 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLucky High Dynamic Range Smartphone Imaging
Apr 21, 2026While the human eye can perceive an impressive twenty stops of dynamic range, smartphone camera sensors remain limited to about twelve stops despite decades of research. A variety of high dynamic range (HDR) image capture and processing techniques have been proposed, and, in practice, they can extend the dynamic range by 3-5 stops for handheld photography. This paper proposes an approach that robustly captures dynamic range using a handheld smartphone camera and lightweight networks suitable for running on mobile devices. Our method operates indirectly on linear raw pixels in bracketed exposures. Every pixel in the final HDR image is a convex combination of input pixels in the neighborhood, adjusted for exposure, and thus avoids hallucination artifacts typical of recent deep image synthesis networks. We validate our system on both synthetic imagery and unseen real bracketed images -- we confirm zero-shot generalization of the method to smartphone camera captures. Our iterative inference architecture is capable of processing an arbitrary number of bracketed input photos, and we show examples from capture stacks containing 3--9 images. Our training process relies only on synthetic captures yet generalizes to unseen real photos from several cameras. Moreover, we show that this training scheme improves other SOTA methods over their pretrained counterparts.
CORN: Co-Trained Full-Reference And No-Reference Audio Metrics
Oct 13, 2023


Perceptual evaluation constitutes a crucial aspect of various audio-processing tasks. Full reference (FR) or similarity-based metrics rely on high-quality reference recordings, to which lower-quality or corrupted versions of the recording may be compared for evaluation. In contrast, no-reference (NR) metrics evaluate a recording without relying on a reference. Both the FR and NR approaches exhibit advantages and drawbacks relative to each other. In this paper, we present a novel framework called CORN that amalgamates these dual approaches, concurrently training both FR and NR models together. After training, the models can be applied independently. We evaluate CORN by predicting several common objective metrics and across two different architectures. The NR model trained using CORN has access to a reference recording during training, and thus, as one would expect, it consistently outperforms baseline NR models trained independently. Perhaps even more remarkable is that the CORN FR model also outperforms its baseline counterpart, even though it relies on the same training data and the same model architecture. Thus, a single training regime produces two independently useful models, each outperforming independently trained models.
Audio Similarity is Unreliable as a Proxy for Audio Quality
Jun 27, 2022



Many audio processing tasks require perceptual assessment. However, the time and expense of obtaining ``gold standard'' human judgments limit the availability of such data. Most applications incorporate full reference or other similarity-based metrics (e.g. PESQ) that depend on a clean reference. Researchers have relied on such metrics to evaluate and compare various proposed methods, often concluding that small, measured differences imply one is more effective than another. This paper demonstrates several practical scenarios where similarity metrics fail to agree with human perception, because they: (1) vary with clean references; (2) rely on attributes that humans factor out when considering quality, and (3) are sensitive to imperceptible signal level differences. In those scenarios, we show that no-reference metrics do not suffer from such shortcomings and correlate better with human perception. We conclude therefore that similarity serves as an unreliable proxy for audio quality.
CDPAM: Contrastive learning for perceptual audio similarity
Feb 09, 2021



Many speech processing methods based on deep learning require an automatic and differentiable audio metric for the loss function. The DPAM approach of Manocha et al. learns a full-reference metric trained directly on human judgments, and thus correlates well with human perception. However, it requires a large number of human annotations and does not generalize well outside the range of perturbations on which it was trained. This paper introduces CDPAM, a metric that builds on and advances DPAM. The primary improvement is to combine contrastive learning and multi-dimensional representations to build robust models from limited data. In addition, we collect human judgments on triplet comparisons to improve generalization to a broader range of audio perturbations. CDPAM correlates well with human responses across nine varied datasets. We also show that adding this metric to existing speech synthesis and enhancement methods yields significant improvement, as measured by objective and subjective tests.
Learning from Shader Program Traces
Feb 08, 2021

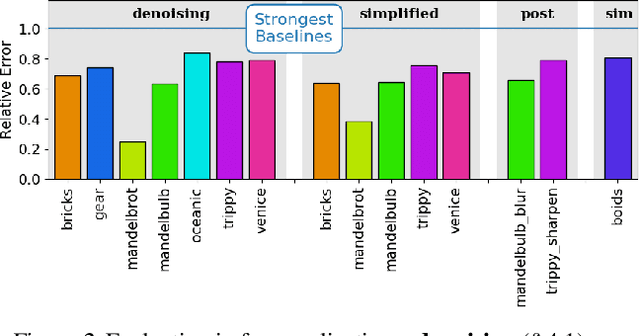
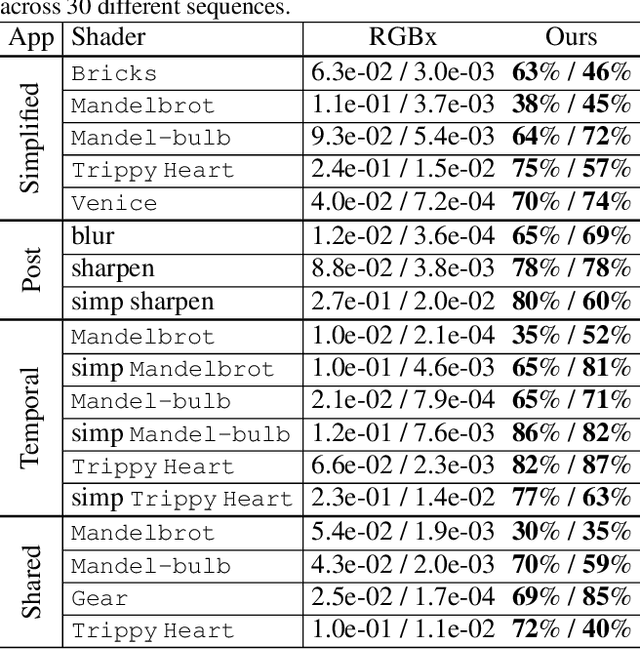
Deep networks for image processing typically learn from RGB pixels. This paper proposes instead to learn from program traces, the intermediate values computed during program execution. We study this idea in the context of pixel~shaders -- programs that generate images, typically running in parallel (for each pixel) on GPU hardware. The intermediate values computed at each pixel during program execution form the input to the learned model. In a variety of applications, models learned from program traces outperform baseline models learned from RGB, even when augmented with hand-picked shader-specific features. We also investigate strategies for selecting a subset of trace features for learning; using just a small subset of the trace still outperforms the baselines.
HiFi-GAN: High-Fidelity Denoising and Dereverberation Based on Speech Deep Features in Adversarial Networks
Jun 10, 2020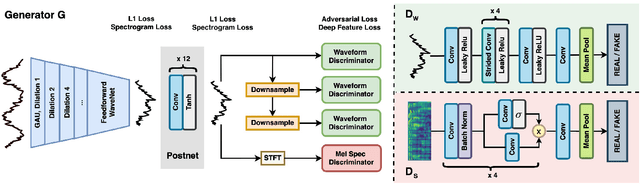
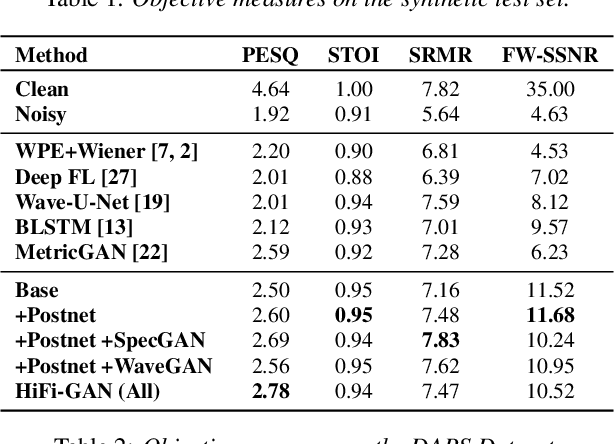
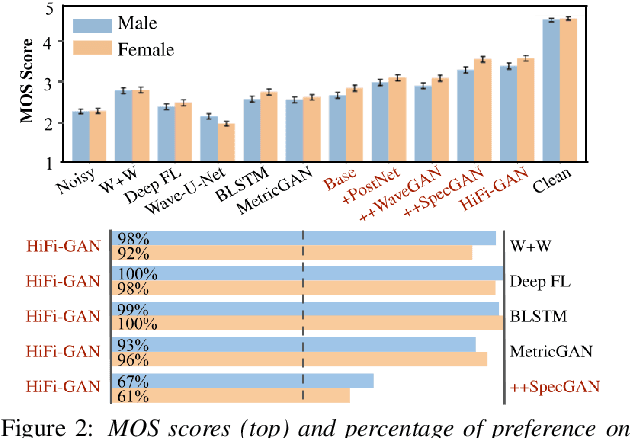
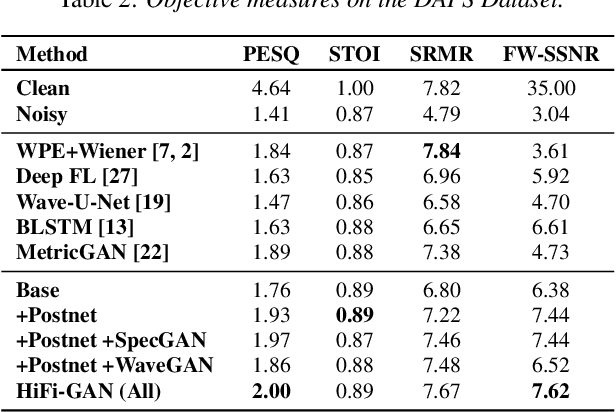
Real-world audio recordings are often degraded by factors such as noise, reverberation, and equalization distortion. This paper introduces HiFi-GAN, a deep learning method to transform recorded speech to sound as though it had been recorded in a studio. We use an end-to-end feed-forward WaveNet architecture, trained with multi-scale adversarial discriminators in both the time domain and the time-frequency domain. It relies on the deep feature matching losses of the discriminators to improve the perceptual quality of enhanced speech. The proposed model generalizes well to new speakers, new speech content, and new environments. It significantly outperforms state-of-the-art baseline methods in both objective and subjective experiments.
Text-based Editing of Talking-head Video
Jun 04, 2019
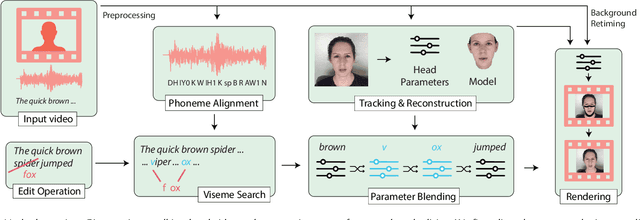
Editing talking-head video to change the speech content or to remove filler words is challenging. We propose a novel method to edit talking-head video based on its transcript to produce a realistic output video in which the dialogue of the speaker has been modified, while maintaining a seamless audio-visual flow (i.e. no jump cuts). Our method automatically annotates an input talking-head video with phonemes, visemes, 3D face pose and geometry, reflectance, expression and scene illumination per frame. To edit a video, the user has to only edit the transcript, and an optimization strategy then chooses segments of the input corpus as base material. The annotated parameters corresponding to the selected segments are seamlessly stitched together and used to produce an intermediate video representation in which the lower half of the face is rendered with a parametric face model. Finally, a recurrent video generation network transforms this representation to a photorealistic video that matches the edited transcript. We demonstrate a large variety of edits, such as the addition, removal, and alteration of words, as well as convincing language translation and full sentence synthesis.
High-Precision Localization Using Ground Texture
Sep 18, 2018


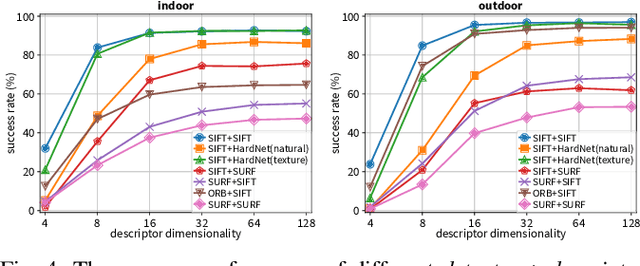
Location-aware applications play an increasingly critical role in everyday life. However, satellite-based localization (e.g., GPS) has limited accuracy and can be unusable in dense urban areas and indoors. We introduce an image-based global localization system that is accurate to a few millimeters and performs reliable localization both indoors and outside. The key idea is to capture and index distinctive local keypoints in ground textures. This is based on the observation that ground textures including wood, carpet, tile, concrete, and asphalt may look random and homogeneous, but all contain cracks, scratches, or unique arrangements of fibers. These imperfections are persistent, and can serve as local features. Our system incorporates a downward-facing camera to capture the fine texture of the ground, together with an image processing pipeline that locates the captured texture patch in a compact database constructed offline. We demonstrate the capability of our system to robustly, accurately, and quickly locate test images on various types of outdoor and indoor ground surfaces.
TurkerGaze: Crowdsourcing Saliency with Webcam based Eye Tracking
May 20, 2015

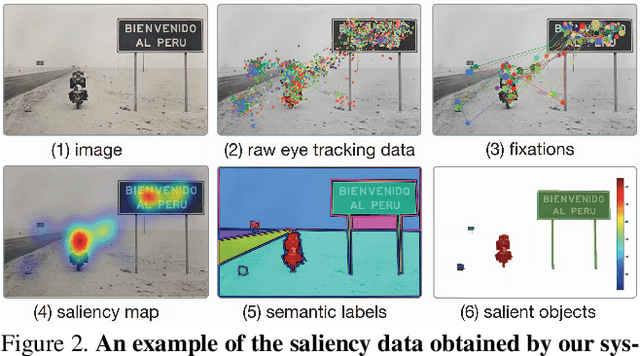
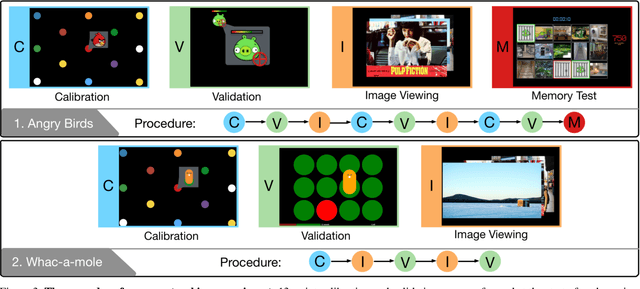
Traditional eye tracking requires specialized hardware, which means collecting gaze data from many observers is expensive, tedious and slow. Therefore, existing saliency prediction datasets are order-of-magnitudes smaller than typical datasets for other vision recognition tasks. The small size of these datasets limits the potential for training data intensive algorithms, and causes overfitting in benchmark evaluation. To address this deficiency, this paper introduces a webcam-based gaze tracking system that supports large-scale, crowdsourced eye tracking deployed on Amazon Mechanical Turk (AMTurk). By a combination of careful algorithm and gaming protocol design, our system obtains eye tracking data for saliency prediction comparable to data gathered in a traditional lab setting, with relatively lower cost and less effort on the part of the researchers. Using this tool, we build a saliency dataset for a large number of natural images. We will open-source our tool and provide a web server where researchers can upload their images to get eye tracking results from AMTurk.