 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFinancial Data Analysis with Robust Federated Logistic Regression
Apr 28, 2025In this study, we focus on the analysis of financial data in a federated setting, wherein data is distributed across multiple clients or locations, and the raw data never leaves the local devices. Our primary focus is not only on the development of efficient learning frameworks (for protecting user data privacy) in the field of federated learning but also on the importance of designing models that are easier to interpret. In addition, we care about the robustness of the framework to outliers. To achieve these goals, we propose a robust federated logistic regression-based framework that strives to strike a balance between these goals. To verify the feasibility of our proposed framework, we carefully evaluate its performance not only on independently identically distributed (IID) data but also on non-IID data, especially in scenarios involving outliers. Extensive numerical results collected from multiple public datasets demonstrate that our proposed method can achieve comparable performance to those of classical centralized algorithms, such as Logistical Regression, Decision Tree, and K-Nearest Neighbors, in both binary and multi-class classification tasks.
DASA: Delay-Adaptive Multi-Agent Stochastic Approximation
Mar 28, 2024

We consider a setting in which $N$ agents aim to speedup a common Stochastic Approximation (SA) problem by acting in parallel and communicating with a central server. We assume that the up-link transmissions to the server are subject to asynchronous and potentially unbounded time-varying delays. To mitigate the effect of delays and stragglers while reaping the benefits of distributed computation, we propose \texttt{DASA}, a Delay-Adaptive algorithm for multi-agent Stochastic Approximation. We provide a finite-time analysis of \texttt{DASA} assuming that the agents' stochastic observation processes are independent Markov chains. Significantly advancing existing results, \texttt{DASA} is the first algorithm whose convergence rate depends only on the mixing time $\tau_{mix}$ and on the average delay $\tau_{avg}$ while jointly achieving an $N$-fold convergence speedup under Markovian sampling. Our work is relevant for various SA applications, including multi-agent and distributed temporal difference (TD) learning, Q-learning and stochastic optimization with correlated data.
Byzantine-Robust Clustered Federated Learning
Jun 01, 2023This paper focuses on the problem of adversarial attacks from Byzantine machines in a Federated Learning setting where non-Byzantine machines can be partitioned into disjoint clusters. In this setting, non-Byzantine machines in the same cluster have the same underlying data distribution, and different clusters of non-Byzantine machines have different learning tasks. Byzantine machines can adversarially attack any cluster and disturb the training process on clusters they attack. In the presence of Byzantine machines, the goal of our work is to identify cluster membership of non-Byzantine machines and optimize the models learned by each cluster. We adopt the Iterative Federated Clustering Algorithm (IFCA) framework of Ghosh et al. (2020) to alternatively estimate cluster membership and optimize models. In order to make this framework robust against adversarial attacks from Byzantine machines, we use coordinate-wise trimmed mean and coordinate-wise median aggregation methods used by Yin et al. (2018). Specifically, we propose a new Byzantine-Robust Iterative Federated Clustering Algorithm to improve on the results in Ghosh et al. (2019). We prove a convergence rate for this algorithm for strongly convex loss functions. We compare our convergence rate with the convergence rate of an existing algorithm, and we demonstrate the performance of our algorithm on simulated data.
Federated Learning with Downlink Device Selection
Jul 07, 2021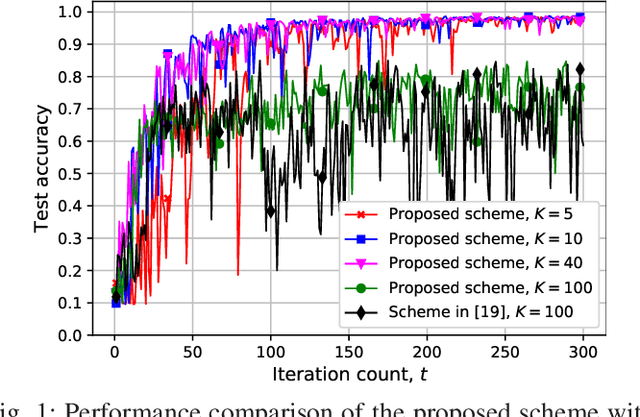
We study federated edge learning, where a global model is trained collaboratively using privacy-sensitive data at the edge of a wireless network. A parameter server (PS) keeps track of the global model and shares it with the wireless edge devices for training using their private local data. The devices then transmit their local model updates, which are used to update the global model, to the PS. The algorithm, which involves transmission over PS-to-device and device-to-PS links, continues until the convergence of the global model or lack of any participating devices. In this study, we consider device selection based on downlink channels over which the PS shares the global model with the devices. Performing digital downlink transmission, we design a partial device participation framework where a subset of the devices is selected for training at each iteration. Therefore, the participating devices can have a better estimate of the global model compared to the full device participation case which is due to the shared nature of the broadcast channel with the price of updating the global model with respect to a smaller set of data. At each iteration, the PS broadcasts different quantized global model updates to different participating devices based on the last global model estimates available at the devices. We investigate the best number of participating devices through experimental results for image classification using the MNIST dataset with biased distribution.
A System for Efficiently Hunting for Cyber Threats in Computer Systems Using Threat Intelligence
Jan 17, 2021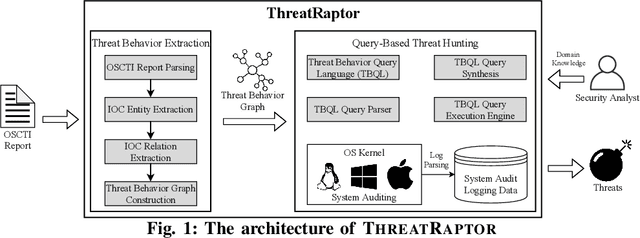


Log-based cyber threat hunting has emerged as an important solution to counter sophisticated cyber attacks. However, existing approaches require non-trivial efforts of manual query construction and have overlooked the rich external knowledge about threat behaviors provided by open-source Cyber Threat Intelligence (OSCTI). To bridge the gap, we build ThreatRaptor, a system that facilitates cyber threat hunting in computer systems using OSCTI. Built upon mature system auditing frameworks, ThreatRaptor provides (1) an unsupervised, light-weight, and accurate NLP pipeline that extracts structured threat behaviors from unstructured OSCTI text, (2) a concise and expressive domain-specific query language, TBQL, to hunt for malicious system activities, (3) a query synthesis mechanism that automatically synthesizes a TBQL query from the extracted threat behaviors, and (4) an efficient query execution engine to search the big system audit logging data.
Enabling Efficient Cyber Threat Hunting With Cyber Threat Intelligence
Oct 26, 2020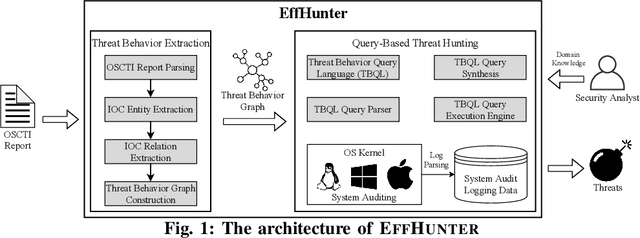



Log-based cyber threat hunting has emerged as an important solution to counter sophisticated cyber attacks. However, existing approaches require non-trivial efforts of manual query construction and have overlooked the rich external knowledge about threat behaviors provided by open-source Cyber Threat Intelligence (OSCTI). To bridge the gap, we propose EffHunter, a system that facilitates cyber threat hunting in computer systems using OSCTI. Built upon mature system auditing frameworks, EffHunter provides (1) an unsupervised, light-weight, and accurate NLP pipeline that extracts structured threat behaviors from unstructured OSCTI text, (2) a concise and expressive domain-specific query language, TBQL, to hunt for malicious system activities, (3) a query synthesis mechanism that automatically synthesizes a TBQL query for threat hunting from the extracted threat behaviors, and (4) an efficient query execution engine to search the big audit logging data. Evaluations on a broad set of attack cases demonstrate the accuracy and efficiency of EffHunter in enabling practical threat hunting.
Blind Federated Edge Learning
Oct 19, 2020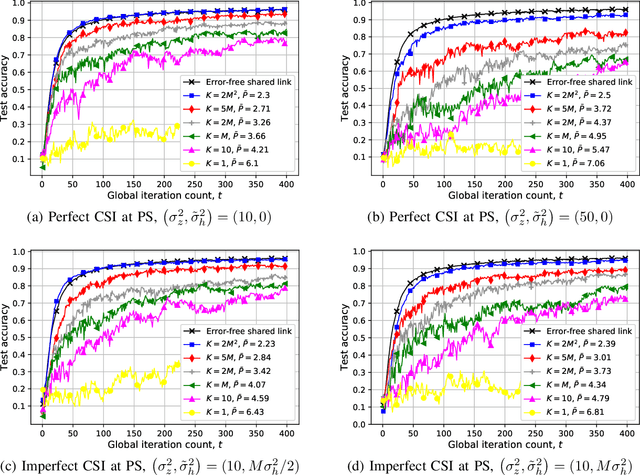

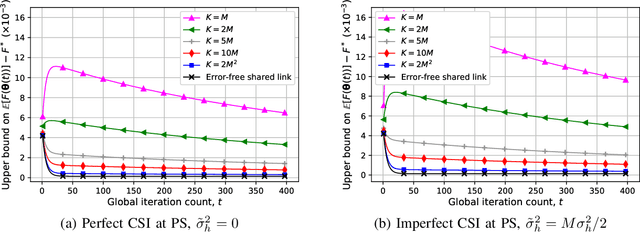
We study federated edge learning (FEEL), where wireless edge devices, each with its own dataset, learn a global model collaboratively with the help of a wireless access point acting as the parameter server (PS). At each iteration, wireless devices perform local updates using their local data and the most recent global model received from the PS, and send their local updates to the PS over a wireless fading multiple access channel (MAC). The PS then updates the global model according to the signal received over the wireless MAC, and shares it with the devices. Motivated by the additive nature of the wireless MAC, we propose an analog `over-the-air' aggregation scheme, in which the devices transmit their local updates in an uncoded fashion. Unlike recent literature on over-the-air edge learning, here we assume that the devices do not have channel state information (CSI), while the PS has imperfect CSI. Instead, the PS is equipped multiple antennas to alleviate the destructive effect of the channel, exacerbated due to the lack of perfect CSI. We design a receive beamforming scheme at the PS, and show that it can compensate for the lack of perfect CSI when the PS has a sufficient number of antennas. We also derive the convergence rate of the proposed algorithm highlighting the impact of the lack of perfect CSI, as well as the number of PS antennas. Both the experimental results and the convergence analysis illustrate the performance improvement of the proposed algorithm with the number of PS antennas, where the wireless fading MAC becomes deterministic despite the lack of perfect CSI when the PS has a sufficiently large number of antennas.
Convergence of Federated Learning over a Noisy Downlink
Aug 25, 2020
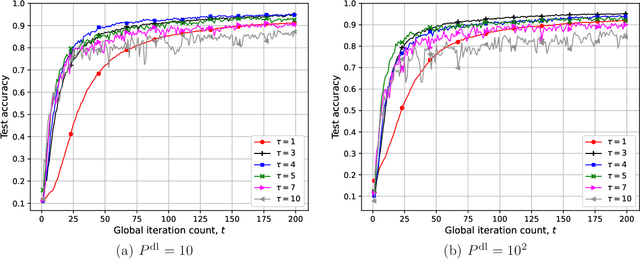
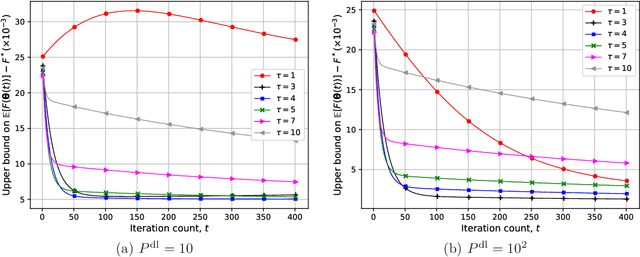
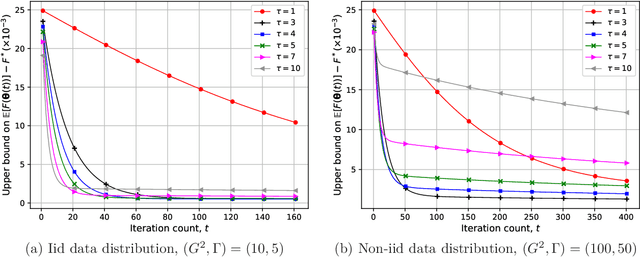
We study federated learning (FL), where power-limited wireless devices utilize their local datasets to collaboratively train a global model with the help of a remote parameter server (PS). The PS has access to the global model and shares it with the devices for local training, and the devices return the result of their local updates to the PS to update the global model. This framework requires downlink transmission from the PS to the devices and uplink transmission from the devices to the PS. The goal of this study is to investigate the impact of the bandwidth-limited shared wireless medium in both the downlink and uplink on the performance of FL with a focus on the downlink. To this end, the downlink and uplink channels are modeled as fading broadcast and multiple access channels, respectively, both with limited bandwidth. For downlink transmission, we first introduce a digital approach, where a quantization technique is employed at the PS to broadcast the global model update at a common rate such that all the devices can decode it. Next, we propose analog downlink transmission, where the global model is broadcast by the PS in an uncoded manner. We consider analog transmission over the uplink in both cases. We further analyze the convergence behavior of the proposed analog approach assuming that the uplink transmission is error-free. Numerical experiments show that the analog downlink approach provides significant improvement over the digital one, despite a significantly lower transmit power at the PS. The experimental results corroborate the convergence results, and show that a smaller number of local iterations should be used when the data distribution is more biased, and also when the devices have a better estimate of the global model in the analog downlink approach.
Federated Learning With Quantized Global Model Updates
Jun 18, 2020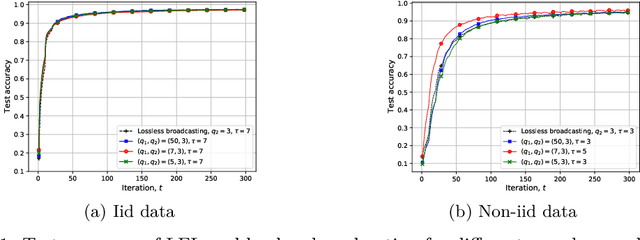
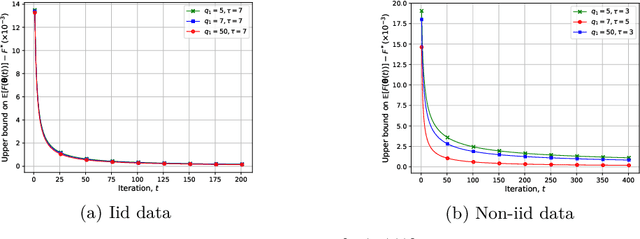
We study federated learning (FL), which enables mobile devices to utilize their local datasets to collaboratively train a global model with the help of a central server, while keeping data localized. At each iteration, the server broadcasts the current global model to the devices for local training, and aggregates the local model updates from the devices to update the global model. Previous work on the communication efficiency of FL has mainly focused on the aggregation of model updates from the devices, assuming perfect broadcasting of the global model. In this paper, we instead consider broadcasting a compressed version of the global model. This is to further reduce the communication cost of FL, which can be particularly limited when the global model is to be transmitted over a wireless medium. We introduce a lossy FL (LFL) algorithm, in which both the global model and the local model updates are quantized before being transmitted. We analyze the convergence behavior of the proposed LFL algorithm assuming the availability of accurate local model updates at the server. Numerical experiments show that the quantization of the global model can actually improve the performance for non-iid data distributions. This observation is corroborated with analytical convergence results.
Update Aware Device Scheduling for Federated Learning at the Wireless Edge
Jan 28, 2020
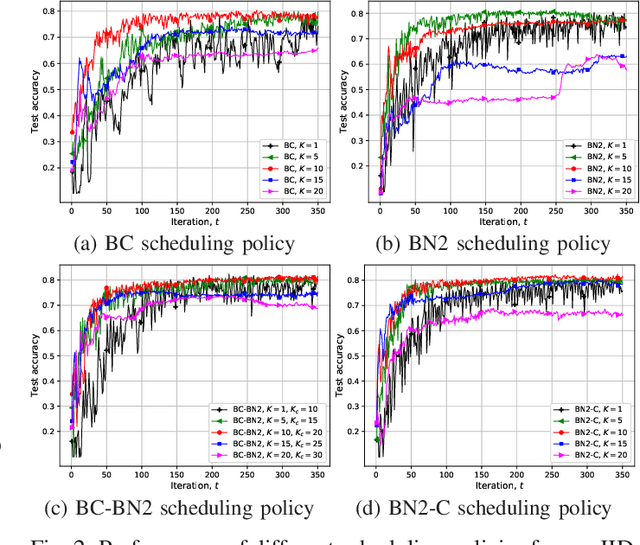
We study federated learning (FL) at the wireless edge, where power-limited devices with local datasets train a joint model with the help of a remote parameter server (PS). We assume that the devices are connected to the PS through a bandwidth-limited shared wireless channel. At each iteration of FL, a subset of the devices are scheduled to transmit their local model updates to the PS over orthogonal channel resources. We design novel scheduling policies, that decide on the subset of devices to transmit at each round not only based on their channel conditions, but also on the significance of their local model updates. Numerical results show that the proposed scheduling policy provides a better long-term performance than scheduling policies based only on either of the two metrics individually. We also observe that when the data is independent and identically distributed (i.i.d.) across devices, selecting a single device at each round provides the best performance, while when the data distribution is non-i.i.d., more devices should be scheduled.