 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDigital Player: Evaluating Large Language Models based Human-like Agent in Games
Feb 28, 2025With the rapid advancement of Large Language Models (LLMs), LLM-based autonomous agents have shown the potential to function as digital employees, such as digital analysts, teachers, and programmers. In this paper, we develop an application-level testbed based on the open-source strategy game "Unciv", which has millions of active players, to enable researchers to build a "data flywheel" for studying human-like agents in the "digital players" task. This "Civilization"-like game features expansive decision-making spaces along with rich linguistic interactions such as diplomatic negotiations and acts of deception, posing significant challenges for LLM-based agents in terms of numerical reasoning and long-term planning. Another challenge for "digital players" is to generate human-like responses for social interaction, collaboration, and negotiation with human players. The open-source project can be found at https:/github.com/fuxiAIlab/CivAgent.
XRL-Bench: A Benchmark for Evaluating and Comparing Explainable Reinforcement Learning Techniques
Feb 20, 2024



Reinforcement Learning (RL) has demonstrated substantial potential across diverse fields, yet understanding its decision-making process, especially in real-world scenarios where rationality and safety are paramount, is an ongoing challenge. This paper delves in to Explainable RL (XRL), a subfield of Explainable AI (XAI) aimed at unravelling the complexities of RL models. Our focus rests on state-explaining techniques, a crucial subset within XRL methods, as they reveal the underlying factors influencing an agent's actions at any given time. Despite their significant role, the lack of a unified evaluation framework hinders assessment of their accuracy and effectiveness. To address this, we introduce XRL-Bench, a unified standardized benchmark tailored for the evaluation and comparison of XRL methods, encompassing three main modules: standard RL environments, explainers based on state importance, and standard evaluators. XRL-Bench supports both tabular and image data for state explanation. We also propose TabularSHAP, an innovative and competitive XRL method. We demonstrate the practical utility of TabularSHAP in real-world online gaming services and offer an open-source benchmark platform for the straightforward implementation and evaluation of XRL methods. Our contributions facilitate the continued progression of XRL technology.
RL4RS: A Real-World Benchmark for Reinforcement Learning based Recommender System
Oct 18, 2021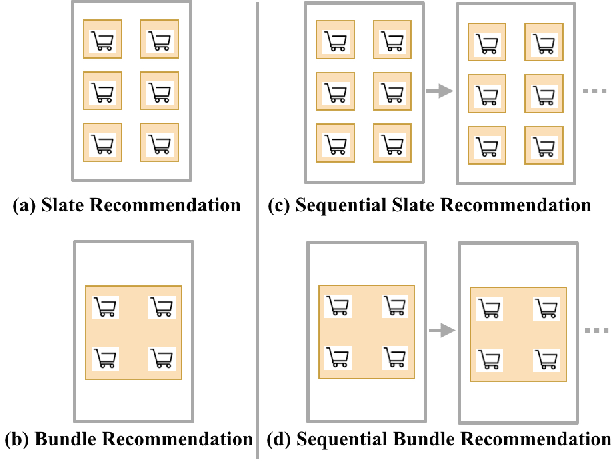
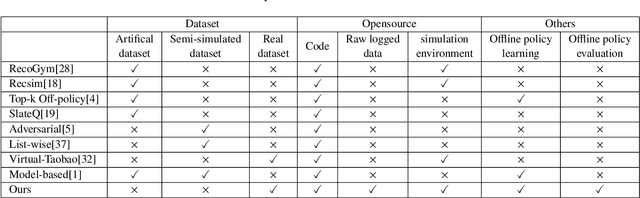
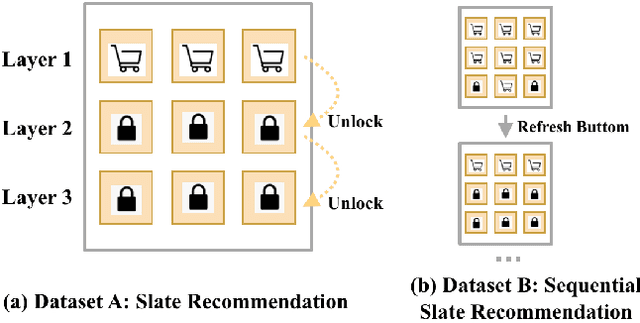
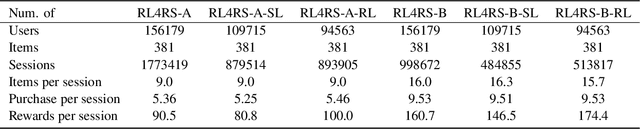
Reinforcement learning based recommender systems (RL-based RS) aims at learning a good policy from a batch of collected data, with casting sequential recommendation to multi-step decision-making tasks. However, current RL-based RS benchmarks commonly have a large reality gap, because they involve artificial RL datasets or semi-simulated RS datasets, and the trained policy is directly evaluated in the simulation environment. In real-world situations, not all recommendation problems are suitable to be transformed into reinforcement learning problems. Unlike previous academic RL researches, RL-based RS suffer from extrapolation error and the difficulties of being well validated before deployment. In this paper, we introduce the RL4RS (Reinforcement Learning for Recommender Systems) benchmark - a new resource fully collected from industrial applications to train and evaluate RL algorithms with special concerns on the above issues. It contains two datasets, tuned simulation environments, related advanced RL baselines, data understanding tools, and counterfactual policy evaluation algorithms. The RL4RS suit can be found at https://github.com/fuxiAIlab/RL4RS. In addition to the RL-based recommender systems, we expect the resource to contribute to research in reinforcement learning and neural combinatorial optimization.