 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSkeleton-based Action Recognition via Temporal-Channel Aggregation
May 31, 2022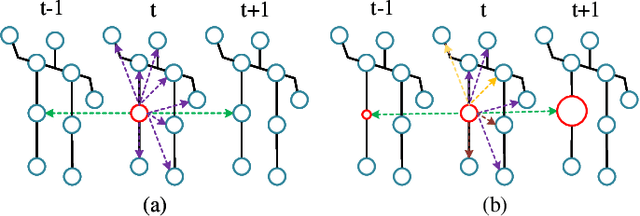



Skeleton-based action recognition methods are limited by the semantic extraction of spatio-temporal skeletal maps. However, current methods have difficulty in effectively combining features from both temporal and spatial graph dimensions and tend to be thick on one side and thin on the other. In this paper, we propose a Temporal-Channel Aggregation Graph Convolutional Networks (TCA-GCN) to learn spatial and temporal topologies dynamically and efficiently aggregate topological features in different temporal and channel dimensions for skeleton-based action recognition. We use the Temporal Aggregation module to learn temporal dimensional features and the Channel Aggregation module to efficiently combine spatial dynamic topological features learned using Channel-wise with temporal dynamic topological features. In addition, we extract multi-scale skeletal features on temporal modeling and fuse them with priori skeletal knowledge with an attention mechanism. Extensive experiments show that our model results outperform state-of-the-art methods on the NTU RGB+D, NTU RGB+D 120, and NW-UCLA datasets.