 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBohrium + SciMaster: Building the Infrastructure and Ecosystem for Agentic Science at Scale
Dec 23, 2025



AI agents are emerging as a practical way to run multi-step scientific workflows that interleave reasoning with tool use and verification, pointing to a shift from isolated AI-assisted steps toward \emph{agentic science at scale}. This shift is increasingly feasible, as scientific tools and models can be invoked through stable interfaces and verified with recorded execution traces, and increasingly necessary, as AI accelerates scientific output and stresses the peer-review and publication pipeline, raising the bar for traceability and credible evaluation. However, scaling agentic science remains difficult: workflows are hard to observe and reproduce; many tools and laboratory systems are not agent-ready; execution is hard to trace and govern; and prototype AI Scientist systems are often bespoke, limiting reuse and systematic improvement from real workflow signals. We argue that scaling agentic science requires an infrastructure-and-ecosystem approach, instantiated in Bohrium+SciMaster. Bohrium acts as a managed, traceable hub for AI4S assets -- akin to a HuggingFace of AI for Science -- that turns diverse scientific data, software, compute, and laboratory systems into agent-ready capabilities. SciMaster orchestrates these capabilities into long-horizon scientific workflows, on which scientific agents can be composed and executed. Between infrastructure and orchestration, a \emph{scientific intelligence substrate} organizes reusable models, knowledge, and components into executable building blocks for workflow reasoning and action, enabling composition, auditability, and improvement through use. We demonstrate this stack with eleven representative master agents in real workflows, achieving orders-of-magnitude reductions in end-to-end scientific cycle time and generating execution-grounded signals from real workloads at multi-million scale.
RadioDiff-3D: A 3D$\times$3D Radio Map Dataset and Generative Diffusion Based Benchmark for 6G Environment-Aware Communication
Jul 16, 2025Radio maps (RMs) serve as a critical foundation for enabling environment-aware wireless communication, as they provide the spatial distribution of wireless channel characteristics. Despite recent progress in RM construction using data-driven approaches, most existing methods focus solely on pathloss prediction in a fixed 2D plane, neglecting key parameters such as direction of arrival (DoA), time of arrival (ToA), and vertical spatial variations. Such a limitation is primarily due to the reliance on static learning paradigms, which hinder generalization beyond the training data distribution. To address these challenges, we propose UrbanRadio3D, a large-scale, high-resolution 3D RM dataset constructed via ray tracing in realistic urban environments. UrbanRadio3D is over 37$\times$3 larger than previous datasets across a 3D space with 3 metrics as pathloss, DoA, and ToA, forming a novel 3D$\times$33D dataset with 7$\times$3 more height layers than prior state-of-the-art (SOTA) dataset. To benchmark 3D RM construction, a UNet with 3D convolutional operators is proposed. Moreover, we further introduce RadioDiff-3D, a diffusion-model-based generative framework utilizing the 3D convolutional architecture. RadioDiff-3D supports both radiation-aware scenarios with known transmitter locations and radiation-unaware settings based on sparse spatial observations. Extensive evaluations on UrbanRadio3D validate that RadioDiff-3D achieves superior performance in constructing rich, high-dimensional radio maps under diverse environmental dynamics. This work provides a foundational dataset and benchmark for future research in 3D environment-aware communication. The dataset is available at https://github.com/UNIC-Lab/UrbanRadio3D.
Uni-AIMS: AI-Powered Microscopy Image Analysis
May 11, 2025This paper presents a systematic solution for the intelligent recognition and automatic analysis of microscopy images. We developed a data engine that generates high-quality annotated datasets through a combination of the collection of diverse microscopy images from experiments, synthetic data generation and a human-in-the-loop annotation process. To address the unique challenges of microscopy images, we propose a segmentation model capable of robustly detecting both small and large objects. The model effectively identifies and separates thousands of closely situated targets, even in cluttered visual environments. Furthermore, our solution supports the precise automatic recognition of image scale bars, an essential feature in quantitative microscopic analysis. Building upon these components, we have constructed a comprehensive intelligent analysis platform and validated its effectiveness and practicality in real-world applications. This study not only advances automatic recognition in microscopy imaging but also ensures scalability and generalizability across multiple application domains, offering a powerful tool for automated microscopic analysis in interdisciplinary research.
GenAI4UQ: A Software for Inverse Uncertainty Quantification Using Conditional Generative Models
Dec 09, 2024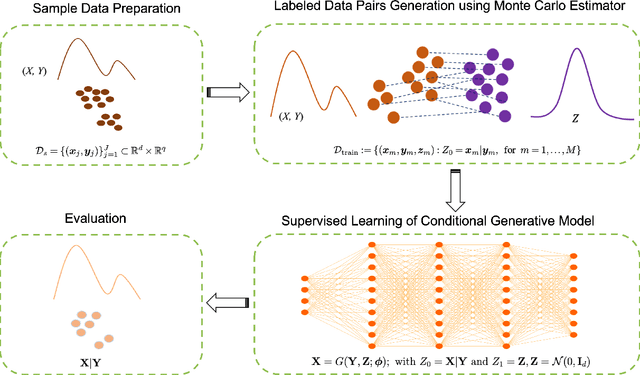
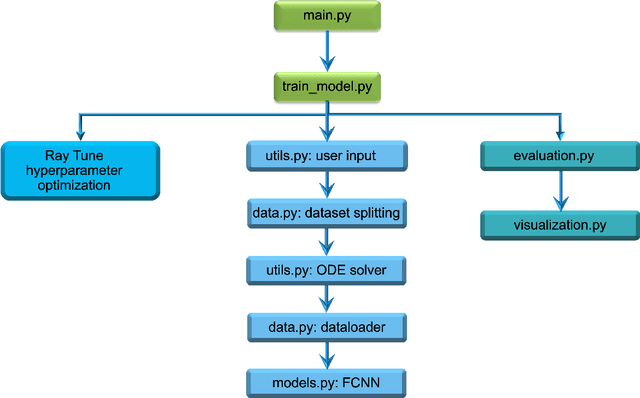
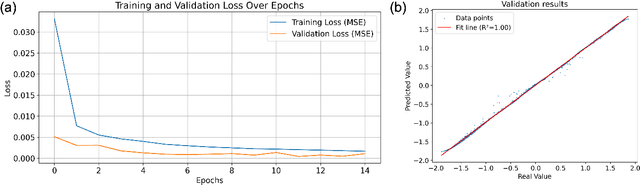

We introduce GenAI4UQ, a software package for inverse uncertainty quantification in model calibration, parameter estimation, and ensemble forecasting in scientific applications. GenAI4UQ leverages a generative artificial intelligence (AI) based conditional modeling framework to address the limitations of traditional inverse modeling techniques, such as Markov Chain Monte Carlo methods. By replacing computationally intensive iterative processes with a direct, learned mapping, GenAI4UQ enables efficient calibration of model input parameters and generation of output predictions directly from observations. The software's design allows for rapid ensemble forecasting with robust uncertainty quantification, while maintaining high computational and storage efficiency. GenAI4UQ simplifies the model training process through built-in auto-tuning of hyperparameters, making it accessible to users with varying levels of expertise. Its conditional generative framework ensures versatility, enabling applicability across a wide range of scientific domains. At its core, GenAI4UQ transforms the paradigm of inverse modeling by providing a fast, reliable, and user-friendly solution. It empowers researchers and practitioners to quickly estimate parameter distributions and generate model predictions for new observations, facilitating efficient decision-making and advancing the state of uncertainty quantification in computational modeling. (The code and data are available at https://github.com/patrickfan/GenAI4UQ).
Nonuniform random feature models using derivative information
Oct 03, 2024We propose nonuniform data-driven parameter distributions for neural network initialization based on derivative data of the function to be approximated. These parameter distributions are developed in the context of non-parametric regression models based on shallow neural networks, and compare favorably to well-established uniform random feature models based on conventional weight initialization. We address the cases of Heaviside and ReLU activation functions, and their smooth approximations (sigmoid and softplus), and use recent results on the harmonic analysis and sparse representation of neural networks resulting from fully trained optimal networks. Extending analytic results that give exact representation, we obtain densities that concentrate in regions of the parameter space corresponding to neurons that are well suited to model the local derivatives of the unknown function. Based on these results, we suggest simplifications of these exact densities based on approximate derivative data in the input points that allow for very efficient sampling and lead to performance of random feature models close to optimal networks in several scenarios.
Fast and Accurate Cooperative Radio Map Estimation Enabled by GAN
Feb 05, 2024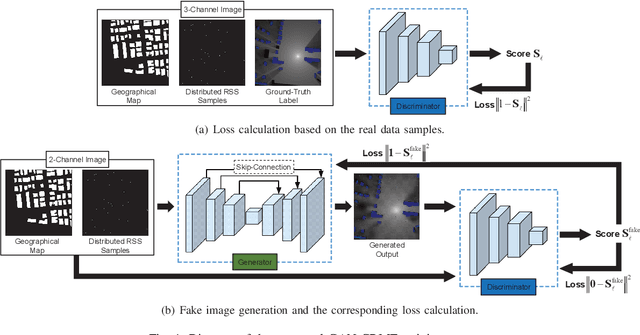
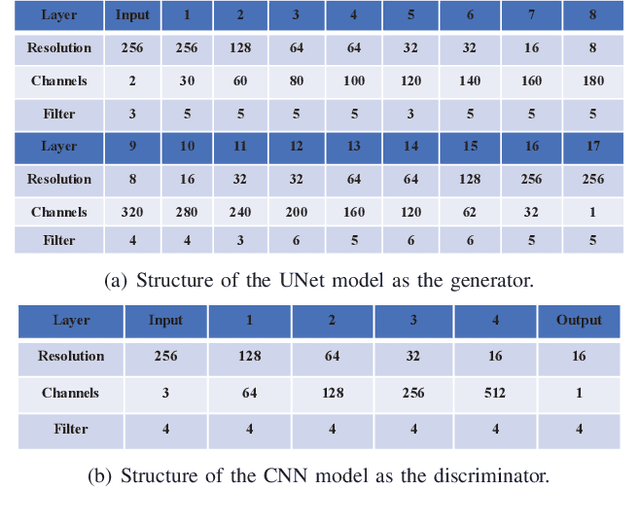


In the 6G era, real-time radio resource monitoring and management are urged to support diverse wireless-empowered applications. This calls for fast and accurate estimation on the distribution of the radio resources, which is usually represented by the spatial signal power strength over the geographical environment, known as a radio map. In this paper, we present a cooperative radio map estimation (CRME) approach enabled by the generative adversarial network (GAN), called as GAN-CRME, which features fast and accurate radio map estimation without the transmitters' information. The radio map is inferred by exploiting the interaction between distributed received signal strength (RSS) measurements at mobile users and the geographical map using a deep neural network estimator, resulting in low data-acquisition cost and computational complexity. Moreover, a GAN-based learning algorithm is proposed to boost the inference capability of the deep neural network estimator by exploiting the power of generative AI. Simulation results showcase that the proposed GAN-CRME is even capable of coarse error-correction when the geographical map information is inaccurate.
Improving the Expressive Power of Deep Neural Networks through Integral Activation Transform
Dec 19, 2023The impressive expressive power of deep neural networks (DNNs) underlies their widespread applicability. However, while the theoretical capacity of deep architectures is high, the practical expressive power achieved through successful training often falls short. Building on the insights gained from Neural ODEs, which explore the depth of DNNs as a continuous variable, in this work, we generalize the traditional fully connected DNN through the concept of continuous width. In the Generalized Deep Neural Network (GDNN), the traditional notion of neurons in each layer is replaced by a continuous state function. Using the finite rank parameterization of the weight integral kernel, we establish that GDNN can be obtained by employing the Integral Activation Transform (IAT) as activation layers within the traditional DNN framework. The IAT maps the input vector to a function space using some basis functions, followed by nonlinear activation in the function space, and then extracts information through the integration with another collection of basis functions. A specific variant, IAT-ReLU, featuring the ReLU nonlinearity, serves as a smooth generalization of the scalar ReLU activation. Notably, IAT-ReLU exhibits a continuous activation pattern when continuous basis functions are employed, making it smooth and enhancing the trainability of the DNN. Our numerical experiments demonstrate that IAT-ReLU outperforms regular ReLU in terms of trainability and better smoothness.
Knowledge Base Enabled Semantic Communication: A Generative Perspective
Nov 21, 2023



Semantic communication is widely touted as a key technology for propelling the sixth-generation (6G) wireless networks. However, providing effective semantic representation is quite challenging in practice. To address this issue, this article takes a crack at exploiting semantic knowledge base (KB) to usher in a new era of generative semantic communication. Via semantic KB, source messages can be characterized in low-dimensional subspaces without compromising their desired meaning, thus significantly enhancing the communication efficiency. The fundamental principle of semantic KB is first introduced, and a generative semantic communication architecture is developed by presenting three sub-KBs, namely source, task, and channel KBs. Then, the detailed construction approaches for each sub-KB are described, followed by their utilization in terms of semantic coding and transmission. A case study is also provided to showcase the superiority of generative semantic communication over conventional syntactic communication and classical semantic communication. In a nutshell, this article establishes a scientific foundation for the exciting uncharted frontier of generative semantic communication.
Diffusion-Model-Assisted Supervised Learning of Generative Models for Density Estimation
Oct 22, 2023



We present a supervised learning framework of training generative models for density estimation. Generative models, including generative adversarial networks, normalizing flows, variational auto-encoders, are usually considered as unsupervised learning models, because labeled data are usually unavailable for training. Despite the success of the generative models, there are several issues with the unsupervised training, e.g., requirement of reversible architectures, vanishing gradients, and training instability. To enable supervised learning in generative models, we utilize the score-based diffusion model to generate labeled data. Unlike existing diffusion models that train neural networks to learn the score function, we develop a training-free score estimation method. This approach uses mini-batch-based Monte Carlo estimators to directly approximate the score function at any spatial-temporal location in solving an ordinary differential equation (ODE), corresponding to the reverse-time stochastic differential equation (SDE). This approach can offer both high accuracy and substantial time savings in neural network training. Once the labeled data are generated, we can train a simple fully connected neural network to learn the generative model in the supervised manner. Compared with existing normalizing flow models, our method does not require to use reversible neural networks and avoids the computation of the Jacobian matrix. Compared with existing diffusion models, our method does not need to solve the reverse-time SDE to generate new samples. As a result, the sampling efficiency is significantly improved. We demonstrate the performance of our method by applying it to a set of 2D datasets as well as real data from the UCI repository.
An Ensemble Score Filter for Tracking High-Dimensional Nonlinear Dynamical Systems
Sep 02, 2023We propose an ensemble score filter (EnSF) for solving high-dimensional nonlinear filtering problems with superior accuracy. A major drawback of existing filtering methods, e.g., particle filters or ensemble Kalman filters, is the low accuracy in handling high-dimensional and highly nonlinear problems. EnSF attacks this challenge by exploiting the score-based diffusion model, defined in a pseudo-temporal domain, to characterizing the evolution of the filtering density. EnSF stores the information of the recursively updated filtering density function in the score function, in stead of storing the information in a set of finite Monte Carlo samples (used in particle filters and ensemble Kalman filters). Unlike existing diffusion models that train neural networks to approximate the score function, we develop a training-free score estimation that uses mini-batch-based Monte Carlo estimator to directly approximate the score function at any pseudo-spatial-temporal location, which provides sufficient accuracy in solving high-dimensional nonlinear problems as well as saves tremendous amount of time spent on training neural networks. Another essential aspect of EnSF is its analytical update step, gradually incorporating data information into the score function, which is crucial in mitigating the degeneracy issue faced when dealing with very high-dimensional nonlinear filtering problems. High-dimensional Lorenz systems are used to demonstrate the performance of our method. EnSF provides surprisingly impressive performance in reliably tracking extremely high-dimensional Lorenz systems (up to 1,000,000 dimension) with highly nonlinear observation processes, which is a well-known challenging problem for existing filtering methods.