 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOn The Impact of Machine Learning Randomness on Group Fairness
Jul 09, 2023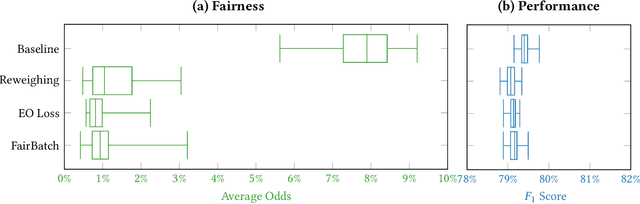
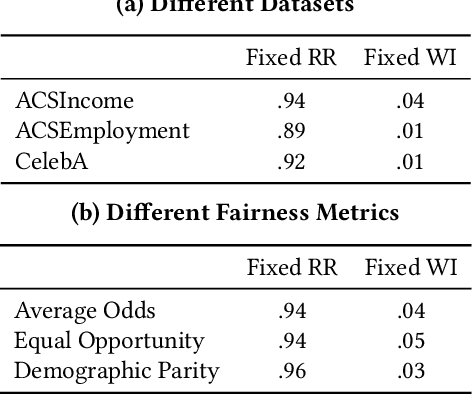
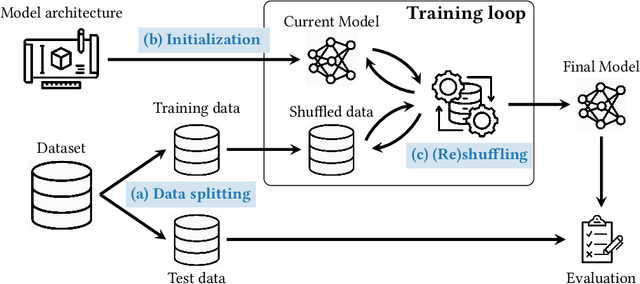
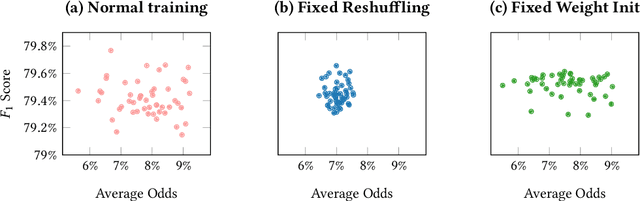
Statistical measures for group fairness in machine learning reflect the gap in performance of algorithms across different groups. These measures, however, exhibit a high variance between different training instances, which makes them unreliable for empirical evaluation of fairness. What causes this high variance? We investigate the impact on group fairness of different sources of randomness in training neural networks. We show that the variance in group fairness measures is rooted in the high volatility of the learning process on under-represented groups. Further, we recognize the dominant source of randomness as the stochasticity of data order during training. Based on these findings, we show how one can control group-level accuracy (i.e., model fairness), with high efficiency and negligible impact on the model's overall performance, by simply changing the data order for a single epoch.
Towards Regulatable AI Systems: Technical Gaps and Policy Opportunities
Jun 22, 2023There is increasing attention being given to how to regulate AI systems. As governing bodies grapple with what values to encapsulate into regulation, we consider the technical half of the question: To what extent can AI experts vet an AI system for adherence to regulatory requirements? We investigate this question through two public sector procurement checklists, identifying what we can do now, what we should be able to do with technical innovation in AI, and what requirements necessitate a more interdisciplinary approach.
Pushing the Accuracy-Group Robustness Frontier with Introspective Self-play
Feb 11, 2023Standard empirical risk minimization (ERM) training can produce deep neural network (DNN) models that are accurate on average but under-perform in under-represented population subgroups, especially when there are imbalanced group distributions in the long-tailed training data. Therefore, approaches that improve the accuracy-group robustness trade-off frontier of a DNN model (i.e. improving worst-group accuracy without sacrificing average accuracy, or vice versa) is of crucial importance. Uncertainty-based active learning (AL) can potentially improve the frontier by preferentially sampling underrepresented subgroups to create a more balanced training dataset. However, the quality of uncertainty estimates from modern DNNs tend to degrade in the presence of spurious correlations and dataset bias, compromising the effectiveness of AL for sampling tail groups. In this work, we propose Introspective Self-play (ISP), a simple approach to improve the uncertainty estimation of a deep neural network under dataset bias, by adding an auxiliary introspection task requiring a model to predict the bias for each data point in addition to the label. We show that ISP provably improves the bias-awareness of the model representation and the resulting uncertainty estimates. On two real-world tabular and language tasks, ISP serves as a simple "plug-in" for AL model training, consistently improving both the tail-group sampling rate and the final accuracy-fairness trade-off frontier of popular AL methods.
Data Privacy and Trustworthy Machine Learning
Sep 14, 2022



The privacy risks of machine learning models is a major concern when training them on sensitive and personal data. We discuss the tradeoffs between data privacy and the remaining goals of trustworthy machine learning (notably, fairness, robustness, and explainability).
* Copyright \copyright 2022, IEEE
High Dimensional Model Explanations: an Axiomatic Approach
Jun 16, 2020
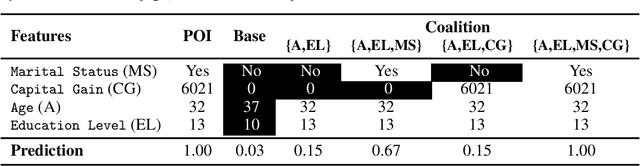

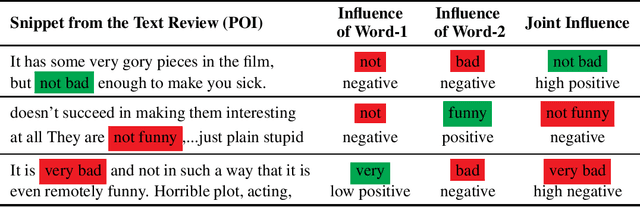
Complex black-box machine learning models are regularly used in critical decision-making domains. This has given rise to several calls for algorithmic explainability. Many explanation algorithms proposed in literature assign importance to each feature individually. However, such explanations fail to capture the joint effects of sets of features. Indeed, few works so far formally analyze \coloremph{high dimensional model explanations}. In this paper, we propose a novel high dimension model explanation method that captures the joint effect of feature subsets. We propose a new axiomatization for a generalization of the Banzhaf index; our method can also be thought of as an approximation of a black-box model by a higher-order polynomial. In other words, this work justifies the use of the generalized Banzhaf index as a model explanation by showing that it uniquely satisfies a set of natural desiderata and that it is the optimal local approximation of a black-box model. Our empirical evaluation of our measure highlights how it manages to capture desirable behavior, whereas other measures that do not satisfy our axioms behave in an unpredictable manner.
Privacy Risks of Explaining Machine Learning Models
Jun 29, 2019



Can we trust black-box machine learning with its decisions? Can we trust algorithms to train machine learning models on sensitive data? Transparency and privacy are two fundamental elements of trust for adopting machine learning. In this paper, we investigate the relation between interpretability and privacy. In particular we analyze if an adversary can exploit transparent machine learning to infer sensitive information about its training set. To this end, we perform membership inference as well as reconstruction attacks on two popular classes of algorithms for explaining machine learning models: feature-based and record-based influence measures. We empirically show that an attacker, that only observes the feature-based explanations, has the same power as the state of the art membership inference attacks on model predictions. We also demonstrate that record-based explanations can be effectively exploited to reconstruct significant parts of the training set. Finally, our results indicate that minorities and special cases are more vulnerable to these type of attacks than majority groups.
A Characterization of Monotone Influence Measures for Data Classification
Aug 07, 2017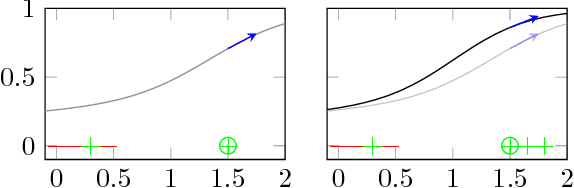


In this work we focus on the following question: how important was the i-th feature in determining the outcome for a given datapoint? We identify a family of influence measures; functions that, given a datapoint x, assign a value phi_i(x) to every feature i, which roughly corresponds to that i's importance in determining the outcome for x. This family is uniquely derived from a set of axioms: desirable properties that any reasonable influence measure should satisfy. Departing from prior work on influence measures, we assume no knowledge of - or access to - the underlying classifier labelling the dataset. In other words, our influence measures are based on the dataset alone, and do not make any queries to the classifier. While this requirement naturally limits the scope of explanations we provide, we show that it is effective on real datasets.