 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeQTIP: Quantization with Trellises and Incoherence Processing
Jun 17, 2024



Post-training quantization (PTQ) reduces the memory footprint of LLMs by quantizing weights to low-precision datatypes. Since LLM inference is usually memory-bound, PTQ methods can improve inference throughput. Recent state-of-the-art PTQ approaches have converged on using vector quantization (VQ) to quantize multiple weights at once, which improves information utilization through better shaping. However, VQ requires a codebook with size exponential in the dimension. This limits current VQ-based PTQ works to low VQ dimensions ($\le 8$) that in turn limit quantization quality. Here, we introduce QTIP, which instead uses trellis coded quantization (TCQ) to achieve ultra-high-dimensional quantization. TCQ uses a stateful decoder that separates the codebook size from the bitrate and effective dimension. QTIP introduces a spectrum of lookup-only to computed lookup-free trellis codes designed for a hardware-efficient "bitshift" trellis structure; these codes achieve state-of-the-art results in both quantization quality and inference speed.
QuIP#: Even Better LLM Quantization with Hadamard Incoherence and Lattice Codebooks
Feb 06, 2024Post-training quantization (PTQ) reduces the memory footprint of LLMs by quantizing their weights to low-precision. In this work, we introduce QuIP#, a weight-only PTQ method that achieves state-of-the-art results in extreme compression regimes ($\le$ 4 bits per weight) using three novel techniques. First, QuIP# improves the incoherence processing from QuIP by using the randomized Hadamard transform, which is faster and has better theoretical properties. Second, QuIP# uses vector quantization techniques to take advantage of the ball-shaped sub-Gaussian distribution that incoherent weights possess: specifically, we introduce a set of hardware-efficient codebooks based on the highly symmetric $E_8$ lattice, which achieves the optimal 8-dimension unit ball packing. Third, QuIP# uses fine-tuning to improve fidelity to the original model. Our experiments show that QuIP# outperforms existing PTQ methods, enables new behaviors in PTQ scaling, and supports fast inference.
Beyond Invariance: Test-Time Label-Shift Adaptation for Distributions with "Spurious" Correlations
Nov 28, 2022Spurious correlations, or correlations that change across domains where a model can be deployed, present significant challenges to real-world applications of machine learning models. However, such correlations are not always "spurious"; often, they provide valuable prior information for a prediction beyond what can be extracted from the input alone. Here, we present a test-time adaptation method that exploits the spurious correlation phenomenon, in contrast to recent approaches that attempt to eliminate spurious correlations through invariance. We consider situations where the prior distribution $p(y, z)$, which models the marginal dependence between the class label $y$ and the nuisance factors $z$, may change across domains, but the generative model for features $p(\mathbf{x}|y, z)$ is constant. We note that this is an expanded version of the label shift assumption, where the labels now also include the nuisance factors $z$. Based on this observation, we train a classifier to predict $p(y, z|\mathbf{x})$ on the source distribution, and implement a test-time label shift correction that adapts to changes in the marginal distribution $p(y, z)$ using unlabeled samples from the target domain. We call our method "Test-Time Label-Shift Adaptation" or TTLSA. We apply our method to two different image datasets -- the CheXpert chest X-ray dataset and the colored MNIST dataset -- and show that it gives better downstream results than methods that try to train classifiers which are invariant to the changes in prior distribution. Code reproducing experiments is available at https://github.com/nalzok/test-time-label-shift .
Individualized and Global Feature Attributions for Gradient Boosted Trees in the Presence of $\ell_2$ Regularization
Nov 08, 2022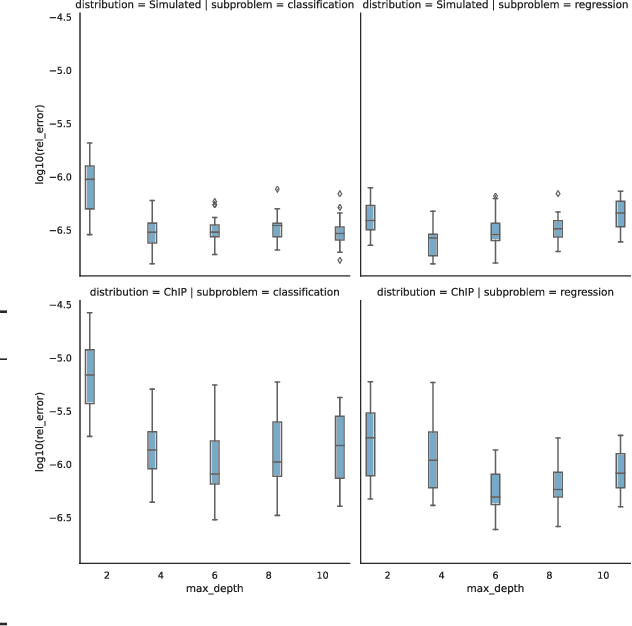
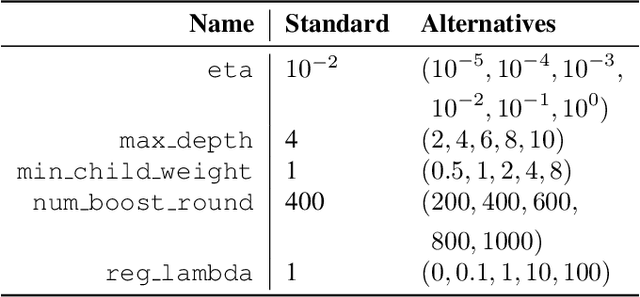
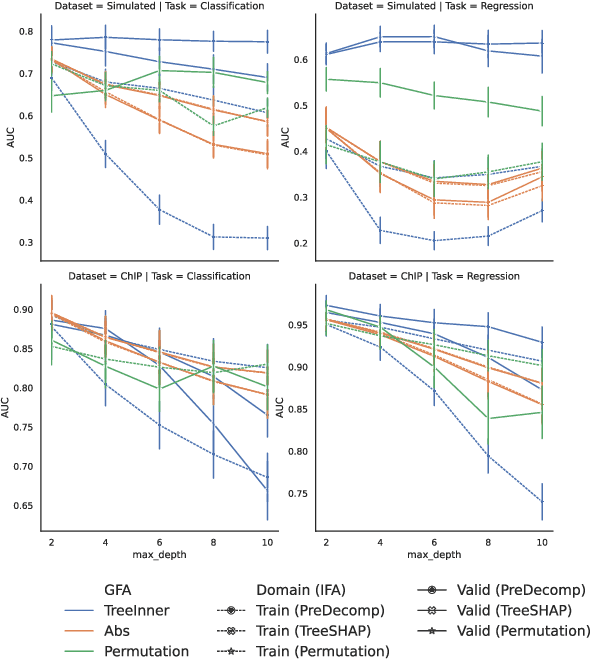
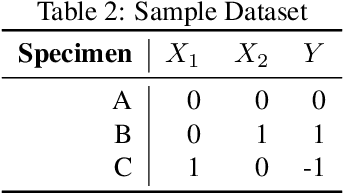
While $\ell_2$ regularization is widely used in training gradient boosted trees, popular individualized feature attribution methods for trees such as Saabas and TreeSHAP overlook the training procedure. We propose Prediction Decomposition Attribution (PreDecomp), a novel individualized feature attribution for gradient boosted trees when they are trained with $\ell_2$ regularization. Theoretical analysis shows that the inner product between PreDecomp and labels on in-sample data is essentially the total gain of a tree, and that it can faithfully recover additive models in the population case when features are independent. Inspired by the connection between PreDecomp and total gain, we also propose TreeInner, a family of debiased global feature attributions defined in terms of the inner product between any individualized feature attribution and labels on out-sample data for each tree. Numerical experiments on a simulated dataset and a genomic ChIP dataset show that TreeInner has state-of-the-art feature selection performance. Code reproducing experiments is available at https://github.com/nalzok/TreeInner .
Action2Motion: Conditioned Generation of 3D Human Motions
Jul 30, 2020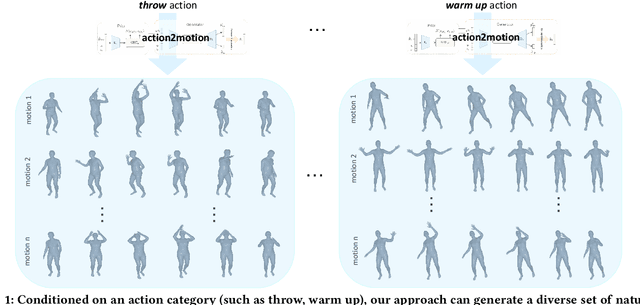
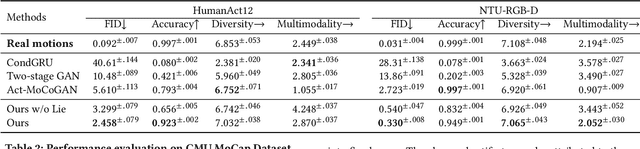
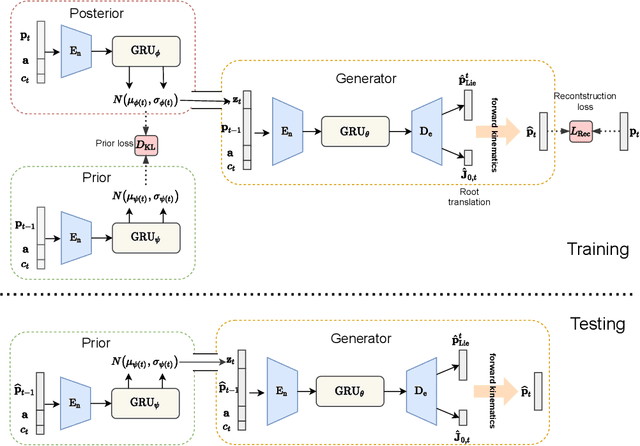
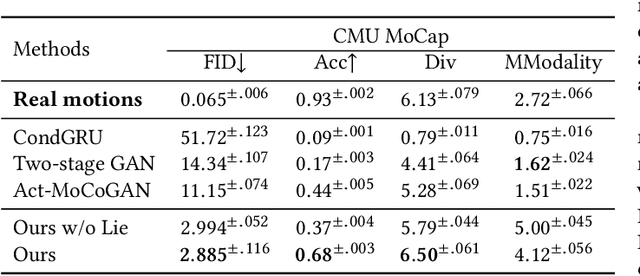
Action recognition is a relatively established task, where givenan input sequence of human motion, the goal is to predict its ac-tion category. This paper, on the other hand, considers a relativelynew problem, which could be thought of as an inverse of actionrecognition: given a prescribed action type, we aim to generateplausible human motion sequences in 3D. Importantly, the set ofgenerated motions are expected to maintain itsdiversityto be ableto explore the entire action-conditioned motion space; meanwhile,each sampled sequence faithfully resembles anaturalhuman bodyarticulation dynamics. Motivated by these objectives, we followthe physics law of human kinematics by adopting the Lie Algebratheory to represent thenaturalhuman motions; we also propose atemporal Variational Auto-Encoder (VAE) that encourages adiversesampling of the motion space. A new 3D human motion dataset, HumanAct12, is also constructed. Empirical experiments overthree distinct human motion datasets (including ours) demonstratethe effectiveness of our approach.