 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeL$^3$: Large Lookup Layers
Jan 29, 2026Modern sparse language models typically achieve sparsity through Mixture-of-Experts (MoE) layers, which dynamically route tokens to dense MLP "experts." However, dynamic hard routing has a number of drawbacks, such as potentially poor hardware efficiency and needing auxiliary losses for stable training. In contrast, the tokenizer embedding table, which is natively sparse, largely avoids these issues by selecting a single embedding per token at the cost of not having contextual information. In this work, we introduce the Large Lookup Layer (L$^3$), which unlocks a new axis of sparsity by generalizing embedding tables to model decoder layers. L$^3$ layers use static token-based routing to aggregate a set of learned embeddings per token in a context-dependent way, allowing the model to efficiently balance memory and compute by caching information in embeddings. L$^3$ has two main components: (1) a systems-friendly architecture that allows for fast training and CPU-offloaded inference with no overhead, and (2) an information-theoretic embedding allocation algorithm that effectively balances speed and quality. We empirically test L$^3$ by training transformers with up to 2.6B active parameters and find that L$^3$ strongly outperforms both dense models and iso-sparse MoEs in both language modeling and downstream tasks.
Model-Preserving Adaptive Rounding
May 29, 2025

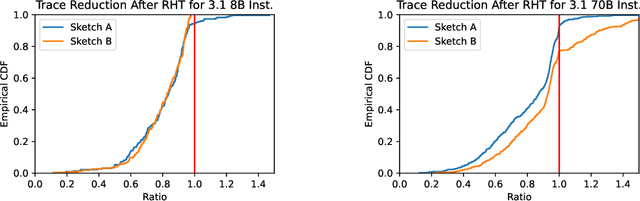

The main goal of post-training quantization (PTQ) is to produced a compressed model whose output distribution is as close to the original model's as possible. To do this tractably, almost all LLM PTQ algorithms quantize linear layers by independently minimizing the immediate activation error. However, this localized objective ignores the effect of subsequent layers, so reducing it does not necessarily give a closer model. In this work, we introduce Yet Another Quantization Algorithm (YAQA), an adaptive rounding algorithm that uses Kronecker-factored approximations of each linear layer's Hessian with respect to the \textit{full model} KL divergence. YAQA consists of two components: Kronecker-factored sketches of the full layerwise Hessian that can be tractably computed for hundred-billion parameter LLMs, and a quantizer-independent rounding algorithm that uses these sketches and comes with theoretical guarantees. Across a wide range of models and quantizers, YAQA empirically reduces the KL divergence to the original model by $\approx 30\%$ while achieving state of the art performance on downstream tasks.
Training LLMs with MXFP4
Feb 27, 2025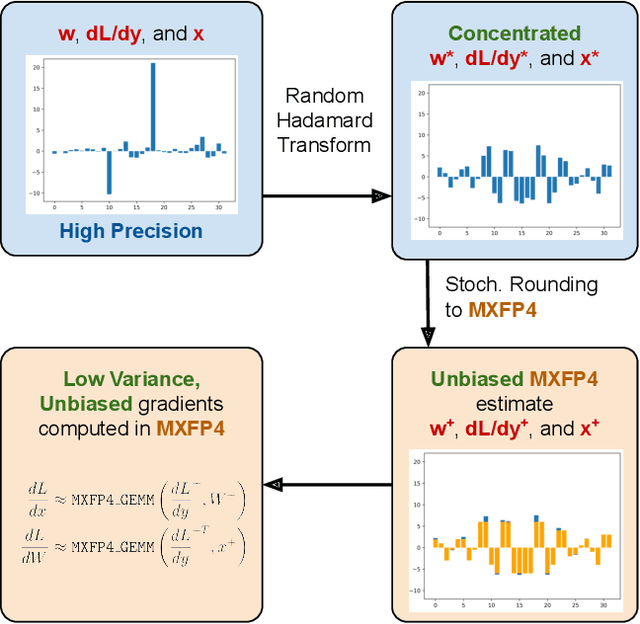

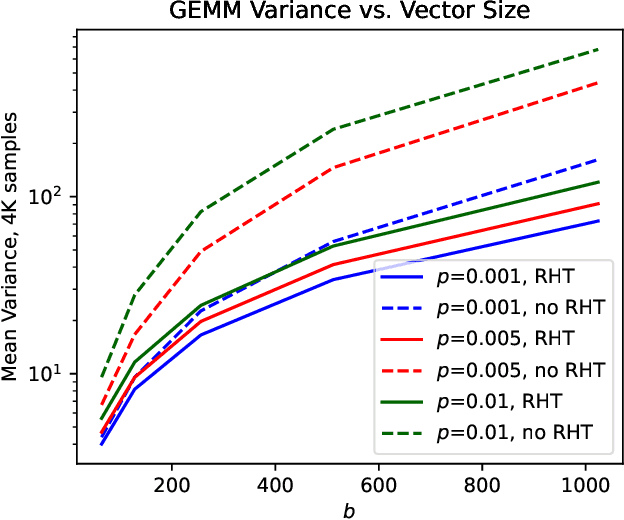
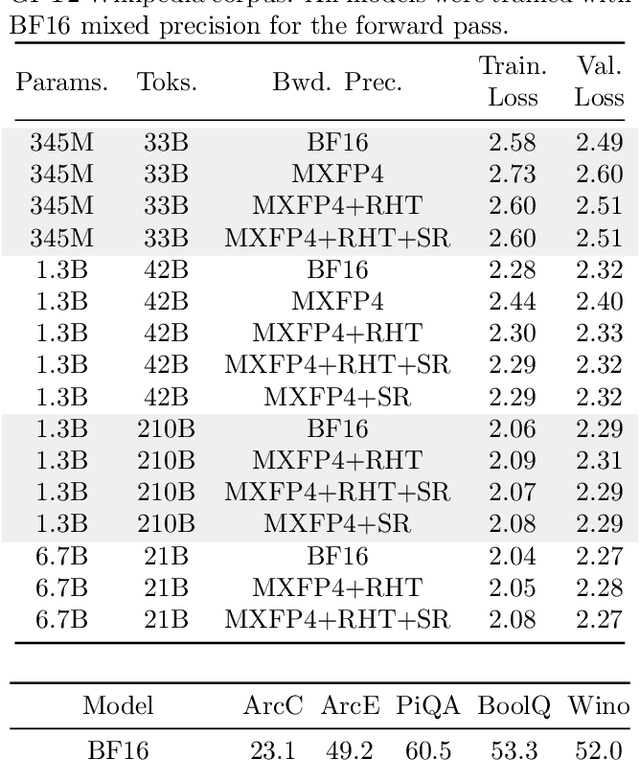
Low precision (LP) datatypes such as MXFP4 can accelerate matrix multiplications (GEMMs) and reduce training costs. However, directly using MXFP4 instead of BF16 during training significantly degrades model quality. In this work, we present the first near-lossless training recipe that uses MXFP4 GEMMs, which are $2\times$ faster than FP8 on supported hardware. Our key insight is to compute unbiased gradient estimates with stochastic rounding (SR), resulting in more accurate model updates. However, directly applying SR to MXFP4 can result in high variance from block-level outliers, harming convergence. To overcome this, we use the random Hadamard tranform to theoretically bound the variance of SR. We train GPT models up to 6.7B parameters and find that our method induces minimal degradation over mixed-precision BF16 training. Our recipe computes $>1/2$ the training FLOPs in MXFP4, enabling an estimated speedup of $>1.3\times$ over FP8 and $>1.7\times$ over BF16 during backpropagation.
QTIP: Quantization with Trellises and Incoherence Processing
Jun 17, 2024



Post-training quantization (PTQ) reduces the memory footprint of LLMs by quantizing weights to low-precision datatypes. Since LLM inference is usually memory-bound, PTQ methods can improve inference throughput. Recent state-of-the-art PTQ approaches have converged on using vector quantization (VQ) to quantize multiple weights at once, which improves information utilization through better shaping. However, VQ requires a codebook with size exponential in the dimension. This limits current VQ-based PTQ works to low VQ dimensions ($\le 8$) that in turn limit quantization quality. Here, we introduce QTIP, which instead uses trellis coded quantization (TCQ) to achieve ultra-high-dimensional quantization. TCQ uses a stateful decoder that separates the codebook size from the bitrate and effective dimension. QTIP introduces a spectrum of lookup-only to computed lookup-free trellis codes designed for a hardware-efficient "bitshift" trellis structure; these codes achieve state-of-the-art results in both quantization quality and inference speed.
QuIP#: Even Better LLM Quantization with Hadamard Incoherence and Lattice Codebooks
Feb 06, 2024Post-training quantization (PTQ) reduces the memory footprint of LLMs by quantizing their weights to low-precision. In this work, we introduce QuIP#, a weight-only PTQ method that achieves state-of-the-art results in extreme compression regimes ($\le$ 4 bits per weight) using three novel techniques. First, QuIP# improves the incoherence processing from QuIP by using the randomized Hadamard transform, which is faster and has better theoretical properties. Second, QuIP# uses vector quantization techniques to take advantage of the ball-shaped sub-Gaussian distribution that incoherent weights possess: specifically, we introduce a set of hardware-efficient codebooks based on the highly symmetric $E_8$ lattice, which achieves the optimal 8-dimension unit ball packing. Third, QuIP# uses fine-tuning to improve fidelity to the original model. Our experiments show that QuIP# outperforms existing PTQ methods, enables new behaviors in PTQ scaling, and supports fast inference.
Coneheads: Hierarchy Aware Attention
Jun 01, 2023



Attention networks such as transformers have achieved state-of-the-art performance in many domains. These networks rely heavily on the dot product attention operator, which computes the similarity between two points by taking their inner product. However, the inner product does not explicitly model the complex structural properties of real world datasets, such as hierarchies between data points. To remedy this, we introduce cone attention, a drop-in replacement for dot product attention based on hyperbolic entailment cones. Cone attention associates two points by the depth of their lowest common ancestor in a hierarchy defined by hyperbolic cones, which intuitively measures the divergence of two points and gives a hierarchy aware similarity score. We test cone attention on a wide variety of models and tasks and show that it improves task-level performance over dot product attention and other baselines, and is able to match dot-product attention with significantly fewer parameters. Our results suggest that cone attention is an effective way to capture hierarchical relationships when calculating attention.
Shadow Cones: Unveiling Partial Orders in Hyperbolic Space
May 24, 2023Hyperbolic space has been shown to produce superior low-dimensional embeddings of hierarchical structures that are unattainable in Euclidean space. Building upon this, the entailment cone formulation of Ganea et al. uses geodesically convex cones to embed partial orderings in hyperbolic space. However, these entailment cones lack intuitive interpretations due to their definitions via complex concepts such as tangent vectors and the exponential map in Riemannian space. In this paper, we present shadow cones, an innovative framework that provides a physically intuitive interpretation for defining partial orders on general manifolds. This is achieved through the use of metaphoric light sources and object shadows, inspired by the sun-earth-moon relationship. Shadow cones consist of two primary classes: umbral and penumbral cones. Our results indicate that shadow cones offer robust representation and generalization capabilities across a variety of datasets, such as WordNet and ConceptNet, thereby outperforming the top-performing entailment cones. Our findings indicate that shadow cones offer an innovative, general approach to geometrically encode partial orders, enabling better representation and analysis of datasets with hierarchical structures.
Automatic Synthesis of Diverse Weak Supervision Sources for Behavior Analysis
Nov 30, 2021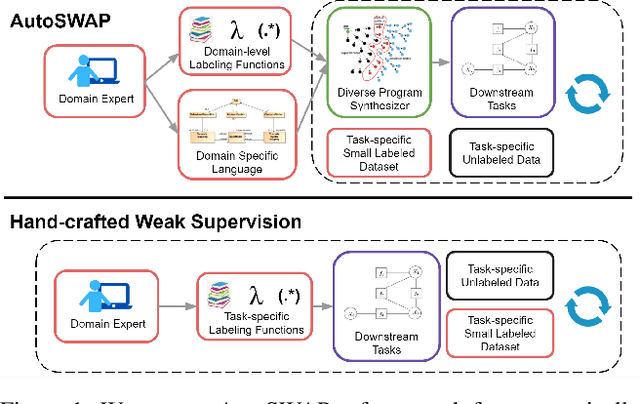



Obtaining annotations for large training sets is expensive, especially in behavior analysis settings where domain knowledge is required for accurate annotations. Weak supervision has been studied to reduce annotation costs by using weak labels from task-level labeling functions to augment ground truth labels. However, domain experts are still needed to hand-craft labeling functions for every studied task. To reduce expert effort, we present AutoSWAP: a framework for automatically synthesizing data-efficient task-level labeling functions. The key to our approach is to efficiently represent expert knowledge in a reusable domain specific language and domain-level labeling functions, with which we use state-of-the-art program synthesis techniques and a small labeled dataset to generate labeling functions. Additionally, we propose a novel structural diversity cost that allows for direct synthesis of diverse sets of labeling functions with minimal overhead, further improving labeling function data efficiency. We evaluate AutoSWAP in three behavior analysis domains and demonstrate that AutoSWAP outperforms existing approaches using only a fraction of the data. Our results suggest that AutoSWAP is an effective way to automatically generate labeling functions that can significantly reduce expert effort for behavior analysis.
Learning Calibratable Policies using Programmatic Style-Consistency
Oct 02, 2019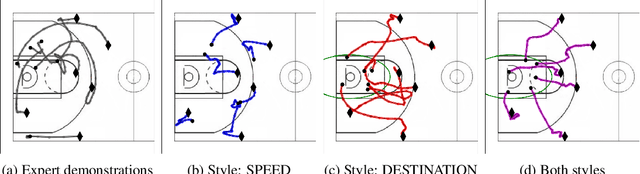
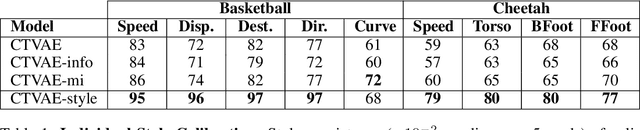
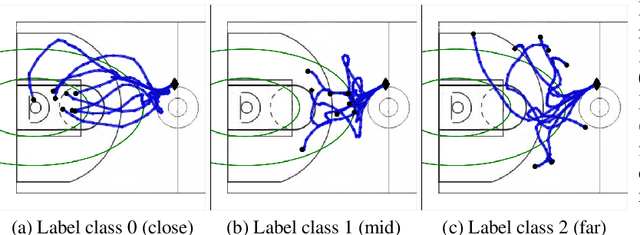
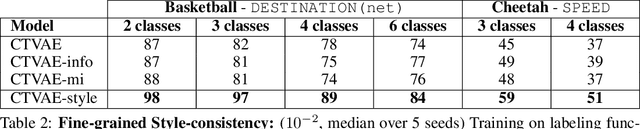
We study the important and challenging problem of controllable generation of long-term sequential behaviors. Solutions to this problem would impact many applications, such as calibrating behaviors of AI agents in games or predicting player trajectories in sports. In contrast to the well-studied areas of controllable generation of images, text, and speech, there are significant challenges that are unique to or exacerbated by generating long-term behaviors: how should we specify the factors of variation to control, and how can we ensure that the generated temporal behavior faithfully demonstrates diverse styles? In this paper, we leverage large amounts of raw behavioral data to learn policies that can be calibrated to generate a diverse range of behavior styles (e.g., aggressive versus passive play in sports). Inspired by recent work on leveraging programmatic labeling functions, we present a novel framework that combines imitation learning with data programming to learn style-calibratable policies. Our primary technical contribution is a formal notion of style-consistency as a learning objective, and its integration with conventional imitation learning approaches. We evaluate our framework using demonstrations from professional basketball players and agents in the MuJoCo physics environment, and show that our learned policies can be accurately calibrated to generate interesting behavior styles in both domains.