 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSnipper: A Spatiotemporal Transformer for Simultaneous Multi-Person 3D Pose Estimation Tracking and Forecasting on a Video Snippet
Paper and Code

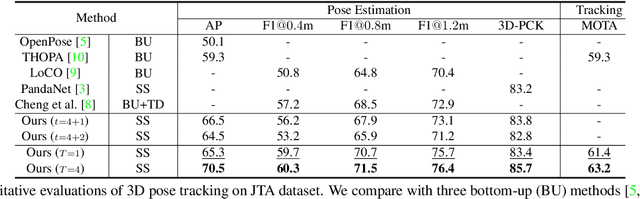
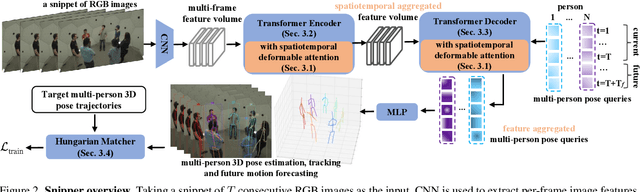
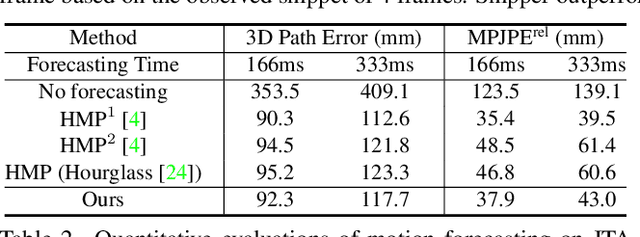
Multi-person pose understanding from RGB videos includes three complex tasks: pose estimation, tracking and motion forecasting. Among these three tasks, pose estimation and tracking are correlated, and tracking is crucial to motion forecasting. Most existing works either focus on a single task or employ cascaded methods to solve each individual task separately. In this paper, we propose Snipper, a framework to perform multi-person 3D pose estimation, tracking and motion forecasting simultaneously in a single inference. Specifically, we first propose a deformable attention mechanism to aggregate spatiotemporal information from video snippets. Building upon this deformable attention, a visual transformer is learned to encode the spatiotemporal features from multi-frame images and to decode informative pose features to update multi-person pose queries. Last, these queries are regressed to predict multi-person pose trajectories and future motions in one forward pass. In the experiments, we show the effectiveness of Snipper on three challenging public datasets where a generic model rivals specialized state-of-art baselines for pose estimation, tracking, and forecasting. Code is available at https://github.com/JimmyZou/Snipper