 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeImproving Model Evaluation using SMART Filtering of Benchmark Datasets
Oct 26, 2024



One of the most challenging problems facing NLP today is evaluation. Some of the most pressing issues pertain to benchmark saturation, data contamination, and diversity in the quality of test examples. To address these concerns, we propose Selection Methodology for Accurate, Reduced, and Targeted (SMART) filtering, a novel approach to select a high-quality subset of examples from existing benchmark datasets by systematically removing less informative and less challenging examples. Our approach applies three filtering criteria, removing (i) easy examples, (ii) data-contaminated examples, and (iii) examples that are similar to each other based on distance in an embedding space. We demonstrate the effectiveness of SMART on three multiple choice QA datasets, where our methodology increases efficiency by reducing dataset size by 48\% on average, while increasing Pearson correlation with rankings from ChatBot Arena, a more open-ended human evaluation setting. Our method enables us to be more efficient, whether using SMART to make new benchmarks more challenging or to revitalize older datasets, while still preserving the relative model rankings.
ESPERANTO: Evaluating Synthesized Phrases to Enhance Robustness in AI Detection for Text Origination
Sep 22, 2024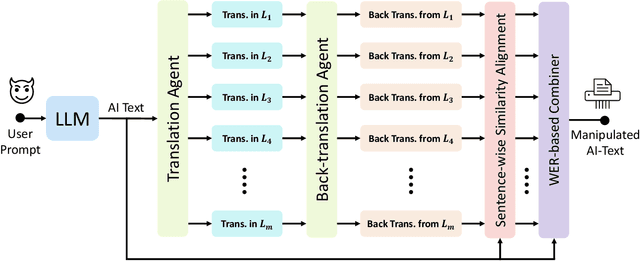
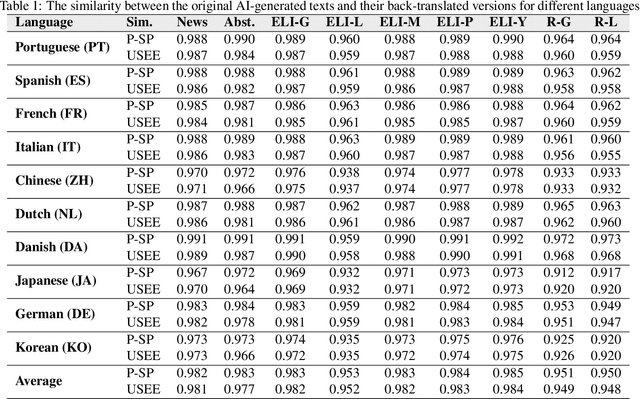

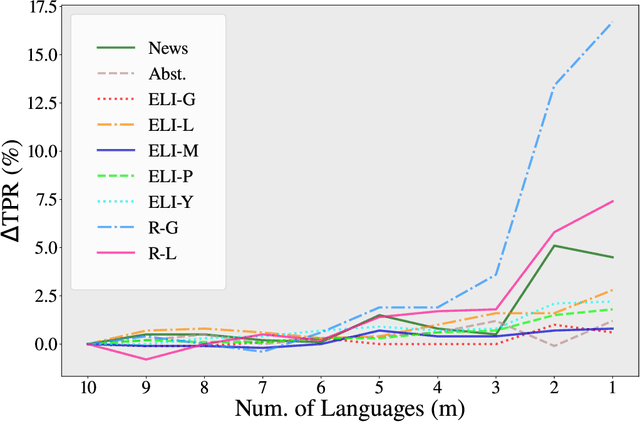
While large language models (LLMs) exhibit significant utility across various domains, they simultaneously are susceptible to exploitation for unethical purposes, including academic misconduct and dissemination of misinformation. Consequently, AI-generated text detection systems have emerged as a countermeasure. However, these detection mechanisms demonstrate vulnerability to evasion techniques and lack robustness against textual manipulations. This paper introduces back-translation as a novel technique for evading detection, underscoring the need to enhance the robustness of current detection systems. The proposed method involves translating AI-generated text through multiple languages before back-translating to English. We present a model that combines these back-translated texts to produce a manipulated version of the original AI-generated text. Our findings demonstrate that the manipulated text retains the original semantics while significantly reducing the true positive rate (TPR) of existing detection methods. We evaluate this technique on nine AI detectors, including six open-source and three proprietary systems, revealing their susceptibility to back-translation manipulation. In response to the identified shortcomings of existing AI text detectors, we present a countermeasure to improve the robustness against this form of manipulation. Our results indicate that the TPR of the proposed method declines by only 1.85% after back-translation manipulation. Furthermore, we build a large dataset of 720k texts using eight different LLMs. Our dataset contains both human-authored and LLM-generated texts in various domains and writing styles to assess the performance of our method and existing detectors. This dataset is publicly shared for the benefit of the research community.
Changing Answer Order Can Decrease MMLU Accuracy
Jun 27, 2024



As large language models (LLMs) have grown in prevalence, particular benchmarks have become essential for the evaluation of these models and for understanding model capabilities. Most commonly, we use test accuracy averaged across multiple subtasks in order to rank models on leaderboards, to determine which model is best for our purposes. In this paper, we investigate the robustness of the accuracy measurement on a widely used multiple choice question answering dataset, MMLU. When shuffling the answer label contents, we find that all explored models decrease in accuracy on MMLU, but not every model is equally sensitive. These findings suggest a possible adjustment to the standard practice of leaderboard testing, where we additionally consider the percentage of examples each model answers correctly by random chance.