 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Short and Unified Convergence Analysis of the SAG, SAGA, and IAG Algorithms
Feb 05, 2026Stochastic variance-reduced algorithms such as Stochastic Average Gradient (SAG) and SAGA, and their deterministic counterparts like the Incremental Aggregated Gradient (IAG) method, have been extensively studied in large-scale machine learning. Despite their popularity, existing analyses for these algorithms are disparate, relying on different proof techniques tailored to each method. Furthermore, the original proof of SAG is known to be notoriously involved, requiring computer-aided analysis. Focusing on finite-sum optimization with smooth and strongly convex objective functions, our main contribution is to develop a single unified convergence analysis that applies to all three algorithms: SAG, SAGA, and IAG. Our analysis features two key steps: (i) establishing a bound on delays due to stochastic sub-sampling using simple concentration tools, and (ii) carefully designing a novel Lyapunov function that accounts for such delays. The resulting proof is short and modular, providing the first high-probability bounds for SAG and SAGA that can be seamlessly extended to non-convex objectives and Markov sampling. As an immediate byproduct of our new analysis technique, we obtain the best known rates for the IAG algorithm, significantly improving upon prior bounds.
Corruption-Tolerant Asynchronous Q-Learning with Near-Optimal Rates
Sep 10, 2025

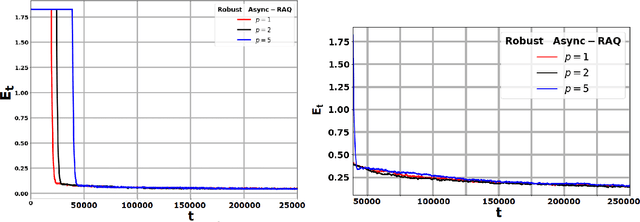

We consider the problem of learning the optimal policy in a discounted, infinite-horizon reinforcement learning (RL) setting where the reward signal is subject to adversarial corruption. Such corruption, which may arise from extreme noise, sensor faults, or malicious attacks, can severely degrade the performance of classical algorithms such as Q-learning. To address this challenge, we propose a new provably robust variant of the Q-learning algorithm that operates effectively even when a fraction of the observed rewards are arbitrarily perturbed by an adversary. Under the asynchronous sampling model with time-correlated data, we establish that despite adversarial corruption, the finite-time convergence rate of our algorithm matches that of existing results for the non-adversarial case, up to an additive term proportional to the fraction of corrupted samples. Moreover, we derive an information-theoretic lower bound revealing that the additive corruption term in our upper bounds is unavoidable. Next, we propose a variant of our algorithm that requires no prior knowledge of the statistics of the true reward distributions. The analysis of this setting is particularly challenging and is enabled by carefully exploiting a refined Azuma-Hoeffding inequality for almost-martingales, a technical tool that might be of independent interest. Collectively, our contributions provide the first finite-time robustness guarantees for asynchronous Q-learning, bridging a significant gap in robust RL.
Boosting-Enabled Robust System Identification of Partially Observed LTI Systems Under Heavy-Tailed Noise
Apr 25, 2025We consider the problem of system identification of partially observed linear time-invariant (LTI) systems. Given input-output data, we provide non-asymptotic guarantees for identifying the system parameters under general heavy-tailed noise processes. Unlike previous works that assume Gaussian or sub-Gaussian noise, we consider significantly broader noise distributions that are required to admit only up to the second moment. For this setting, we leverage tools from robust statistics to propose a novel system identification algorithm that exploits the idea of boosting. Despite the much weaker noise assumptions, we show that our proposed algorithm achieves sample complexity bounds that nearly match those derived under sub-Gaussian noise. In particular, we establish that our bounds retain a logarithmic dependence on the prescribed failure probability. Interestingly, we show that such bounds can be achieved by requiring just a finite fourth moment on the excitatory input process.
Achieving Tighter Finite-Time Rates for Heterogeneous Federated Stochastic Approximation under Markovian Sampling
Apr 15, 2025Motivated by collaborative reinforcement learning (RL) and optimization with time-correlated data, we study a generic federated stochastic approximation problem involving $M$ agents, where each agent is characterized by an agent-specific (potentially nonlinear) local operator. The goal is for the agents to communicate intermittently via a server to find the root of the average of the agents' local operators. The generality of our setting stems from allowing for (i) Markovian data at each agent and (ii) heterogeneity in the roots of the agents' local operators. The limited recent work that has accounted for both these features in a federated setting fails to guarantee convergence to the desired point or to show any benefit of collaboration; furthermore, they rely on projection steps in their algorithms to guarantee bounded iterates. Our work overcomes each of these limitations. We develop a novel algorithm titled \texttt{FedHSA}, and prove that it guarantees convergence to the correct point, while enjoying an $M$-fold linear speedup in sample-complexity due to collaboration. To our knowledge, \emph{this is the first finite-time result of its kind}, and establishing it (without relying on a projection step) entails a fairly intricate argument that accounts for the interplay between complex temporal correlations due to Markovian sampling, multiple local steps to save communication, and the drift-effects induced by heterogeneous local operators. Our results have implications for a broad class of heterogeneous federated RL problems (e.g., policy evaluation and control) with function approximation, where the agents' Markov decision processes can differ in their probability transition kernels and reward functions.
Adversarially-Robust TD Learning with Markovian Data: Finite-Time Rates and Fundamental Limits
Feb 07, 2025


One of the most basic problems in reinforcement learning (RL) is policy evaluation: estimating the long-term return, i.e., value function, corresponding to a given fixed policy. The celebrated Temporal Difference (TD) learning algorithm addresses this problem, and recent work has investigated finite-time convergence guarantees for this algorithm and variants thereof. However, these guarantees hinge on the reward observations being always generated from a well-behaved (e.g., sub-Gaussian) true reward distribution. Motivated by harsh, real-world environments where such an idealistic assumption may no longer hold, we revisit the policy evaluation problem from the perspective of adversarial robustness. In particular, we consider a Huber-contaminated reward model where an adversary can arbitrarily corrupt each reward sample with a small probability $\epsilon$. Under this observation model, we first show that the adversary can cause the vanilla TD algorithm to converge to any arbitrary value function. We then develop a novel algorithm called Robust-TD and prove that its finite-time guarantees match that of vanilla TD with linear function approximation up to a small $O(\epsilon)$ term that captures the effect of corruption. We complement this result with a minimax lower bound, revealing that such an additive corruption-induced term is unavoidable. To our knowledge, these results are the first of their kind in the context of adversarial robustness of stochastic approximation schemes driven by Markov noise. The key new technical tool that enables our results is an analysis of the Median-of-Means estimator with corrupted, time-correlated data that might be of independent interest to the literature on robust statistics.
Outlier-Robust Linear System Identification Under Heavy-tailed Noise
Dec 31, 2024We consider the problem of estimating the state transition matrix of a linear time-invariant (LTI) system, given access to multiple independent trajectories sampled from the system. Several recent papers have conducted a non-asymptotic analysis of this problem, relying crucially on the assumption that the process noise is either Gaussian or sub-Gaussian, i.e., "light-tailed". In sharp contrast, we work under a significantly weaker noise model, assuming nothing more than the existence of the fourth moment of the noise distribution. For this setting, we provide the first set of results demonstrating that one can obtain sample-complexity bounds for linear system identification that are nearly of the same order as under sub-Gaussian noise. To achieve such results, we develop a novel robust system identification algorithm that relies on constructing multiple weakly-concentrated estimators, and then boosting their performance using suitable tools from high-dimensional robust statistics. Interestingly, our analysis reveals how the kurtosis of the noise distribution, a measure of heavy-tailedness, affects the number of trajectories needed to achieve desired estimation error bounds. Finally, we show that our algorithm and analysis technique can be easily extended to account for scenarios where an adversary can arbitrarily corrupt a small fraction of the collected trajectory data. Our work takes the first steps towards building a robust statistical learning theory for control under non-ideal assumptions on the data-generating process.
Towards Fast Rates for Federated and Multi-Task Reinforcement Learning
Sep 09, 2024We consider a setting involving $N$ agents, where each agent interacts with an environment modeled as a Markov Decision Process (MDP). The agents' MDPs differ in their reward functions, capturing heterogeneous objectives/tasks. The collective goal of the agents is to communicate intermittently via a central server to find a policy that maximizes the average of long-term cumulative rewards across environments. The limited existing work on this topic either only provide asymptotic rates, or generate biased policies, or fail to establish any benefits of collaboration. In response, we propose Fast-FedPG - a novel federated policy gradient algorithm with a carefully designed bias-correction mechanism. Under a gradient-domination condition, we prove that our algorithm guarantees (i) fast linear convergence with exact gradients, and (ii) sub-linear rates that enjoy a linear speedup w.r.t. the number of agents with noisy, truncated policy gradients. Notably, in each case, the convergence is to a globally optimal policy with no heterogeneity-induced bias. In the absence of gradient-domination, we establish convergence to a first-order stationary point at a rate that continues to benefit from collaboration.
Robust Q-Learning under Corrupted Rewards
Sep 05, 2024
Recently, there has been a surge of interest in analyzing the non-asymptotic behavior of model-free reinforcement learning algorithms. However, the performance of such algorithms in non-ideal environments, such as in the presence of corrupted rewards, is poorly understood. Motivated by this gap, we investigate the robustness of the celebrated Q-learning algorithm to a strong-contamination attack model, where an adversary can arbitrarily perturb a small fraction of the observed rewards. We start by proving that such an attack can cause the vanilla Q-learning algorithm to incur arbitrarily large errors. We then develop a novel robust synchronous Q-learning algorithm that uses historical reward data to construct robust empirical Bellman operators at each time step. Finally, we prove a finite-time convergence rate for our algorithm that matches known state-of-the-art bounds (in the absence of attacks) up to a small inevitable $O(\varepsilon)$ error term that scales with the adversarial corruption fraction $\varepsilon$. Notably, our results continue to hold even when the true reward distributions have infinite support, provided they admit bounded second moments.
DASA: Delay-Adaptive Multi-Agent Stochastic Approximation
Mar 28, 2024

We consider a setting in which $N$ agents aim to speedup a common Stochastic Approximation (SA) problem by acting in parallel and communicating with a central server. We assume that the up-link transmissions to the server are subject to asynchronous and potentially unbounded time-varying delays. To mitigate the effect of delays and stragglers while reaping the benefits of distributed computation, we propose \texttt{DASA}, a Delay-Adaptive algorithm for multi-agent Stochastic Approximation. We provide a finite-time analysis of \texttt{DASA} assuming that the agents' stochastic observation processes are independent Markov chains. Significantly advancing existing results, \texttt{DASA} is the first algorithm whose convergence rate depends only on the mixing time $\tau_{mix}$ and on the average delay $\tau_{avg}$ while jointly achieving an $N$-fold convergence speedup under Markovian sampling. Our work is relevant for various SA applications, including multi-agent and distributed temporal difference (TD) learning, Q-learning and stochastic optimization with correlated data.
A Simple Finite-Time Analysis of TD Learning with Linear Function Approximation
Mar 04, 2024We study the finite-time convergence of TD learning with linear function approximation under Markovian sampling. Existing proofs for this setting either assume a projection step in the algorithm to simplify the analysis, or require a fairly intricate argument to ensure stability of the iterates. We ask: \textit{Is it possible to retain the simplicity of a projection-based analysis without actually performing a projection step in the algorithm?} Our main contribution is to show this is possible via a novel two-step argument. In the first step, we use induction to prove that under a standard choice of a constant step-size $\alpha$, the iterates generated by TD learning remain uniformly bounded in expectation. In the second step, we establish a recursion that mimics the steady-state dynamics of TD learning up to a bounded perturbation on the order of $O(\alpha^2)$ that captures the effect of Markovian sampling. Combining these pieces leads to an overall approach that considerably simplifies existing proofs. We conjecture that our inductive proof technique will find applications in the analyses of more complex stochastic approximation algorithms, and conclude by providing some examples of such applications.