 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMultimodal Prompt Transformer with Hybrid Contrastive Learning for Emotion Recognition in Conversation
Paper and Code
Oct 04, 2023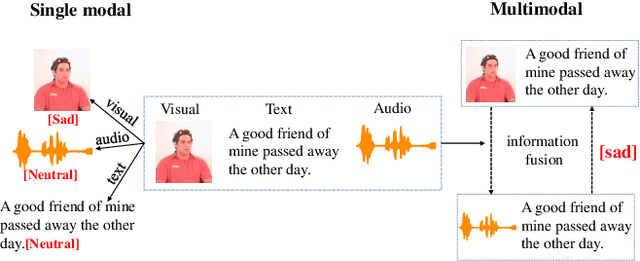
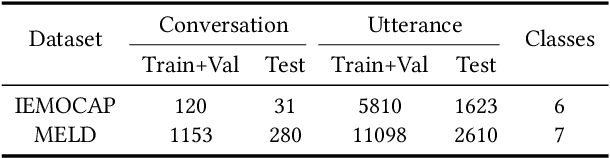
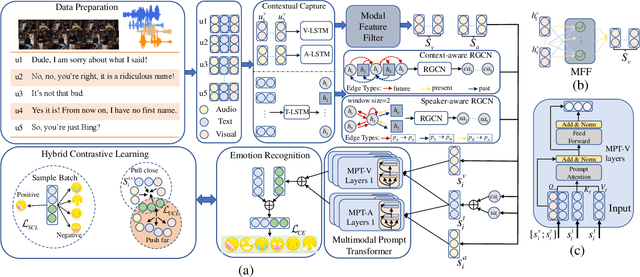

Emotion Recognition in Conversation (ERC) plays an important role in driving the development of human-machine interaction. Emotions can exist in multiple modalities, and multimodal ERC mainly faces two problems: (1) the noise problem in the cross-modal information fusion process, and (2) the prediction problem of less sample emotion labels that are semantically similar but different categories. To address these issues and fully utilize the features of each modality, we adopted the following strategies: first, deep emotion cues extraction was performed on modalities with strong representation ability, and feature filters were designed as multimodal prompt information for modalities with weak representation ability. Then, we designed a Multimodal Prompt Transformer (MPT) to perform cross-modal information fusion. MPT embeds multimodal fusion information into each attention layer of the Transformer, allowing prompt information to participate in encoding textual features and being fused with multi-level textual information to obtain better multimodal fusion features. Finally, we used the Hybrid Contrastive Learning (HCL) strategy to optimize the model's ability to handle labels with few samples. This strategy uses unsupervised contrastive learning to improve the representation ability of multimodal fusion and supervised contrastive learning to mine the information of labels with few samples. Experimental results show that our proposed model outperforms state-of-the-art models in ERC on two benchmark datasets.