 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeConditional Pseudo-Reversible Normalizing Flow for Surrogate Modeling in Quantifying Uncertainty Propagation
Mar 31, 2024We introduce a conditional pseudo-reversible normalizing flow for constructing surrogate models of a physical model polluted by additive noise to efficiently quantify forward and inverse uncertainty propagation. Existing surrogate modeling approaches usually focus on approximating the deterministic component of physical model. However, this strategy necessitates knowledge of noise and resorts to auxiliary sampling methods for quantifying inverse uncertainty propagation. In this work, we develop the conditional pseudo-reversible normalizing flow model to directly learn and efficiently generate samples from the conditional probability density functions. The training process utilizes dataset consisting of input-output pairs without requiring prior knowledge about the noise and the function. Our model, once trained, can generate samples from any conditional probability density functions whose high probability regions are covered by the training set. Moreover, the pseudo-reversibility feature allows for the use of fully-connected neural network architectures, which simplifies the implementation and enables theoretical analysis. We provide a rigorous convergence analysis of the conditional pseudo-reversible normalizing flow model, showing its ability to converge to the target conditional probability density function using the Kullback-Leibler divergence. To demonstrate the effectiveness of our method, we apply it to several benchmark tests and a real-world geologic carbon storage problem.
Sparsity Winning Twice: Better Robust Generalization from More Efficient Training
Feb 27, 2022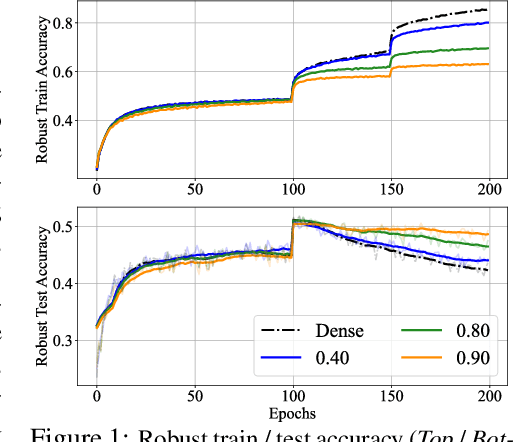
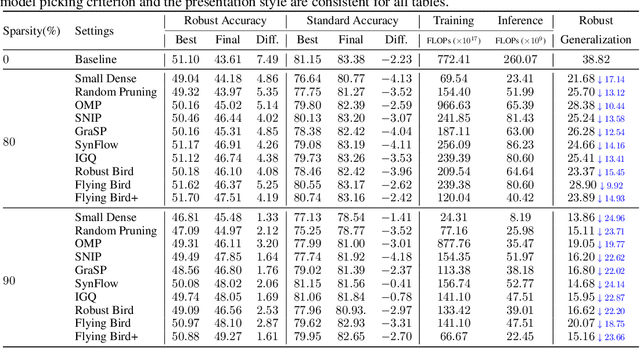
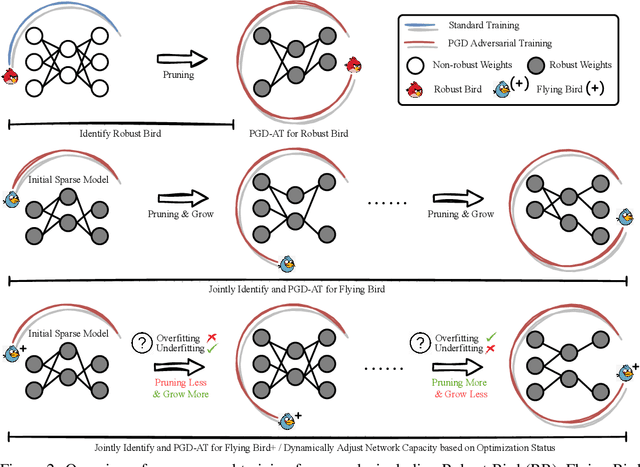
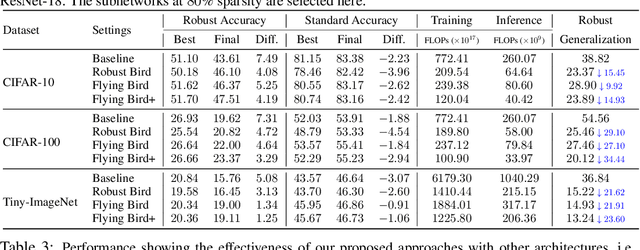
Recent studies demonstrate that deep networks, even robustified by the state-of-the-art adversarial training (AT), still suffer from large robust generalization gaps, in addition to the much more expensive training costs than standard training. In this paper, we investigate this intriguing problem from a new perspective, i.e., injecting appropriate forms of sparsity during adversarial training. We introduce two alternatives for sparse adversarial training: (i) static sparsity, by leveraging recent results from the lottery ticket hypothesis to identify critical sparse subnetworks arising from the early training; (ii) dynamic sparsity, by allowing the sparse subnetwork to adaptively adjust its connectivity pattern (while sticking to the same sparsity ratio) throughout training. We find both static and dynamic sparse methods to yield win-win: substantially shrinking the robust generalization gap and alleviating the robust overfitting, meanwhile significantly saving training and inference FLOPs. Extensive experiments validate our proposals with multiple network architectures on diverse datasets, including CIFAR-10/100 and Tiny-ImageNet. For example, our methods reduce robust generalization gap and overfitting by 34.44% and 4.02%, with comparable robust/standard accuracy boosts and 87.83%/87.82% training/inference FLOPs savings on CIFAR-100 with ResNet-18. Besides, our approaches can be organically combined with existing regularizers, establishing new state-of-the-art results in AT. Codes are available in https://github.com/VITA-Group/Sparsity-Win-Robust-Generalization.
Hu-Fu: Hardware and Software Collaborative Attack Framework against Neural Networks
May 14, 2018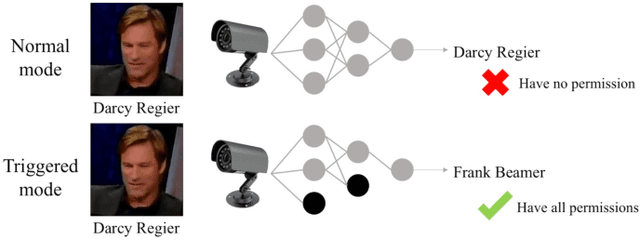
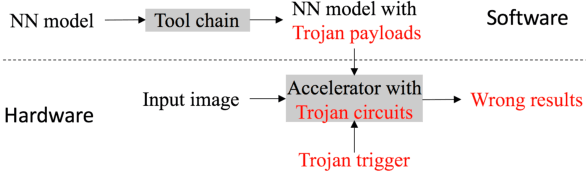

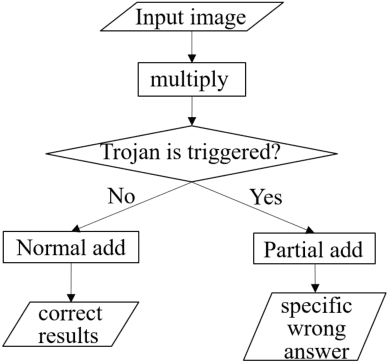
Recently, Deep Learning (DL), especially Convolutional Neural Network (CNN), develops rapidly and is applied to many tasks, such as image classification, face recognition, image segmentation, and human detection. Due to its superior performance, DL-based models have a wide range of application in many areas, some of which are extremely safety-critical, e.g. intelligent surveillance and autonomous driving. Due to the latency and privacy problem of cloud computing, embedded accelerators are popular in these safety-critical areas. However, the robustness of the embedded DL system might be harmed by inserting hardware/software Trojans into the accelerator and the neural network model, since the accelerator and deploy tool (or neural network model) are usually provided by third-party companies. Fortunately, inserting hardware Trojans can only achieve inflexible attack, which means that hardware Trojans can easily break down the whole system or exchange two outputs, but can't make CNN recognize unknown pictures as targets. Though inserting software Trojans has more freedom of attack, it often requires tampering input images, which is not easy for attackers. So, in this paper, we propose a hardware-software collaborative attack framework to inject hidden neural network Trojans, which works as a back-door without requiring manipulating input images and is flexible for different scenarios. We test our attack framework for image classification and face recognition tasks, and get attack success rate of 92.6% and 100% on CIFAR10 and YouTube Faces, respectively, while keeping almost the same accuracy as the unattacked model in the normal mode. In addition, we show a specific attack scenario in which a face recognition system is attacked and gives a specific wrong answer.
A Deep Learning Approach for Blind Drift Calibration of Sensor Networks
Jun 16, 2017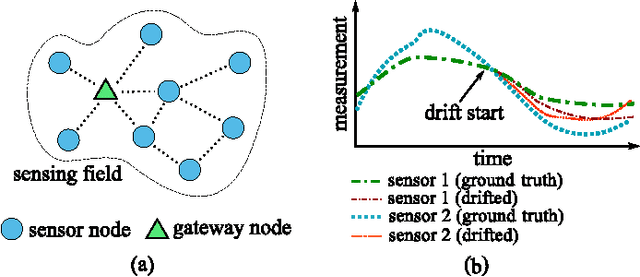
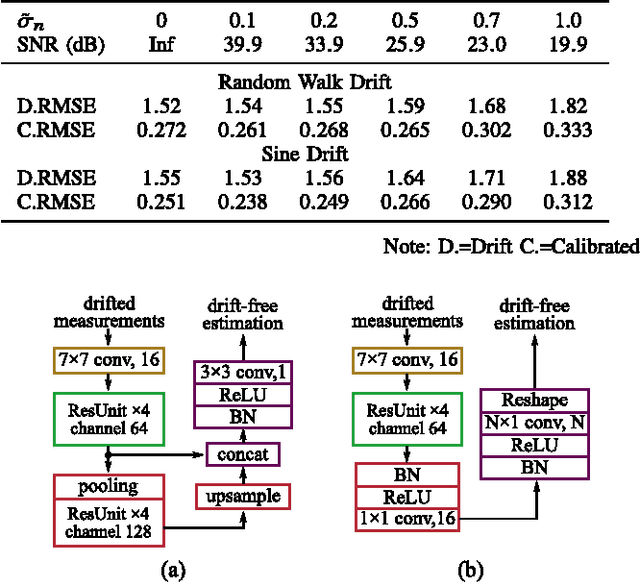
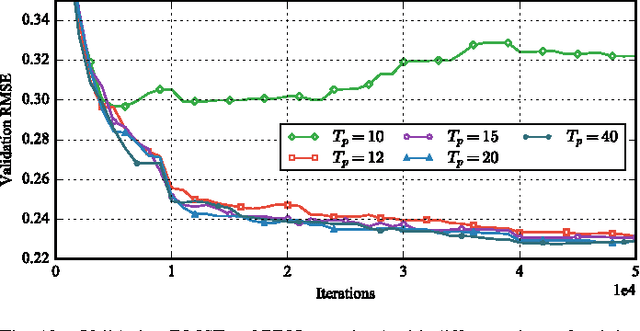
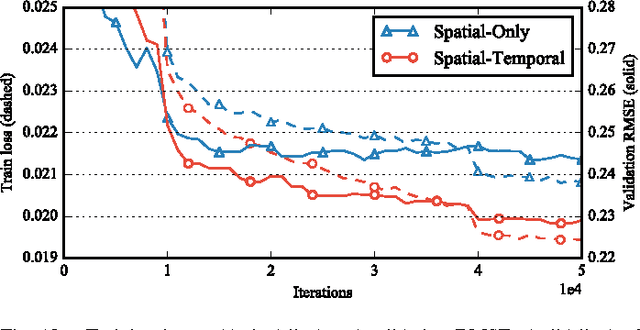
Temporal drift of sensory data is a severe problem impacting the data quality of wireless sensor networks (WSNs). With the proliferation of large-scale and long-term WSNs, it is becoming more important to calibrate sensors when the ground truth is unavailable. This problem is called "blind calibration". In this paper, we propose a novel deep learning method named projection-recovery network (PRNet) to blindly calibrate sensor measurements online. The PRNet first projects the drifted data to a feature space, and uses a powerful deep convolutional neural network to recover the estimated drift-free measurements. We deploy a 24-sensor testbed and provide comprehensive empirical evidence showing that the proposed method significantly improves the sensing accuracy and drifted sensor detection. Compared with previous methods, PRNet can calibrate 2x of drifted sensors at the recovery rate of 80% under the same level of accuracy requirement. We also provide helpful insights for designing deep neural networks for sensor calibration. We hope our proposed simple and effective approach will serve as a solid baseline in blind drift calibration of sensor networks.