 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMultiple-Input Variational Auto-Encoder for Anomaly Detection in Heterogeneous Data
Jan 14, 2025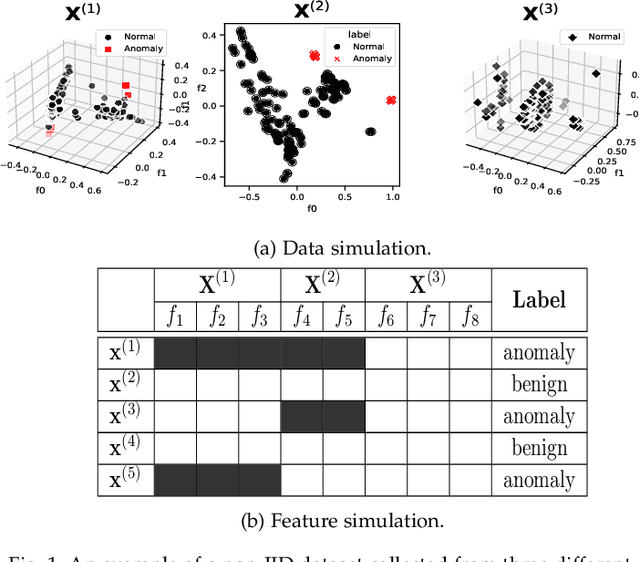

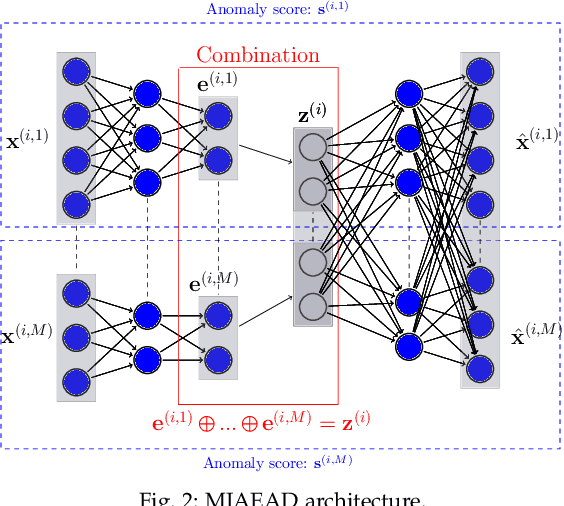
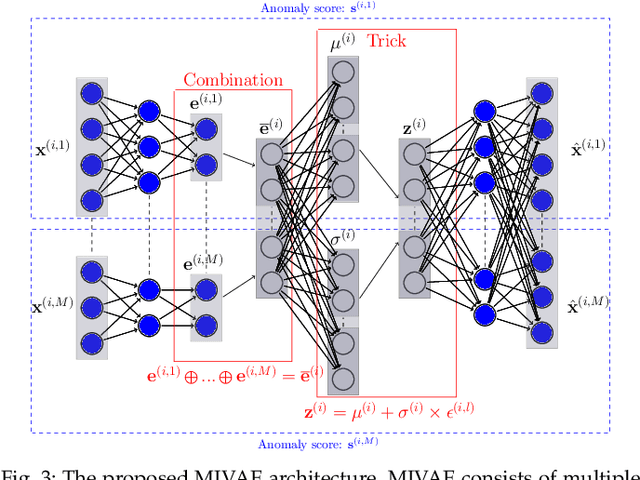
Anomaly detection (AD) plays a pivotal role in AI applications, e.g., in classification, and intrusion/threat detection in cybersecurity. However, most existing methods face challenges of heterogeneity amongst feature subsets posed by non-independent and identically distributed (non-IID) data. We propose a novel neural network model called Multiple-Input Auto-Encoder for AD (MIAEAD) to address this. MIAEAD assigns an anomaly score to each feature subset of a data sample to indicate its likelihood of being an anomaly. This is done by using the reconstruction error of its sub-encoder as the anomaly score. All sub-encoders are then simultaneously trained using unsupervised learning to determine the anomaly scores of feature subsets. The final AUC of MIAEAD is calculated for each sub-dataset, and the maximum AUC obtained among the sub-datasets is selected. To leverage the modelling of the distribution of normal data to identify anomalies of the generative models, we develop a novel neural network architecture/model called Multiple-Input Variational Auto-Encoder (MIVAE). MIVAE can process feature subsets through its sub-encoders before learning distribution of normal data in the latent space. This allows MIVAE to identify anomalies that deviate from the learned distribution. We theoretically prove that the difference in the average anomaly score between normal samples and anomalies obtained by the proposed MIVAE is greater than that of the Variational Auto-Encoder (VAEAD), resulting in a higher AUC for MIVAE. Extensive experiments on eight real-world anomaly datasets demonstrate the superior performance of MIAEAD and MIVAE over conventional methods and the state-of-the-art unsupervised models, by up to 6% in terms of AUC score. Alternatively, MIAEAD and MIVAE have a high AUC when applied to feature subsets with low heterogeneity based on the coefficient of variation (CV) score.
Twin Auto-Encoder Model for Learning Separable Representation in Cyberattack Detection
Mar 22, 2024



Representation Learning (RL) plays a pivotal role in the success of many problems including cyberattack detection. Most of the RL methods for cyberattack detection are based on the latent vector of Auto-Encoder (AE) models. An AE transforms raw data into a new latent representation that better exposes the underlying characteristics of the input data. Thus, it is very useful for identifying cyberattacks. However, due to the heterogeneity and sophistication of cyberattacks, the representation of AEs is often entangled/mixed resulting in the difficulty for downstream attack detection models. To tackle this problem, we propose a novel mod called Twin Auto-Encoder (TAE). TAE deterministically transforms the latent representation into a more distinguishable representation namely the \textit{separable representation} and the reconstructsuct the separable representation at the output. The output of TAE called the \textit{reconstruction representation} is input to downstream models to detect cyberattacks. We extensively evaluate the effectiveness of TAE using a wide range of bench-marking datasets. Experiment results show the superior accuracy of TAE over state-of-the-art RL models and well-known machine learning algorithms. Moreover, TAE also outperforms state-of-the-art models on some sophisticated and challenging attacks. We then investigate various characteristics of TAE to further demonstrate its superiority.
Multiple-Input Auto-Encoder Guided Feature Selection for IoT Intrusion Detection Systems
Mar 22, 2024While intrusion detection systems (IDSs) benefit from the diversity and generalization of IoT data features, the data diversity (e.g., the heterogeneity and high dimensions of data) also makes it difficult to train effective machine learning models in IoT IDSs. This also leads to potentially redundant/noisy features that may decrease the accuracy of the detection engine in IDSs. This paper first introduces a novel neural network architecture called Multiple-Input Auto-Encoder (MIAE). MIAE consists of multiple sub-encoders that can process inputs from different sources with different characteristics. The MIAE model is trained in an unsupervised learning mode to transform the heterogeneous inputs into lower-dimensional representation, which helps classifiers distinguish between normal behaviour and different types of attacks. To distil and retain more relevant features but remove less important/redundant ones during the training process, we further design and embed a feature selection layer right after the representation layer of MIAE resulting in a new model called MIAEFS. This layer learns the importance of features in the representation vector, facilitating the selection of informative features from the representation vector. The results on three IDS datasets, i.e., NSLKDD, UNSW-NB15, and IDS2017, show the superior performance of MIAE and MIAEFS compared to other methods, e.g., conventional classifiers, dimensionality reduction models, unsupervised representation learning methods with different input dimensions, and unsupervised feature selection models. Moreover, MIAE and MIAEFS combined with the Random Forest (RF) classifier achieve accuracy of 96.5% in detecting sophisticated attacks, e.g., Slowloris. The average running time for detecting an attack sample using RF with the representation of MIAE and MIAEFS is approximate 1.7E-6 seconds, whilst the model size is lower than 1 MB.
Constrained Twin Variational Auto-Encoder for Intrusion Detection in IoT Systems
Dec 05, 2023Intrusion detection systems (IDSs) play a critical role in protecting billions of IoT devices from malicious attacks. However, the IDSs for IoT devices face inherent challenges of IoT systems, including the heterogeneity of IoT data/devices, the high dimensionality of training data, and the imbalanced data. Moreover, the deployment of IDSs on IoT systems is challenging, and sometimes impossible, due to the limited resources such as memory/storage and computing capability of typical IoT devices. To tackle these challenges, this article proposes a novel deep neural network/architecture called Constrained Twin Variational Auto-Encoder (CTVAE) that can feed classifiers of IDSs with more separable/distinguishable and lower-dimensional representation data. Additionally, in comparison to the state-of-the-art neural networks used in IDSs, CTVAE requires less memory/storage and computing power, hence making it more suitable for IoT IDS systems. Extensive experiments with the 11 most popular IoT botnet datasets show that CTVAE can boost around 1% in terms of accuracy and Fscore in detection attack compared to the state-of-the-art machine learning and representation learning methods, whilst the running time for attack detection is lower than 2E-6 seconds and the model size is lower than 1 MB. We also further investigate various characteristics of CTVAE in the latent space and in the reconstruction representation to demonstrate its efficacy compared with current well-known methods.