 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeVPNeXt -- Rethinking Dense Decoding for Plain Vision Transformer
Feb 25, 2025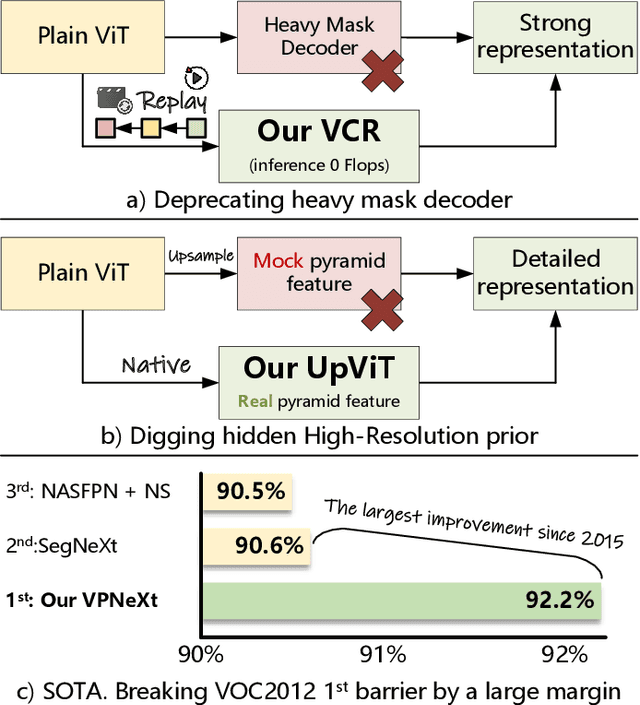



We present VPNeXt, a new and simple model for the Plain Vision Transformer (ViT). Unlike the many related studies that share the same homogeneous paradigms, VPNeXt offers a fresh perspective on dense representation based on ViT. In more detail, the proposed VPNeXt addressed two concerns about the existing paradigm: (1) Is it necessary to use a complex Transformer Mask Decoder architecture to obtain good representations? (2) Does the Plain ViT really need to depend on the mock pyramid feature for upsampling? For (1), we investigated the potential underlying reasons that contributed to the effectiveness of the Transformer Decoder and introduced the Visual Context Replay (VCR) to achieve similar effects efficiently. For (2), we introduced the ViTUp module. This module fully utilizes the previously overlooked ViT real pyramid feature to achieve better upsampling results compared to the earlier mock pyramid feature. This represents the first instance of such functionality in the field of semantic segmentation for Plain ViT. We performed ablation studies on related modules to verify their effectiveness gradually. We conducted relevant comparative experiments and visualizations to show that VPNeXt achieved state-of-the-art performance with a simple and effective design. Moreover, the proposed VPNeXt significantly exceeded the long-established mIoU wall/barrier of the VOC2012 dataset, setting a new state-of-the-art by a large margin, which also stands as the largest improvement since 2015.
NIPD: A Federated Learning Person Detection Benchmark Based on Real-World Non-IID Data
Jun 28, 2023Federated learning (FL), a privacy-preserving distributed machine learning, has been rapidly applied in wireless communication networks. FL enables Internet of Things (IoT) clients to obtain well-trained models while preventing privacy leakage. Person detection can be deployed on edge devices with limited computing power if combined with FL to process the video data directly at the edge. However, due to the different hardware and deployment scenarios of different cameras, the data collected by the camera present non-independent and identically distributed (non-IID), and the global model derived from FL aggregation is less effective. Meanwhile, existing research lacks public data set for real-world FL object detection, which is not conducive to studying the non-IID problem on IoT cameras. Therefore, we open source a non-IID IoT person detection (NIPD) data set, which is collected from five different cameras. To our knowledge, this is the first true device-based non-IID person detection data set. Based on this data set, we explain how to establish a FL experimental platform and provide a benchmark for non-IID person detection. NIPD is expected to promote the application of FL and the security of smart city.
A Multi-task Joint Framework for Real-time Person Search
Dec 11, 2020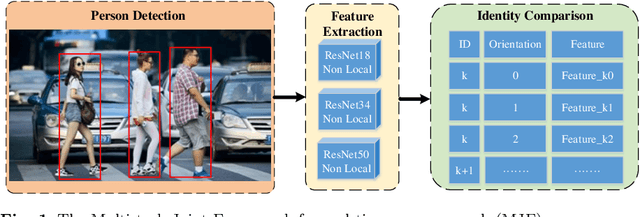
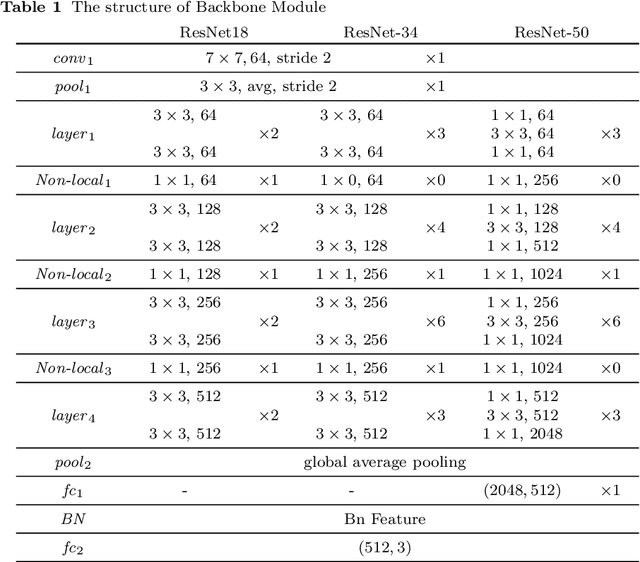
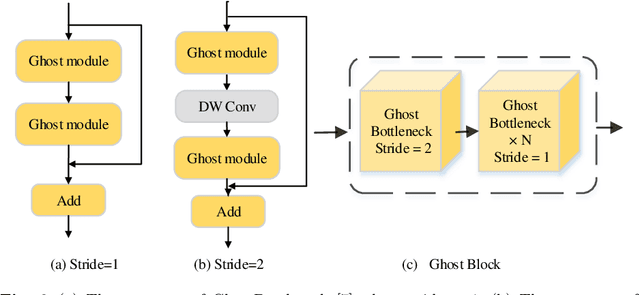

Person search generally involves three important parts: person detection, feature extraction and identity comparison. However, person search integrating detection, extraction and comparison has the following drawbacks. Firstly, the accuracy of detection will affect the accuracy of comparison. Secondly, it is difficult to achieve real-time in real-world applications. To solve these problems, we propose a Multi-task Joint Framework for real-time person search (MJF), which optimizes the person detection, feature extraction and identity comparison respectively. For the person detection module, we proposed the YOLOv5-GS model, which is trained with person dataset. It combines the advantages of the Ghostnet and the Squeeze-and-Excitation (SE) block, and improves the speed and accuracy. For the feature extraction module, we design the Model Adaptation Architecture (MAA), which could select different network according to the number of people. It could balance the relationship between accuracy and speed. For identity comparison, we propose a Three Dimension (3D) Pooled Table and a matching strategy to improve identification accuracy. On the condition of 1920*1080 resolution video and 500 IDs table, the identification rate (IR) and frames per second (FPS) achieved by our method could reach 93.6% and 25.7,
Triplet Online Instance Matching Loss for Person Re-identification
Feb 24, 2020


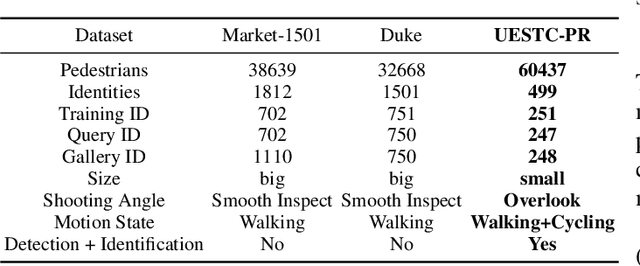
Mining the shared features of same identity in different scene, and the unique features of different identity in same scene, are most significant challenges in the field of person re-identification (ReID). Online Instance Matching (OIM) loss function and Triplet loss function are main methods for person ReID. Unfortunately, both of them have drawbacks. OIM loss treats all samples equally and puts no emphasis on hard samples. Triplet loss processes batch construction in a complicated and fussy way and converges slowly. For these problems, we propose a Triplet Online Instance Matching (TOIM) loss function, which lays emphasis on the hard samples and improves the accuracy of person ReID effectively. It combines the advantages of OIM loss and Triplet loss and simplifies the process of batch construction, which leads to a more rapid convergence. It can be trained on-line when handle the joint detection and identification task. To validate our loss function, we collect and annotate a large-scale benchmark dataset (UESTC-PR) based on images taken from surveillance cameras, which contains 499 identities and 60,437 images. We evaluated our proposed loss function on Duke, Marker-1501 and UESTC-PR using ResNet-50, and the result shows that our proposed loss function outperforms the baseline methods by a maximum of 21.7%, including Softmax loss, OIM loss and Triplet loss.