 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeShedding the Facades, Connecting the Domains: Detecting Shifting Multimodal Hate Video with Test-Time Adaptation
Jan 28, 2026Hate Video Detection (HVD) is crucial for online ecosystems. Existing methods assume identical distributions between training (source) and inference (target) data. However, hateful content often evolves into irregular and ambiguous forms to evade censorship, resulting in substantial semantic drift and rendering previously trained models ineffective. Test-Time Adaptation (TTA) offers a solution by adapting models during inference to narrow the cross-domain gap, while conventional TTA methods target mild distribution shifts and struggle with the severe semantic drift in HVD. To tackle these challenges, we propose SCANNER, the first TTA framework tailored for HVD. Motivated by the insight that, despite the evolving nature of hateful manifestations, their underlying cores remain largely invariant (i.e., targeting is still based on characteristics like gender, race, etc), we leverage these stable cores as a bridge to connect the source and target domains. Specifically, SCANNER initially reveals the stable cores from the ambiguous layout in evolving hateful content via a principled centroid-guided alignment mechanism. To alleviate the impact of outlier-like samples that are weakly correlated with centroids during the alignment process, SCANNER enhances the prior by incorporating a sample-level adaptive centroid alignment strategy, promoting more stable adaptation. Furthermore, to mitigate semantic collapse from overly uniform outputs within clusters, SCANNER introduces an intra-cluster diversity regularization that encourages the cluster-wise semantic richness. Experiments show that SCANNER outperforms all baselines, with an average gain of 4.69% in Macro-F1 over the best.
VPNeXt -- Rethinking Dense Decoding for Plain Vision Transformer
Feb 25, 2025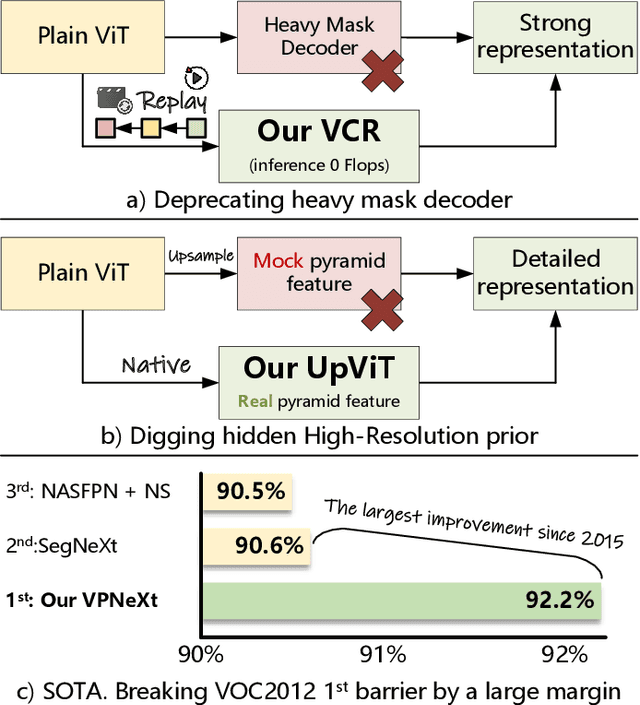



We present VPNeXt, a new and simple model for the Plain Vision Transformer (ViT). Unlike the many related studies that share the same homogeneous paradigms, VPNeXt offers a fresh perspective on dense representation based on ViT. In more detail, the proposed VPNeXt addressed two concerns about the existing paradigm: (1) Is it necessary to use a complex Transformer Mask Decoder architecture to obtain good representations? (2) Does the Plain ViT really need to depend on the mock pyramid feature for upsampling? For (1), we investigated the potential underlying reasons that contributed to the effectiveness of the Transformer Decoder and introduced the Visual Context Replay (VCR) to achieve similar effects efficiently. For (2), we introduced the ViTUp module. This module fully utilizes the previously overlooked ViT real pyramid feature to achieve better upsampling results compared to the earlier mock pyramid feature. This represents the first instance of such functionality in the field of semantic segmentation for Plain ViT. We performed ablation studies on related modules to verify their effectiveness gradually. We conducted relevant comparative experiments and visualizations to show that VPNeXt achieved state-of-the-art performance with a simple and effective design. Moreover, the proposed VPNeXt significantly exceeded the long-established mIoU wall/barrier of the VOC2012 dataset, setting a new state-of-the-art by a large margin, which also stands as the largest improvement since 2015.