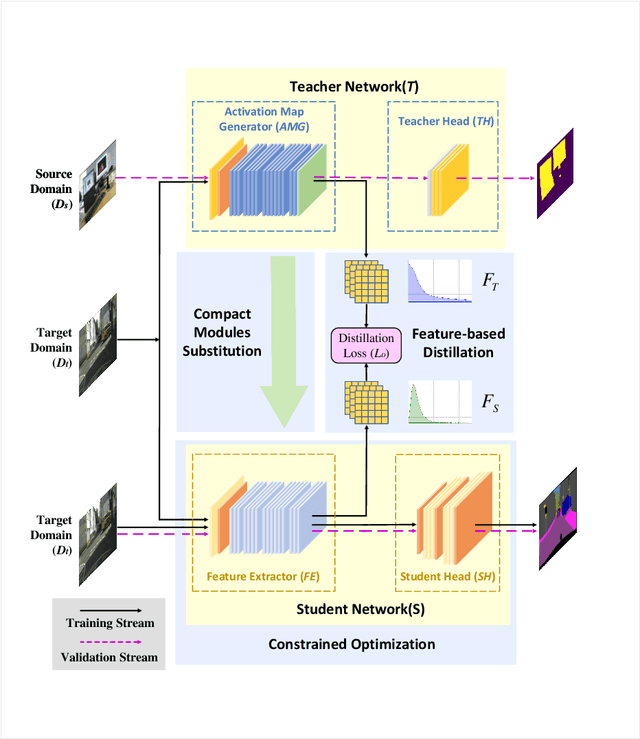

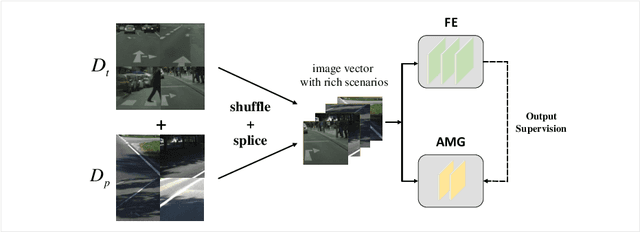

Recent applications pose requirements of both cross-domain knowledge transfer and model compression to machine learning models due to insufficient training data and limited computational resources. In this paper, we propose a new knowledge distillation model, named Spirit Distillation (SD), which is a model compression method with multi-domain knowledge transfer. The compact student network mimics out a representation equivalent to the front part of the teacher network, through which the general knowledge can be transferred from the source domain (teacher) to the target domain (student). To further improve the robustness of the student, we extend SD to Enhanced Spirit Distillation (ESD) in exploiting a more comprehensive knowledge by introducing the proximity domain which is similar to the target domain for feature extraction. Results demonstrate that our method can boost mIOU and high-precision accuracy by 1.4% and 8.2% respectively with 78.2% segmentation variance, and can gain a precise compact network with only 41.8% FLOPs.
Personalized Bundle Recommendation in Online Games
Apr 12, 2021

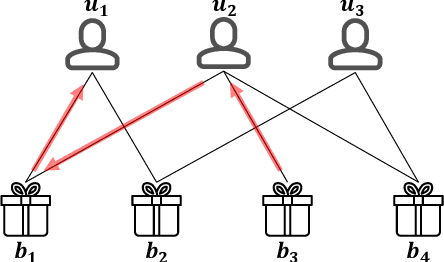
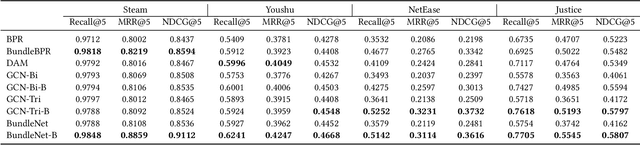
In business domains, \textit{bundling} is one of the most important marketing strategies to conduct product promotions, which is commonly used in online e-commerce and offline retailers. Existing recommender systems mostly focus on recommending individual items that users may be interested in. In this paper, we target at a practical but less explored recommendation problem named bundle recommendation, which aims to offer a combination of items to users. To tackle this specific recommendation problem in the context of the \emph{virtual mall} in online games, we formalize it as a link prediction problem on a user-item-bundle tripartite graph constructed from the historical interactions, and solve it with a neural network model that can learn directly on the graph-structure data. Extensive experiments on three public datasets and one industrial game dataset demonstrate the effectiveness of the proposed method. Further, the bundle recommendation model has been deployed in production for more than one year in a popular online game developed by Netease Games, and the launch of the model yields more than 60\% improvement on conversion rate of bundles, and a relative improvement of more than 15\% on gross merchandise volume (GMV).
Activation Map Adaptation for Effective Knowledge Distillation
Oct 26, 2020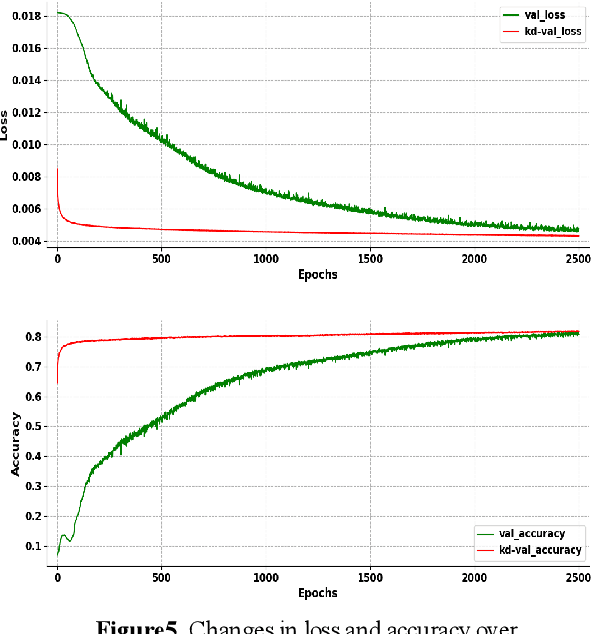
Model compression becomes a recent trend due to the requirement of deploying neural networks on embedded and mobile devices. Hence, both accuracy and efficiency are of critical importance. To explore a balance between them, a knowledge distillation strategy is proposed for general visual representation learning. It utilizes our well-designed activation map adaptive module to replace some blocks of the teacher network, exploring the most appropriate supervisory features adaptively during the training process. Using the teacher's hidden layer output to prompt the student network to train so as to transfer effective semantic information.To verify the effectiveness of our strategy, this paper applied our method to cifar-10 dataset. Results demonstrate that the method can boost the accuracy of the student network by 0.6% with 6.5% loss reduction, and significantly improve its training speed.