 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeActivation Map Adaptation for Effective Knowledge Distillation
Paper and Code
Oct 26, 2020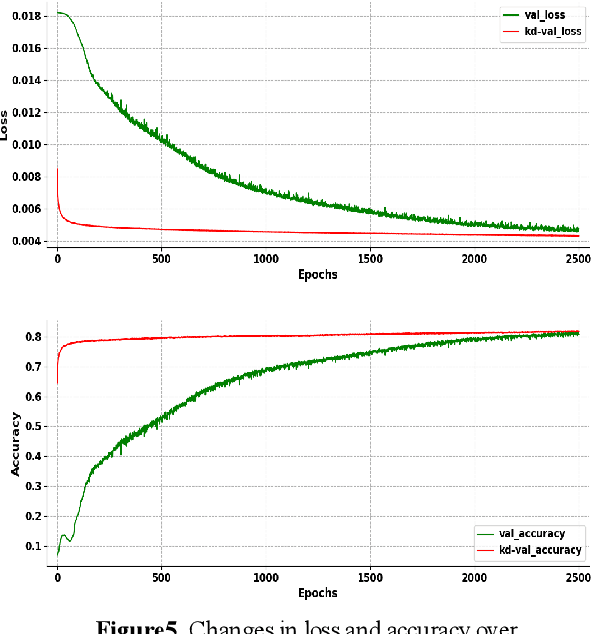
Model compression becomes a recent trend due to the requirement of deploying neural networks on embedded and mobile devices. Hence, both accuracy and efficiency are of critical importance. To explore a balance between them, a knowledge distillation strategy is proposed for general visual representation learning. It utilizes our well-designed activation map adaptive module to replace some blocks of the teacher network, exploring the most appropriate supervisory features adaptively during the training process. Using the teacher's hidden layer output to prompt the student network to train so as to transfer effective semantic information.To verify the effectiveness of our strategy, this paper applied our method to cifar-10 dataset. Results demonstrate that the method can boost the accuracy of the student network by 0.6% with 6.5% loss reduction, and significantly improve its training speed.