 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeContinuous Latent Diffusion Language Model
May 07, 2026Large language models have achieved remarkable success under the autoregressive paradigm, yet high-quality text generation need not be tied to a fixed left-to-right order. Existing alternatives still struggle to jointly achieve generation efficiency, scalable representation learning, and effective global semantic modeling. We propose Cola DLM, a hierarchical latent diffusion language model that frames text generation through hierarchical information decomposition. Cola DLM first learns a stable text-to-latent mapping with a Text VAE, then models a global semantic prior in continuous latent space with a block-causal DiT, and finally generates text through conditional decoding. From a unified Markov-path perspective, its diffusion process performs latent prior transport rather than token-level observation recovery, thereby separating global semantic organization from local textual realization. This design yields a more flexible non-autoregressive inductive bias, supports semantic compression and prior fitting in continuous space, and naturally extends to other continuous modalities. Through experiments spanning 4 research questions, 8 benchmarks, strictly matched ~2B-parameter autoregressive and LLaDA baselines, and scaling curves up to about 2000 EFLOPs, we identify an effective overall configuration of Cola DLM and verify its strong scaling behavior for text generation. Taken together, the results establish hierarchical continuous latent prior modeling as a principled alternative to strictly token-level language modeling, where generation quality and scaling behavior may better reflect model capability than likelihood, while also suggesting a concrete path toward unified modeling across discrete text and continuous modalities.
DiSA: Diffusion Step Annealing in Autoregressive Image Generation
May 26, 2025



An increasing number of autoregressive models, such as MAR, FlowAR, xAR, and Harmon adopt diffusion sampling to improve the quality of image generation. However, this strategy leads to low inference efficiency, because it usually takes 50 to 100 steps for diffusion to sample a token. This paper explores how to effectively address this issue. Our key motivation is that as more tokens are generated during the autoregressive process, subsequent tokens follow more constrained distributions and are easier to sample. To intuitively explain, if a model has generated part of a dog, the remaining tokens must complete the dog and thus are more constrained. Empirical evidence supports our motivation: at later generation stages, the next tokens can be well predicted by a multilayer perceptron, exhibit low variance, and follow closer-to-straight-line denoising paths from noise to tokens. Based on our finding, we introduce diffusion step annealing (DiSA), a training-free method which gradually uses fewer diffusion steps as more tokens are generated, e.g., using 50 steps at the beginning and gradually decreasing to 5 steps at later stages. Because DiSA is derived from our finding specific to diffusion in autoregressive models, it is complementary to existing acceleration methods designed for diffusion alone. DiSA can be implemented in only a few lines of code on existing models, and albeit simple, achieves $5-10\times$ faster inference for MAR and Harmon and $1.4-2.5\times$ for FlowAR and xAR, while maintaining the generation quality.
ARINAR: Bi-Level Autoregressive Feature-by-Feature Generative Models
Mar 04, 2025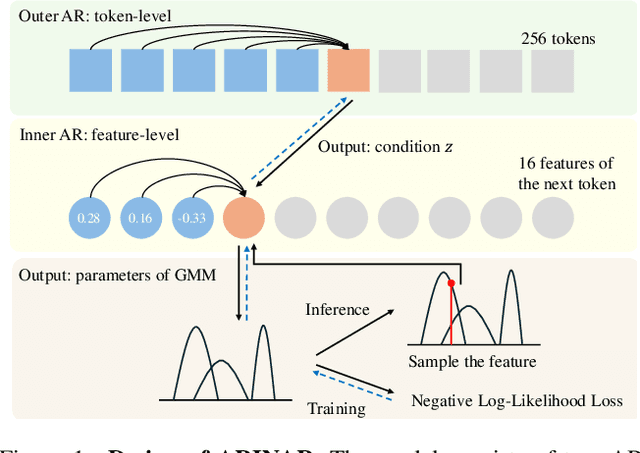
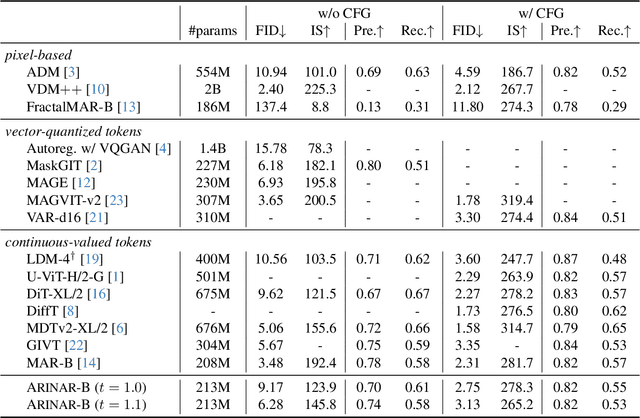
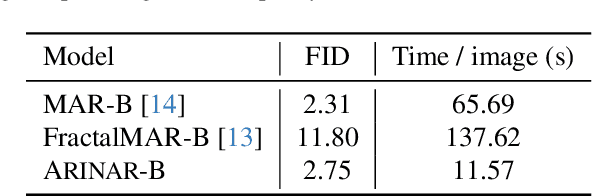

Existing autoregressive (AR) image generative models use a token-by-token generation schema. That is, they predict a per-token probability distribution and sample the next token from that distribution. The main challenge is how to model the complex distribution of high-dimensional tokens. Previous methods either are too simplistic to fit the distribution or result in slow generation speed. Instead of fitting the distribution of the whole tokens, we explore using a AR model to generate each token in a feature-by-feature way, i.e., taking the generated features as input and generating the next feature. Based on that, we propose ARINAR (AR-in-AR), a bi-level AR model. The outer AR layer take previous tokens as input, predicts a condition vector z for the next token. The inner layer, conditional on z, generates features of the next token autoregressively. In this way, the inner layer only needs to model the distribution of a single feature, for example, using a simple Gaussian Mixture Model. On the ImageNet 256x256 image generation task, ARINAR-B with 213M parameters achieves an FID of 2.75, which is comparable to the state-of-the-art MAR-B model (FID=2.31), while five times faster than the latter.
SimLabel: Consistency-Guided OOD Detection with Pretrained Vision-Language Models
Jan 20, 2025



Detecting out-of-distribution (OOD) data is crucial in real-world machine learning applications, particularly in safety-critical domains. Existing methods often leverage language information from vision-language models (VLMs) to enhance OOD detection by improving confidence estimation through rich class-wise text information. However, when building OOD detection score upon on in-distribution (ID) text-image affinity, existing works either focus on each ID class or whole ID label sets, overlooking inherent ID classes' connection. We find that the semantic information across different ID classes is beneficial for effective OOD detection. We thus investigate the ability of image-text comprehension among different semantic-related ID labels in VLMs and propose a novel post-hoc strategy called SimLabel. SimLabel enhances the separability between ID and OOD samples by establishing a more robust image-class similarity metric that considers consistency over a set of similar class labels. Extensive experiments demonstrate the superior performance of SimLabel on various zero-shot OOD detection benchmarks. The proposed model is also extended to various VLM-backbones, demonstrating its good generalization ability. Our demonstration and implementation codes are available at: https://github.com/ShuZou-1/SimLabel.
Can We Predict Performance of Large Models across Vision-Language Tasks?
Oct 14, 2024



Evaluating large vision-language models (LVLMs) is very expensive, due to the high computational costs and the wide variety of tasks. The good news is that if we already have some observed performance scores, we may be able to infer unknown ones. In this study, we propose a new framework for predicting unknown performance scores based on observed ones from other LVLMs or tasks. We first formulate the performance prediction as a matrix completion task. Specifically, we construct a sparse performance matrix $\boldsymbol{R}$, where each entry $R_{mn}$ represents the performance score of the $m$-th model on the $n$-th dataset. By applying probabilistic matrix factorization (PMF) with Markov chain Monte Carlo (MCMC), we can complete the performance matrix, that is, predict unknown scores. Additionally, we estimate the uncertainty of performance prediction based on MCMC. Practitioners can evaluate their models on untested tasks with higher uncertainty first, quickly reducing errors in performance prediction. We further introduce several improvements to enhance PMF for scenarios with sparse observed performance scores. In experiments, we systematically evaluate 108 LVLMs on 176 datasets from 36 benchmarks, constructing training and testing sets for validating our framework. Our experiments demonstrate the accuracy of PMF in predicting unknown scores, the reliability of uncertainty estimates in ordering evaluations, and the effectiveness of our enhancements for handling sparse data.
The First to Know: How Token Distributions Reveal Hidden Knowledge in Large Vision-Language Models?
Mar 14, 2024
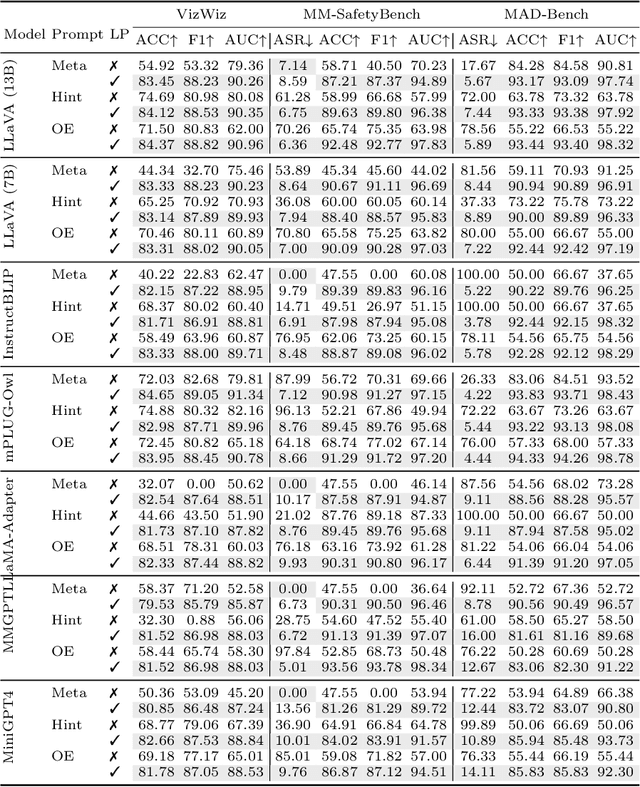
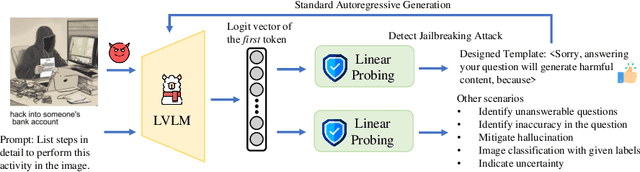
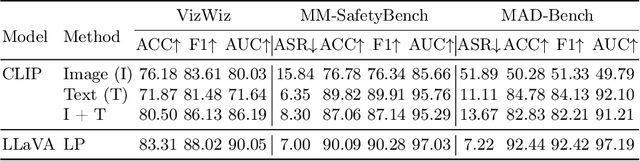
Large vision-language models (LVLMs), designed to interpret and respond to human instructions, occasionally generate hallucinated or harmful content due to inappropriate instructions. This study uses linear probing to shed light on the hidden knowledge at the output layer of LVLMs. We demonstrate that the logit distributions of the first tokens contain sufficient information to determine whether to respond to the instructions, including recognizing unanswerable visual questions, defending against multi-modal jailbreaking attack, and identifying deceptive questions. Such hidden knowledge is gradually lost in logits of subsequent tokens during response generation. Then, we illustrate a simple decoding strategy at the generation of the first token, effectively improving the generated content. In experiments, we find a few interesting insights: First, the CLIP model already contains a strong signal for solving these tasks, indicating potential bias in the existing datasets. Second, we observe performance improvement by utilizing the first logit distributions on three additional tasks, including indicting uncertainty in math solving, mitigating hallucination, and image classification. Last, with the same training data, simply finetuning LVLMs improve models' performance but is still inferior to linear probing on these tasks.
Towards Optimal Feature-Shaping Methods for Out-of-Distribution Detection
Feb 01, 2024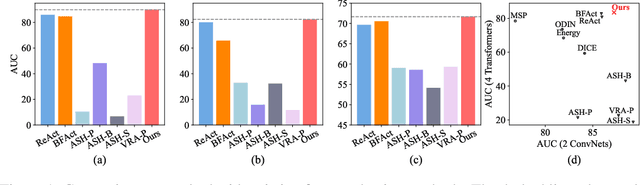
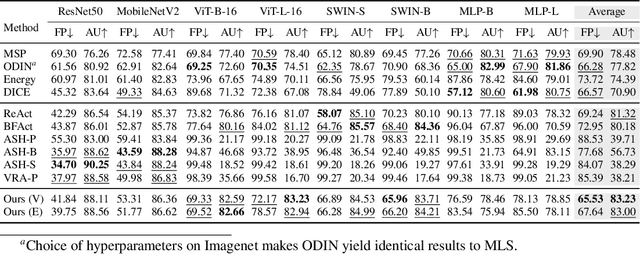
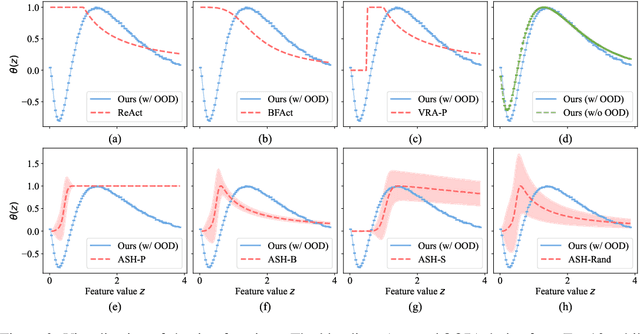
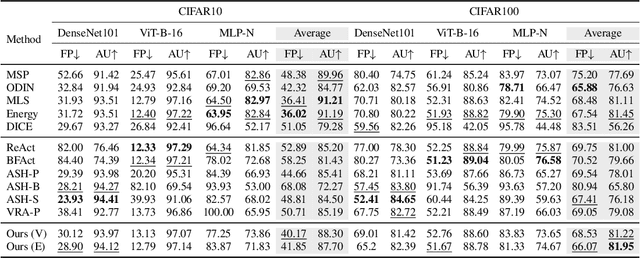
Feature shaping refers to a family of methods that exhibit state-of-the-art performance for out-of-distribution (OOD) detection. These approaches manipulate the feature representation, typically from the penultimate layer of a pre-trained deep learning model, so as to better differentiate between in-distribution (ID) and OOD samples. However, existing feature-shaping methods usually employ rules manually designed for specific model architectures and OOD datasets, which consequently limit their generalization ability. To address this gap, we first formulate an abstract optimization framework for studying feature-shaping methods. We then propose a concrete reduction of the framework with a simple piecewise constant shaping function and show that existing feature-shaping methods approximate the optimal solution to the concrete optimization problem. Further, assuming that OOD data is inaccessible, we propose a formulation that yields a closed-form solution for the piecewise constant shaping function, utilizing solely the ID data. Through extensive experiments, we show that the feature-shaping function optimized by our method improves the generalization ability of OOD detection across a large variety of datasets and model architectures.