 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMoEGCL: Mixture of Ego-Graphs Contrastive Representation Learning for Multi-View Clustering
Nov 08, 2025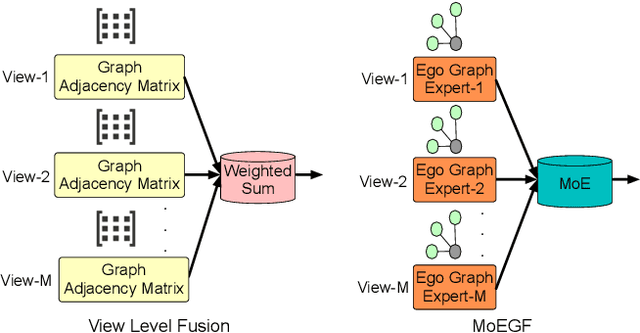
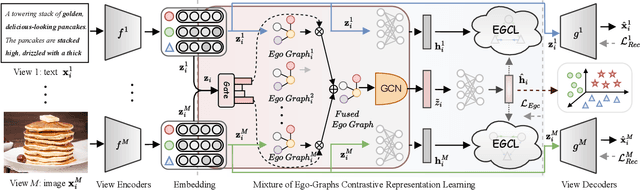
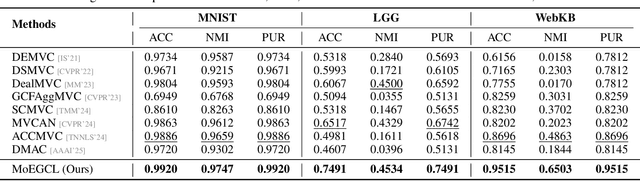
In recent years, the advancement of Graph Neural Networks (GNNs) has significantly propelled progress in Multi-View Clustering (MVC). However, existing methods face the problem of coarse-grained graph fusion. Specifically, current approaches typically generate a separate graph structure for each view and then perform weighted fusion of graph structures at the view level, which is a relatively rough strategy. To address this limitation, we present a novel Mixture of Ego-Graphs Contrastive Representation Learning (MoEGCL). It mainly consists of two modules. In particular, we propose an innovative Mixture of Ego-Graphs Fusion (MoEGF), which constructs ego graphs and utilizes a Mixture-of-Experts network to implement fine-grained fusion of ego graphs at the sample level, rather than the conventional view-level fusion. Additionally, we present the Ego Graph Contrastive Learning (EGCL) module to align the fused representation with the view-specific representation. The EGCL module enhances the representation similarity of samples from the same cluster, not merely from the same sample, further boosting fine-grained graph representation. Extensive experiments demonstrate that MoEGCL achieves state-of-the-art results in deep multi-view clustering tasks. The source code is publicly available at https://github.com/HackerHyper/MoEGCL.
Generative Diffusion Contrastive Network for Multi-View Clustering
Sep 11, 2025In recent years, Multi-View Clustering (MVC) has been significantly advanced under the influence of deep learning. By integrating heterogeneous data from multiple views, MVC enhances clustering analysis, making multi-view fusion critical to clustering performance. However, there is a problem of low-quality data in multi-view fusion. This problem primarily arises from two reasons: 1) Certain views are contaminated by noisy data. 2) Some views suffer from missing data. This paper proposes a novel Stochastic Generative Diffusion Fusion (SGDF) method to address this problem. SGDF leverages a multiple generative mechanism for the multi-view feature of each sample. It is robust to low-quality data. Building on SGDF, we further present the Generative Diffusion Contrastive Network (GDCN). Extensive experiments show that GDCN achieves the state-of-the-art results in deep MVC tasks. The source code is publicly available at https://github.com/HackerHyper/GDCN.
Adaptive Confidence Multi-View Hashing for Multimedia Retrieval
Dec 12, 2023



The multi-view hash method converts heterogeneous data from multiple views into binary hash codes, which is one of the critical technologies in multimedia retrieval. However, the current methods mainly explore the complementarity among multiple views while lacking confidence learning and fusion. Moreover, in practical application scenarios, the single-view data contain redundant noise. To conduct the confidence learning and eliminate unnecessary noise, we propose a novel Adaptive Confidence Multi-View Hashing (ACMVH) method. First, a confidence network is developed to extract useful information from various single-view features and remove noise information. Furthermore, an adaptive confidence multi-view network is employed to measure the confidence of each view and then fuse multi-view features through a weighted summation. Lastly, a dilation network is designed to further enhance the feature representation of the fused features. To the best of our knowledge, we pioneer the application of confidence learning into the field of multimedia retrieval. Extensive experiments on two public datasets show that the proposed ACMVH performs better than state-of-the-art methods (maximum increase of 3.24%). The source code is available at https://github.com/HackerHyper/ACMVH.
Central Similarity Multi-View Hashing for Multimedia Retrieval
Aug 26, 2023



Hash representation learning of multi-view heterogeneous data is the key to improving the accuracy of multimedia retrieval. However, existing methods utilize local similarity and fall short of deeply fusing the multi-view features, resulting in poor retrieval accuracy. Current methods only use local similarity to train their model. These methods ignore global similarity. Furthermore, most recent works fuse the multi-view features via a weighted sum or concatenation. We contend that these fusion methods are insufficient for capturing the interaction between various views. We present a novel Central Similarity Multi-View Hashing (CSMVH) method to address the mentioned problems. Central similarity learning is used for solving the local similarity problem, which can utilize the global similarity between the hash center and samples. We present copious empirical data demonstrating the superiority of gate-based fusion over conventional approaches. On the MS COCO and NUS-WIDE, the proposed CSMVH performs better than the state-of-the-art methods by a large margin (up to 11.41% mean Average Precision (mAP) improvement).
Deep Metric Multi-View Hashing for Multimedia Retrieval
Apr 13, 2023Learning the hash representation of multi-view heterogeneous data is an important task in multimedia retrieval. However, existing methods fail to effectively fuse the multi-view features and utilize the metric information provided by the dissimilar samples, leading to limited retrieval precision. Current methods utilize weighted sum or concatenation to fuse the multi-view features. We argue that these fusion methods cannot capture the interaction among different views. Furthermore, these methods ignored the information provided by the dissimilar samples. We propose a novel deep metric multi-view hashing (DMMVH) method to address the mentioned problems. Extensive empirical evidence is presented to show that gate-based fusion is better than typical methods. We introduce deep metric learning to the multi-view hashing problems, which can utilize metric information of dissimilar samples. On the MIR-Flickr25K, MS COCO, and NUS-WIDE, our method outperforms the current state-of-the-art methods by a large margin (up to 15.28 mean Average Precision (mAP) improvement).