 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeThe Alignment Game: A Theory of Long-Horizon Alignment Through Recursive Curation
Nov 16, 2025In self-consuming generative models that train on their own outputs, alignment with user preferences becomes a recursive rather than one-time process. We provide the first formal foundation for analyzing the long-term effects of such recursive retraining on alignment. Under a two-stage curation mechanism based on the Bradley-Terry (BT) model, we model alignment as an interaction between two factions: the Model Owner, who filters which outputs should be learned by the model, and the Public User, who determines which outputs are ultimately shared and retained through interactions with the model. Our analysis reveals three structural convergence regimes depending on the degree of preference alignment: consensus collapse, compromise on shared optima, and asymmetric refinement. We prove a fundamental impossibility theorem: no recursive BT-based curation mechanism can simultaneously preserve diversity, ensure symmetric influence, and eliminate dependence on initialization. Framing the process as dynamic social choice, we show that alignment is not a static goal but an evolving equilibrium, shaped both by power asymmetries and path dependence.
Towards Reversible Model Merging For Low-rank Weights
Oct 15, 2025Model merging aims to combine multiple fine-tuned models into a single set of weights that performs well across all source tasks. While prior work has shown that merging can approximate the performance of individual fine-tuned models for each task, it largely overlooks scenarios where models are compressed into low-rank representations, either through low-rank adaptation (LoRA) or post-training singular value decomposition (SVD). We first demonstrate that applying conventional merging methods to low-rank weights leads to severe performance degradation in the merged model. Motivated by this phenomenon, we propose a fundamentally different approach: instead of collapsing all adapters into one set of weights, we construct a compact basis (e.g., an equivalent of holding two or more models) from which original task-specific models can be recovered via linear combination. This reframes merging as generating a reconstruction-capable model space rather than producing a single merged model. Crucially, this allows us to ``revert'' to each individual model when needed, recognizing that no merged model can consistently outperform one specialized for its task. Building on this insight, we introduce our method, Reversible Model Merging (RMM), an efficient, data-free, and flexible method that provides a closed-form solution for selecting the optimal basis of model weights and task-specific coefficients for linear combination. Extensive experiments across diverse datasets and model scales demonstrate that RMM consistently outperforms existing merging approaches, preserving the performance of low-rank compressed models by a significant margin.
OFMU: Optimization-Driven Framework for Machine Unlearning
Sep 26, 2025Large language models deployed in sensitive applications increasingly require the ability to unlearn specific knowledge, such as user requests, copyrighted materials, or outdated information, without retraining from scratch to ensure regulatory compliance, user privacy, and safety. This task, known as machine unlearning, aims to remove the influence of targeted data (forgetting) while maintaining performance on the remaining data (retention). A common approach is to formulate this as a multi-objective problem and reduce it to a single-objective problem via scalarization, where forgetting and retention losses are combined using a weighted sum. However, this often results in unstable training dynamics and degraded model utility due to conflicting gradient directions. To address these challenges, we propose OFMU, a penalty-based bi-level optimization framework that explicitly prioritizes forgetting while preserving retention through a hierarchical structure. Our method enforces forgetting via an inner maximization step that incorporates a similarity-aware penalty to decorrelate the gradients of the forget and retention objectives, and restores utility through an outer minimization step. To ensure scalability, we develop a two-loop algorithm with provable convergence guarantees under both convex and non-convex regimes. We further provide a rigorous theoretical analysis of convergence rates and show that our approach achieves better trade-offs between forgetting efficacy and model utility compared to prior methods. Extensive experiments across vision and language benchmarks demonstrate that OFMU consistently outperforms existing unlearning methods in both forgetting efficacy and retained utility.
Toward Efficient Influence Function: Dropout as a Compression Tool
Sep 19, 2025



Assessing the impact the training data on machine learning models is crucial for understanding the behavior of the model, enhancing the transparency, and selecting training data. Influence function provides a theoretical framework for quantifying the effect of training data points on model's performance given a specific test data. However, the computational and memory costs of influence function presents significant challenges, especially for large-scale models, even when using approximation methods, since the gradients involved in computation are as large as the model itself. In this work, we introduce a novel approach that leverages dropout as a gradient compression mechanism to compute the influence function more efficiently. Our method significantly reduces computational and memory overhead, not only during the influence function computation but also in gradient compression process. Through theoretical analysis and empirical validation, we demonstrate that our method could preserves critical components of the data influence and enables its application to modern large-scale models.
SentenceKV: Efficient LLM Inference via Sentence-Level Semantic KV Caching
Apr 01, 2025Large language models face significant computational and memory challenges when processing long contexts. During inference, efficient management of the key-value (KV) cache, which stores intermediate activations for autoregressive generation, is critical to reducing memory overhead and improving computational efficiency. Traditional token-level efficient KV caching methods overlook semantic information, treating tokens independently without considering their semantic relationships. Meanwhile, existing semantic-preserving KV cache management approaches often suffer from substantial memory usage and high time-to-first-token. To address these limitations, we propose SentenceKV, a novel sentence-level semantic KV caching approach designed to enhance inference efficiency while preserving semantic coherence. During prefilling, SentenceKV groups tokens based on sentence-level semantic similarity, compressing sentence representations into concise semantic vectors stored directly on the GPU, while individual KV pairs are offloaded to CPU. During decoding, SentenceKV generates tokens by selectively retrieving semantically relevant sentence-level KV entries, leveraging the semantic similarity between the prefilling-stage semantic vectors and decoding-stage queries. This ensures efficient and contextually accurate predictions, minimizing the loading of redundant or irrelevant data into GPU memory and significantly reducing memory overhead while maintaining stable inference latency, even for extremely long contexts. Extensive evaluations on benchmarks including PG-19, LongBench, and Needle-In-A-Haystack demonstrate that SentenceKV significantly outperforms state-of-the-art methods in both efficiency and memory usage, without compromising model accuracy.
Disentangled Structural and Featural Representation for Task-Agnostic Graph Valuation
Aug 22, 2024With the emergence of data marketplaces, the demand for methods to assess the value of data has increased significantly. While numerous techniques have been proposed for this purpose, none have specifically addressed graphs as the main data modality. Graphs are widely used across various fields, ranging from chemical molecules to social networks. In this study, we break down graphs into two main components: structural and featural, and we focus on evaluating data without relying on specific task-related metrics, making it applicable in practical scenarios where validation requirements may be lacking. We introduce a novel framework called blind message passing, which aligns the seller's and buyer's graphs using a shared node permutation based on graph matching. This allows us to utilize the graph Wasserstein distance to quantify the differences in the structural distribution of graph datasets, called the structural disparities. We then consider featural aspects of buyers' and sellers' graphs for data valuation and capture their statistical similarities and differences, referred to as relevance and diversity, respectively. Our approach ensures that buyers and sellers remain unaware of each other's datasets. Our experiments on real datasets demonstrate the effectiveness of our approach in capturing the relevance, diversity, and structural disparities of seller data for buyers, particularly in graph-based data valuation scenarios.
Data Measurements for Decentralized Data Markets
Jun 06, 2024Decentralized data markets can provide more equitable forms of data acquisition for machine learning. However, to realize practical marketplaces, efficient techniques for seller selection need to be developed. We propose and benchmark federated data measurements to allow a data buyer to find sellers with relevant and diverse datasets. Diversity and relevance measures enable a buyer to make relative comparisons between sellers without requiring intermediate brokers and training task-dependent models.
Fundamentals of Task-Agnostic Data Valuation
Aug 25, 2022
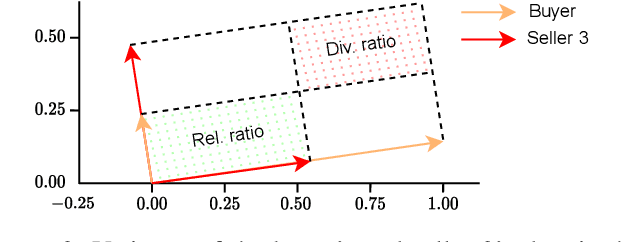

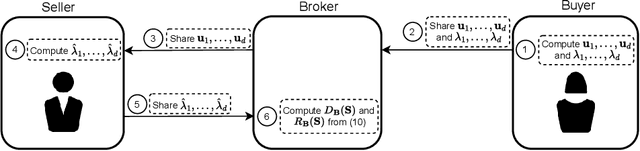
We study valuing the data of a data owner/seller for a data seeker/buyer. Data valuation is often carried out for a specific task assuming a particular utility metric, such as test accuracy on a validation set, that may not exist in practice. In this work, we focus on task-agnostic data valuation without any validation requirements. The data buyer has access to a limited amount of data (which could be publicly available) and seeks more data samples from a data seller. We formulate the problem as estimating the differences in the statistical properties of the data at the seller with respect to the baseline data available at the buyer. We capture these statistical differences through second moment by measuring diversity and relevance of the seller's data for the buyer; we estimate these measures through queries to the seller without requesting raw data. We design the queries with the proposed approach so that the seller is blind to the buyer's raw data and has no knowledge to fabricate responses to queries to obtain a desired outcome of the diversity and relevance trade-off.We will show through extensive experiments on real tabular and image datasets that the proposed estimates capture the diversity and relevance of the seller's data for the buyer.
Private independence testing across two parties
Jul 08, 2022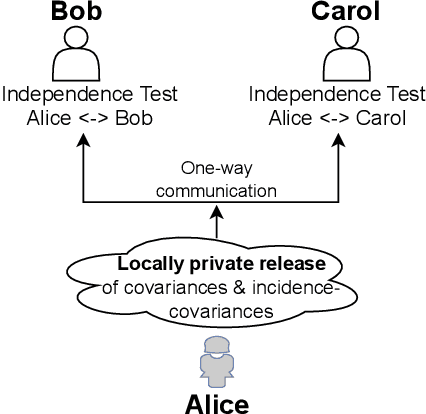

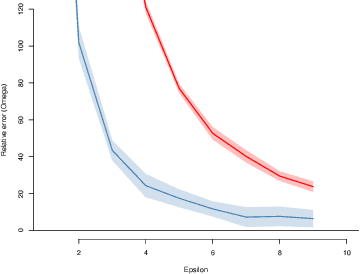
We introduce $\pi$-test, a privacy-preserving algorithm for testing statistical independence between data distributed across multiple parties. Our algorithm relies on privately estimating the distance correlation between datasets, a quantitative measure of independence introduced in Sz\'ekely et al. [2007]. We establish both additive and multiplicative error bounds on the utility of our differentially private test, which we believe will find applications in a variety of distributed hypothesis testing settings involving sensitive data.
Federated Learning with Downlink Device Selection
Jul 07, 2021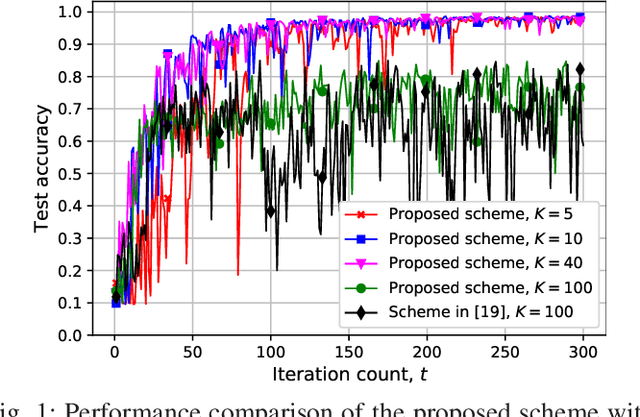
We study federated edge learning, where a global model is trained collaboratively using privacy-sensitive data at the edge of a wireless network. A parameter server (PS) keeps track of the global model and shares it with the wireless edge devices for training using their private local data. The devices then transmit their local model updates, which are used to update the global model, to the PS. The algorithm, which involves transmission over PS-to-device and device-to-PS links, continues until the convergence of the global model or lack of any participating devices. In this study, we consider device selection based on downlink channels over which the PS shares the global model with the devices. Performing digital downlink transmission, we design a partial device participation framework where a subset of the devices is selected for training at each iteration. Therefore, the participating devices can have a better estimate of the global model compared to the full device participation case which is due to the shared nature of the broadcast channel with the price of updating the global model with respect to a smaller set of data. At each iteration, the PS broadcasts different quantized global model updates to different participating devices based on the last global model estimates available at the devices. We investigate the best number of participating devices through experimental results for image classification using the MNIST dataset with biased distribution.