 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLearning from Shader Program Traces
Paper and Code
Feb 08, 2021

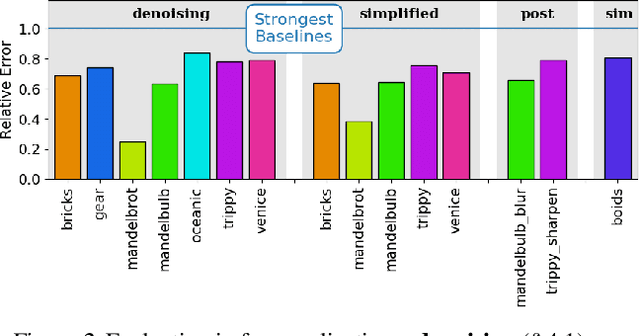
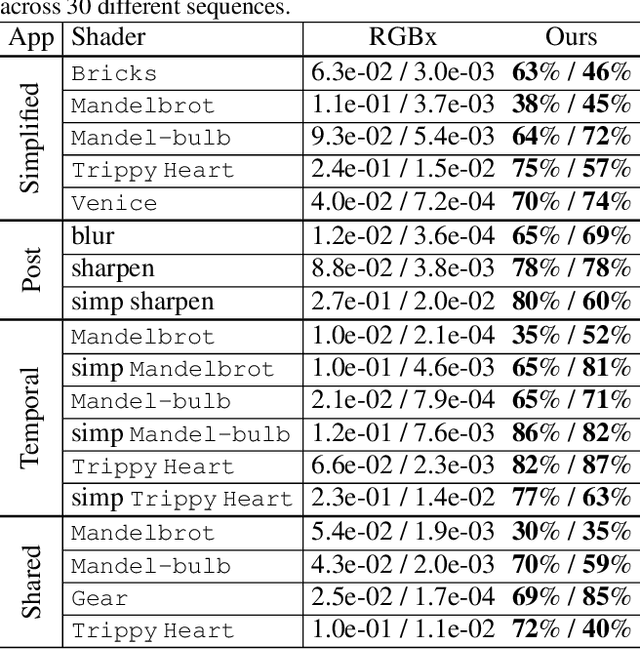
Deep networks for image processing typically learn from RGB pixels. This paper proposes instead to learn from program traces, the intermediate values computed during program execution. We study this idea in the context of pixel~shaders -- programs that generate images, typically running in parallel (for each pixel) on GPU hardware. The intermediate values computed at each pixel during program execution form the input to the learned model. In a variety of applications, models learned from program traces outperform baseline models learned from RGB, even when augmented with hand-picked shader-specific features. We also investigate strategies for selecting a subset of trace features for learning; using just a small subset of the trace still outperforms the baselines.