 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeUpdate Estimation and Scheduling for Over-the-Air Federated Learning with Energy Harvesting Devices
Jan 30, 2025We study over-the-air (OTA) federated learning (FL) for energy harvesting devices with heterogeneous data distribution over wireless fading multiple access channel (MAC). To address the impact of low energy arrivals and data heterogeneity on global learning, we propose user scheduling strategies. Specifically, we develop two approaches: 1) entropy-based scheduling for known data distributions and 2) least-squares-based user representation estimation for scheduling with unknown data distributions at the parameter server. Both methods aim to select diverse users, mitigating bias and enhancing convergence. Numerical and analytical results demonstrate improved learning performance by reducing redundancy and conserving energy.
Next Generation Advanced Transceiver Technologies for 6G
Mar 25, 2024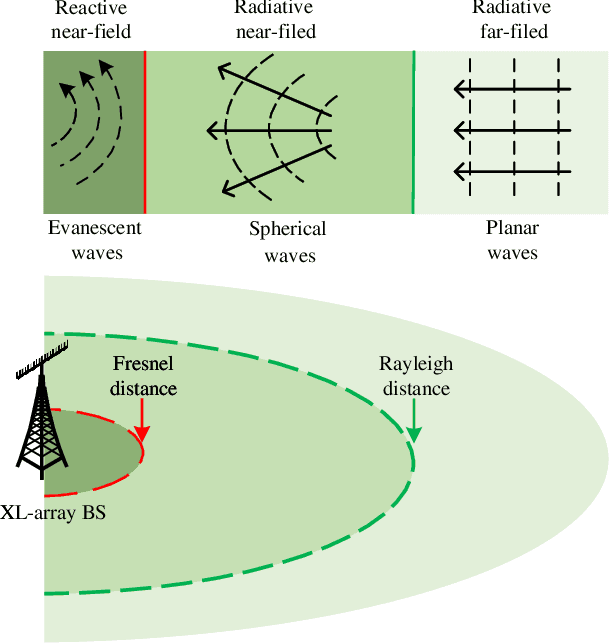

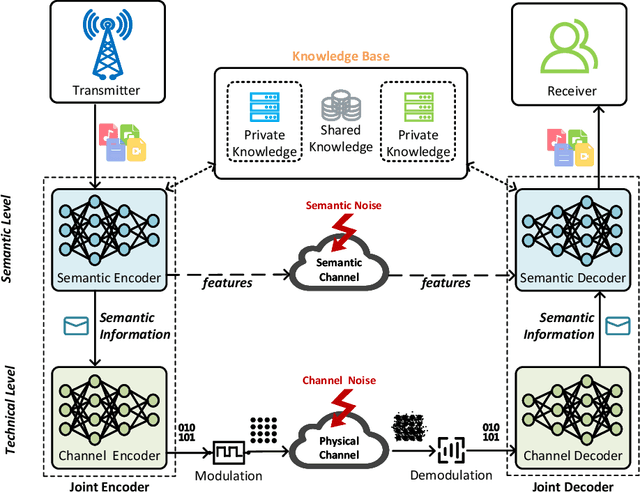
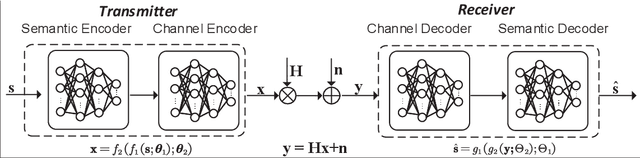
To accommodate new applications such as extended reality, fully autonomous vehicular networks and the metaverse, next generation wireless networks are going to be subject to much more stringent performance requirements than the fifth-generation (5G) in terms of data rates, reliability, latency, and connectivity. It is thus necessary to develop next generation advanced transceiver (NGAT) technologies for efficient signal transmission and reception. In this tutorial, we explore the evolution of NGAT from three different perspectives. Specifically, we first provide an overview of new-field NGAT technology, which shifts from conventional far-field channel models to new near-field channel models. Then, three new-form NGAT technologies and their design challenges are presented, including reconfigurable intelligent surfaces, flexible antennas, and holographic multi-input multi-output (MIMO) systems. Subsequently, we discuss recent advances in semantic-aware NGAT technologies, which can utilize new metrics for advanced transceiver designs. Finally, we point out other promising transceiver technologies for future research.
Over-the-Air Federated Edge Learning with Hierarchical Clustering
Jul 19, 2022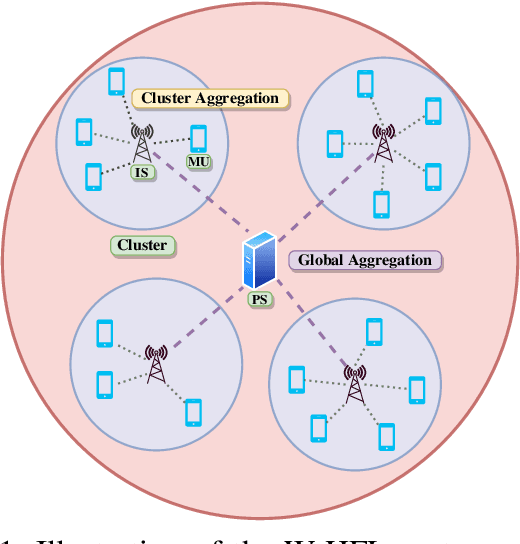

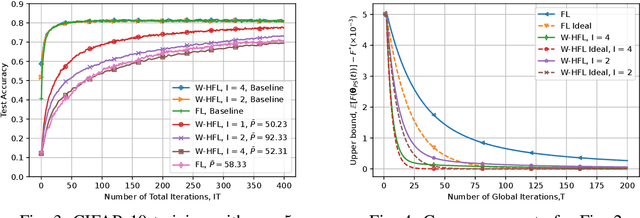
We examine federated learning (FL) with over-the-air (OTA) aggregation, where mobile users (MUs) aim to reach a consensus on a global model with the help of a parameter server (PS) that aggregates the local gradients. In OTA FL, MUs train their models using local data at every training round and transmit their gradients simultaneously using the same frequency band in an uncoded fashion. Based on the received signal of the superposed gradients, the PS performs a global model update. While the OTA FL has a significantly decreased communication cost, it is susceptible to adverse channel effects and noise. Employing multiple antennas at the receiver side can reduce these effects, yet the path-loss is still a limiting factor for users located far away from the PS. To ameliorate this issue, in this paper, we propose a wireless-based hierarchical FL scheme that uses intermediate servers (ISs) to form clusters at the areas where the MUs are more densely located. Our scheme utilizes OTA cluster aggregations for the communication of the MUs with their corresponding IS, and OTA global aggregations from the ISs to the PS. We present a convergence analysis for the proposed algorithm, and show through numerical evaluations of the derived analytical expressions and experimental results that utilizing ISs results in a faster convergence and a better performance than the OTA FL alone while using less transmit power. We also validate the results on the performance using different number of cluster iterations with different datasets and data distributions. We conclude that the best choice of cluster aggregations depends on the data distribution among the MUs and the clusters.
Hierarchical Over-the-Air Federated Edge Learning
Dec 21, 2021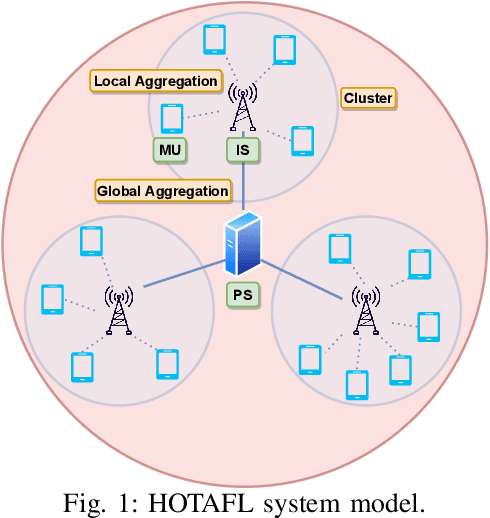
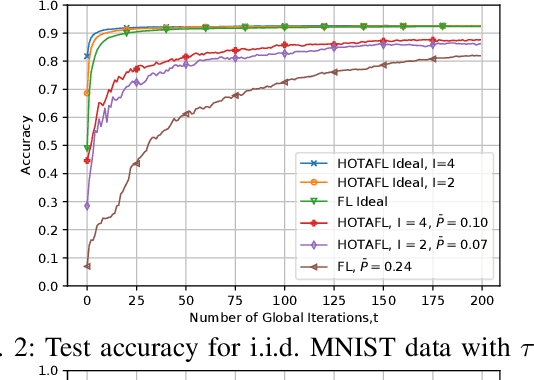
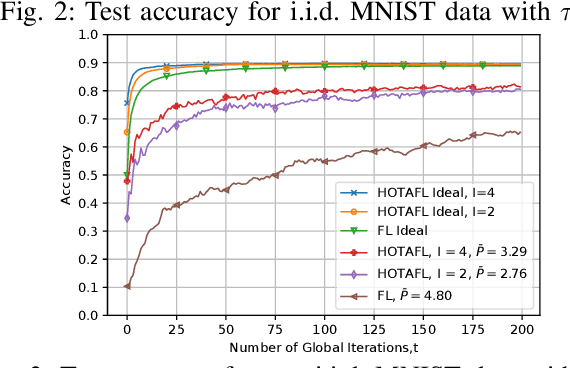
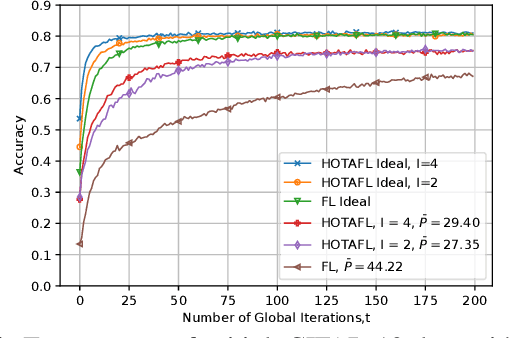
Federated learning (FL) over wireless communication channels, specifically, over-the-air (OTA) model aggregation framework is considered. In OTA wireless setups, the adverse channel effects can be alleviated by increasing the number of receive antennas at the parameter server (PS), which performs model aggregation. However, the performance of OTA FL is limited by the presence of mobile users (MUs) located far away from the PS. In this paper, to mitigate this limitation, we propose hierarchical over-the-air federated learning (HOTAFL), which utilizes intermediary servers (IS) to form clusters near MUs. We provide a convergence analysis for the proposed setup, and demonstrate through theoretical and experimental results that local aggregation in each cluster before global aggregation leads to a better performance and faster convergence than OTA FL.
Speeding-Up Back-Propagation in DNN: Approximate Outer Product with Memory
Oct 18, 2021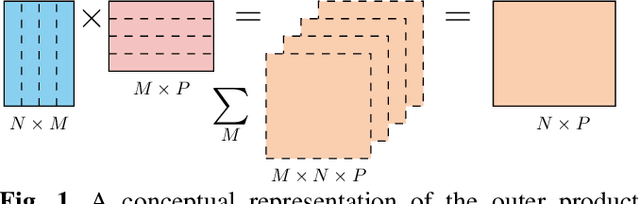
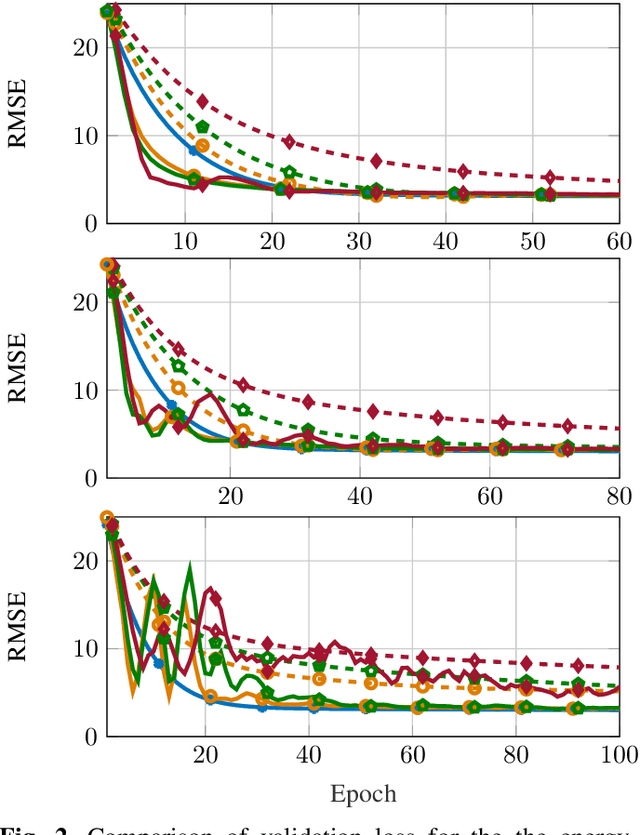

In this paper, an algorithm for approximate evaluation of back-propagation in DNN training is considered, which we term Approximate Outer Product Gradient Descent with Memory (Mem-AOP-GD). The Mem-AOP-GD algorithm implements an approximation of the stochastic gradient descent by considering only a subset of the outer products involved in the matrix multiplications that encompass backpropagation. In order to correct for the inherent bias in this approximation, the algorithm retains in memory an accumulation of the outer products that are not used in the approximation. We investigate the performance of the proposed algorithm in terms of DNN training loss under two design parameters: (i) the number of outer products used for the approximation, and (ii) the policy used to select such outer products. We experimentally show that significant improvements in computational complexity as well as accuracy can indeed be obtained through Mem-AOPGD.
Towards Goal-Oriented Semantic Signal Processing: Applications and Future Challenges
Sep 24, 2021

Advances in machine learning technology have enabled real-time extraction of semantic information in signals which can revolutionize signal processing techniques and improve their performance significantly for the next generation of applications. With the objective of a concrete representation and efficient processing of the semantic information, we propose and demonstrate a formal graph-based semantic language and a goal filtering method that enables goal-oriented signal processing. The proposed semantic signal processing framework can easily be tailored for specific applications and goals in a diverse range of signal processing applications. To illustrate its wide range of applicability, we investigate several use cases and provide details on how the proposed goal-oriented semantic signal processing framework can be customized. We also investigate and propose techniques for communications where sensor data is semantically processed and semantic information is exchanged across a sensor network.
* 44 pages, 29 figures, 3 tables. This preprint will be published in the Digital Signal Processing Journal's 30th anniversary issue on Future Signal Processing
Blind Federated Edge Learning
Oct 19, 2020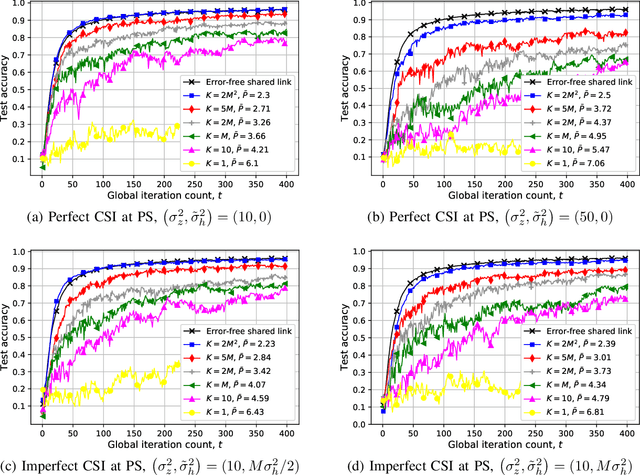

We study federated edge learning (FEEL), where wireless edge devices, each with its own dataset, learn a global model collaboratively with the help of a wireless access point acting as the parameter server (PS). At each iteration, wireless devices perform local updates using their local data and the most recent global model received from the PS, and send their local updates to the PS over a wireless fading multiple access channel (MAC). The PS then updates the global model according to the signal received over the wireless MAC, and shares it with the devices. Motivated by the additive nature of the wireless MAC, we propose an analog `over-the-air' aggregation scheme, in which the devices transmit their local updates in an uncoded fashion. Unlike recent literature on over-the-air edge learning, here we assume that the devices do not have channel state information (CSI), while the PS has imperfect CSI. Instead, the PS is equipped multiple antennas to alleviate the destructive effect of the channel, exacerbated due to the lack of perfect CSI. We design a receive beamforming scheme at the PS, and show that it can compensate for the lack of perfect CSI when the PS has a sufficient number of antennas. We also derive the convergence rate of the proposed algorithm highlighting the impact of the lack of perfect CSI, as well as the number of PS antennas. Both the experimental results and the convergence analysis illustrate the performance improvement of the proposed algorithm with the number of PS antennas, where the wireless fading MAC becomes deterministic despite the lack of perfect CSI when the PS has a sufficiently large number of antennas.
Machine Learning at Wireless Edge with OFDM and Low Resolution ADC and DAC
Oct 01, 2020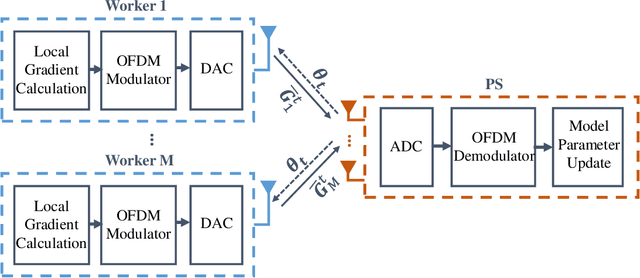
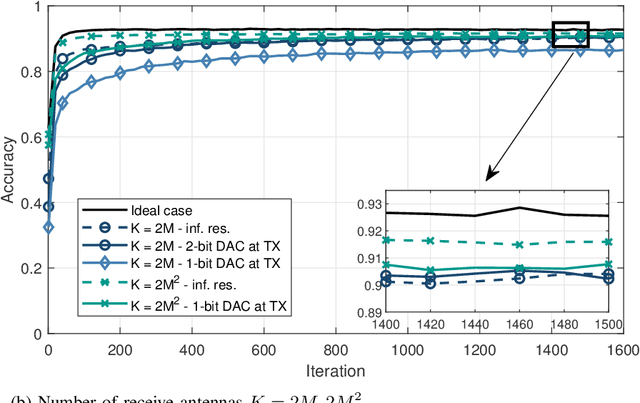
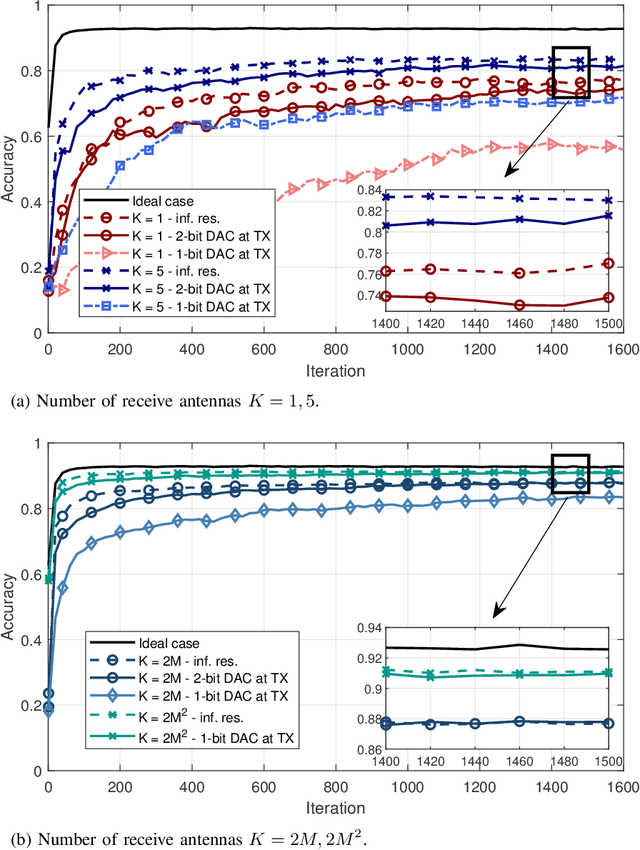
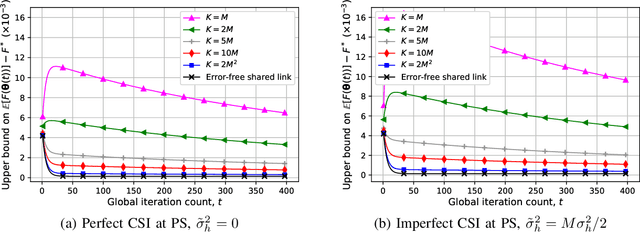
We study collaborative machine learning (ML) systems where a massive dataset is distributed across independent workers which compute their local gradient estimates based on their own datasets. Workers send their estimates through a multipath fading multiple access channel (MAC) with orthogonal frequency division multiplexing (OFDM) to mitigate the frequency selectivity of the channel. We assume that the parameter server (PS) employs multiple antennas to align the received signals with no channel state information (CSI) at the workers. To reduce the power consumption and the hardware costs, we employ complex-valued low resolution digital to analog converters (DACs) and analog to digital converters (ADCs), respectively, at the transmitter and the receiver sides to study the effects of practical low cost DACs and ADCs on the learning performance of the system. Our theoretical analysis shows that the impairments caused by low-resolution DACs and ADCs, including the extreme case of one-bit DACs and ADCs, do not prevent the convergence of the learning algorithm, and the multipath channel effects vanish when a sufficient number of antennas are used at the PS. We also validate our theoretical results via simulations, and demonstrate that using low-resolution, even one-bit, DACs and ADCs causes only a slight decrease in the learning accuracy.
Collaborative Machine Learning at the Wireless Edge with Blind Transmitters
Jul 08, 2019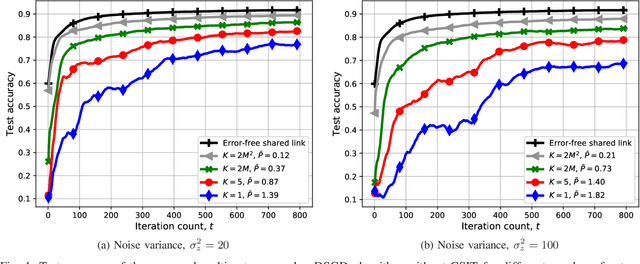
We study wireless collaborative machine learning (ML), where mobile edge devices, each with its own dataset, carry out distributed stochastic gradient descent (DSGD) over-the-air with the help of a wireless access point acting as the parameter server (PS). At each iteration of the DSGD algorithm wireless devices compute gradient estimates with their local datasets, and send them to the PS over a wireless fading multiple access channel (MAC). Motivated by the additive nature of the wireless MAC, we propose an analog DSGD scheme, in which the devices transmit scaled versions of their gradient estimates in an uncoded fashion. We assume that the channel state information (CSI) is available only at the PS. We instead allow the PS to employ multiple antennas to alleviate the destructive fading effect, which cannot be cancelled by the transmitters due to the lack of CSI. Theoretical analysis indicates that, with the proposed DSGD scheme, increasing the number of PS antennas mitigates the fading effect, and, in the limit, the effects of fading and noise disappear, and the PS receives aligned signals used to update the model parameter. The theoretical results are then corroborated with the experimental ones.