 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeUni-AIMS: AI-Powered Microscopy Image Analysis
May 11, 2025This paper presents a systematic solution for the intelligent recognition and automatic analysis of microscopy images. We developed a data engine that generates high-quality annotated datasets through a combination of the collection of diverse microscopy images from experiments, synthetic data generation and a human-in-the-loop annotation process. To address the unique challenges of microscopy images, we propose a segmentation model capable of robustly detecting both small and large objects. The model effectively identifies and separates thousands of closely situated targets, even in cluttered visual environments. Furthermore, our solution supports the precise automatic recognition of image scale bars, an essential feature in quantitative microscopic analysis. Building upon these components, we have constructed a comprehensive intelligent analysis platform and validated its effectiveness and practicality in real-world applications. This study not only advances automatic recognition in microscopy imaging but also ensures scalability and generalizability across multiple application domains, offering a powerful tool for automated microscopic analysis in interdisciplinary research.
MolParser: End-to-end Visual Recognition of Molecule Structures in the Wild
Nov 17, 2024



In recent decades, chemistry publications and patents have increased rapidly. A significant portion of key information is embedded in molecular structure figures, complicating large-scale literature searches and limiting the application of large language models in fields such as biology, chemistry, and pharmaceuticals. The automatic extraction of precise chemical structures is of critical importance. However, the presence of numerous Markush structures in real-world documents, along with variations in molecular image quality, drawing styles, and noise, significantly limits the performance of existing optical chemical structure recognition (OCSR) methods. We present MolParser, a novel end-to-end OCSR method that efficiently and accurately recognizes chemical structures from real-world documents, including difficult Markush structure. We use a extended SMILES encoding rule to annotate our training dataset. Under this rule, we build MolParser-7M, the largest annotated molecular image dataset to our knowledge. While utilizing a large amount of synthetic data, we employed active learning methods to incorporate substantial in-the-wild data, specifically samples cropped from real patents and scientific literature, into the training process. We trained an end-to-end molecular image captioning model, MolParser, using a curriculum learning approach. MolParser significantly outperforms classical and learning-based methods across most scenarios, with potential for broader downstream applications. The dataset is publicly available.
SciLitLLM: How to Adapt LLMs for Scientific Literature Understanding
Aug 30, 2024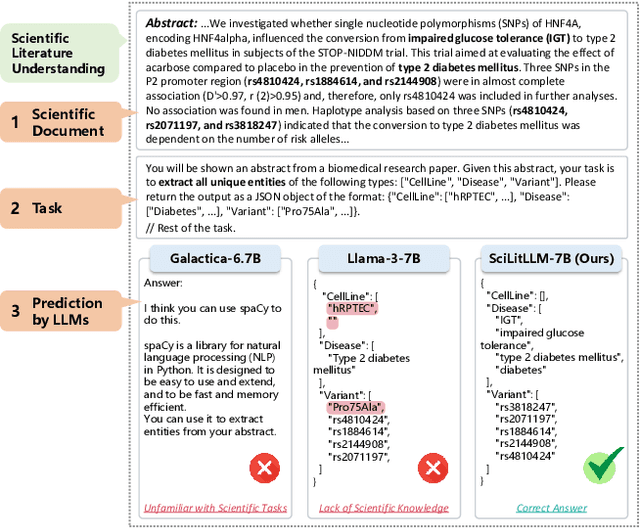
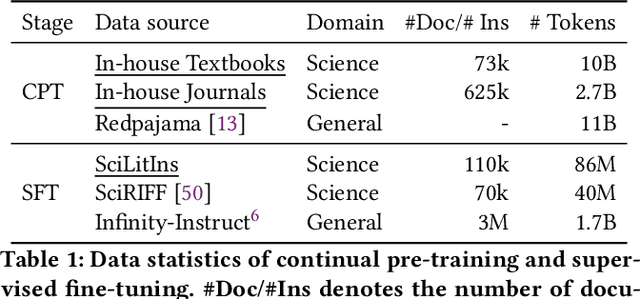
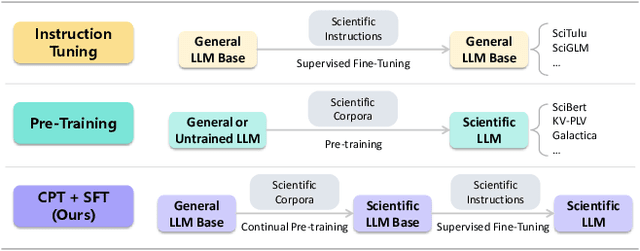
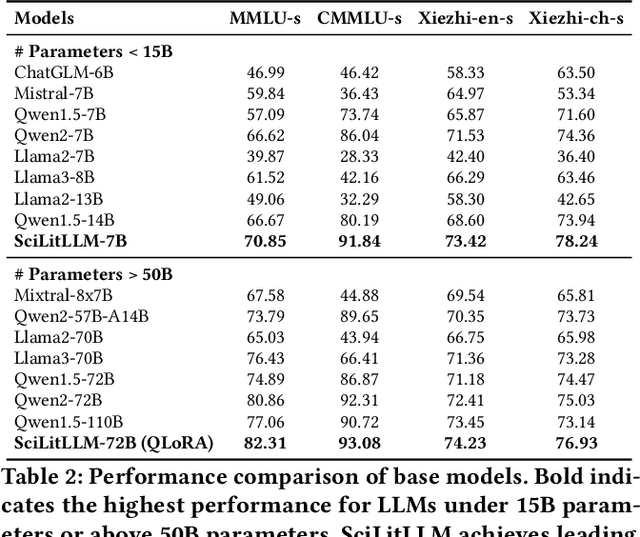
Scientific literature understanding is crucial for extracting targeted information and garnering insights, thereby significantly advancing scientific discovery. Despite the remarkable success of Large Language Models (LLMs), they face challenges in scientific literature understanding, primarily due to (1) a lack of scientific knowledge and (2) unfamiliarity with specialized scientific tasks. To develop an LLM specialized in scientific literature understanding, we propose a hybrid strategy that integrates continual pre-training (CPT) and supervised fine-tuning (SFT), to simultaneously infuse scientific domain knowledge and enhance instruction-following capabilities for domain-specific tasks.cIn this process, we identify two key challenges: (1) constructing high-quality CPT corpora, and (2) generating diverse SFT instructions. We address these challenges through a meticulous pipeline, including PDF text extraction, parsing content error correction, quality filtering, and synthetic instruction creation. Applying this strategy, we present a suite of LLMs: SciLitLLM, specialized in scientific literature understanding. These models demonstrate promising performance on scientific literature understanding benchmarks. Our contributions are threefold: (1) We present an effective framework that integrates CPT and SFT to adapt LLMs to scientific literature understanding, which can also be easily adapted to other domains. (2) We propose an LLM-based synthesis method to generate diverse and high-quality scientific instructions, resulting in a new instruction set -- SciLitIns -- for supervised fine-tuning in less-represented scientific domains. (3) SciLitLLM achieves promising performance improvements on scientific literature understanding benchmarks.
Uni-SMART: Universal Science Multimodal Analysis and Research Transformer
Mar 15, 2024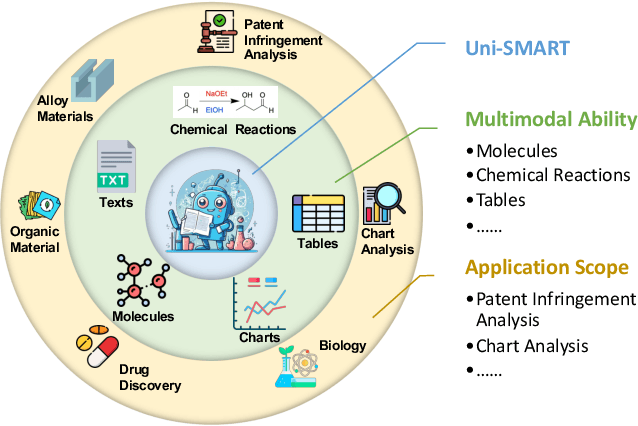
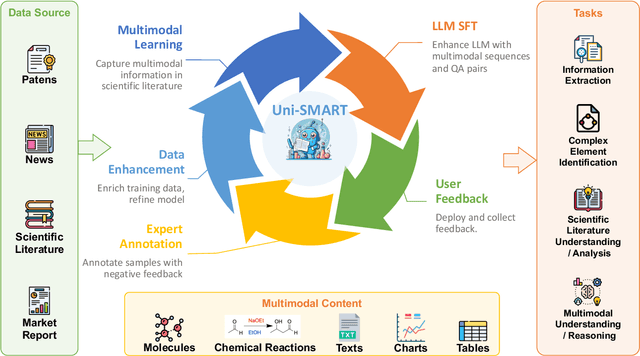
In scientific research and its application, scientific literature analysis is crucial as it allows researchers to build on the work of others. However, the fast growth of scientific knowledge has led to a massive increase in scholarly articles, making in-depth literature analysis increasingly challenging and time-consuming. The emergence of Large Language Models (LLMs) has offered a new way to address this challenge. Known for their strong abilities in summarizing texts, LLMs are seen as a potential tool to improve the analysis of scientific literature. However, existing LLMs have their own limits. Scientific literature often includes a wide range of multimodal elements, such as molecular structure, tables, and charts, which are hard for text-focused LLMs to understand and analyze. This issue points to the urgent need for new solutions that can fully understand and analyze multimodal content in scientific literature. To answer this demand, we present Uni-SMART (Universal Science Multimodal Analysis and Research Transformer), an innovative model designed for in-depth understanding of multimodal scientific literature. Through rigorous quantitative evaluation across several domains, Uni-SMART demonstrates superior performance over leading text-focused LLMs. Furthermore, our exploration extends to practical applications, including patent infringement detection and nuanced analysis of charts. These applications not only highlight Uni-SMART's adaptability but also its potential to revolutionize how we interact with scientific literature.
SciAssess: Benchmarking LLM Proficiency in Scientific Literature Analysis
Mar 15, 2024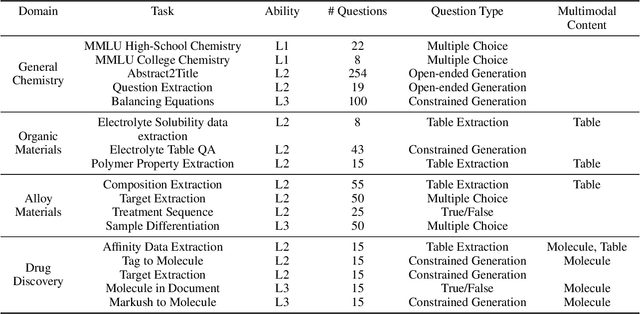

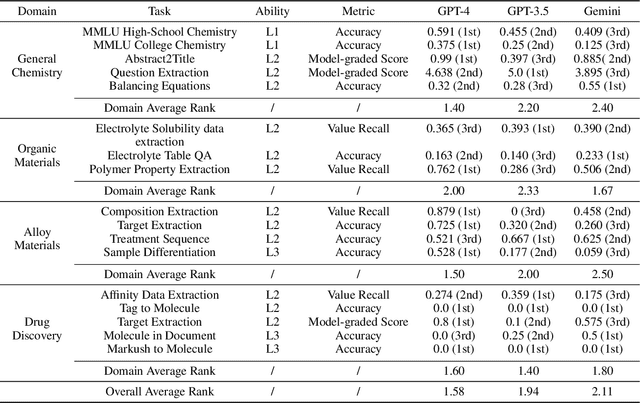
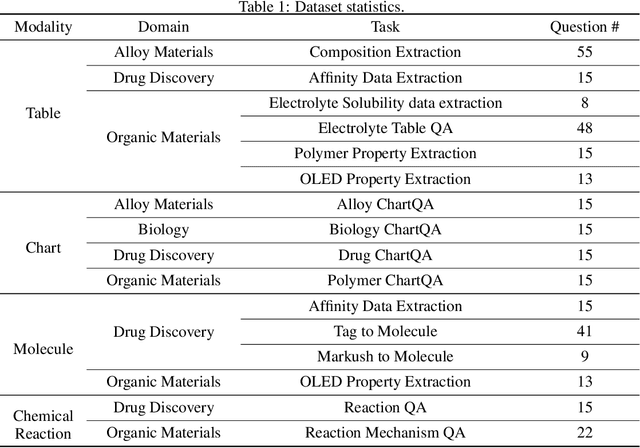
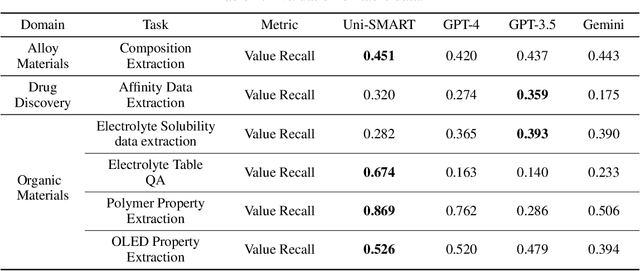
Recent breakthroughs in Large Language Models (LLMs) have revolutionized natural language understanding and generation, igniting a surge of interest in leveraging these technologies in the field of scientific literature analysis. Existing benchmarks, however, inadequately evaluate the proficiency of LLMs in scientific literature analysis, especially in scenarios involving complex comprehension and multimodal data. In response, we introduced SciAssess, a benchmark tailored for the in-depth analysis of scientific literature, crafted to provide a thorough assessment of LLMs' efficacy. SciAssess focuses on evaluating LLMs' abilities in memorization, comprehension, and analysis within the context of scientific literature analysis. It includes representative tasks from diverse scientific fields, such as general chemistry, organic materials, and alloy materials. And rigorous quality control measures ensure its reliability in terms of correctness, anonymization, and copyright compliance. SciAssess evaluates leading LLMs, including GPT-4, GPT-3.5, and Gemini, identifying their strengths and aspects for improvement and supporting the ongoing development of LLM applications in scientific literature analysis. SciAssess and its resources are made available at https://sci-assess.github.io, offering a valuable tool for advancing LLM capabilities in scientific literature analysis.
The Multi-modality Cell Segmentation Challenge: Towards Universal Solutions
Aug 10, 2023Cell segmentation is a critical step for quantitative single-cell analysis in microscopy images. Existing cell segmentation methods are often tailored to specific modalities or require manual interventions to specify hyperparameters in different experimental settings. Here, we present a multi-modality cell segmentation benchmark, comprising over 1500 labeled images derived from more than 50 diverse biological experiments. The top participants developed a Transformer-based deep-learning algorithm that not only exceeds existing methods, but can also be applied to diverse microscopy images across imaging platforms and tissue types without manual parameter adjustments. This benchmark and the improved algorithm offer promising avenues for more accurate and versatile cell analysis in microscopy imaging.
Power Efficient Video Super-Resolution on Mobile NPUs with Deep Learning, Mobile AI & AIM 2022 challenge: Report
Nov 07, 2022



Video super-resolution is one of the most popular tasks on mobile devices, being widely used for an automatic improvement of low-bitrate and low-resolution video streams. While numerous solutions have been proposed for this problem, they are usually quite computationally demanding, demonstrating low FPS rates and power efficiency on mobile devices. In this Mobile AI challenge, we address this problem and propose the participants to design an end-to-end real-time video super-resolution solution for mobile NPUs optimized for low energy consumption. The participants were provided with the REDS training dataset containing video sequences for a 4X video upscaling task. The runtime and power efficiency of all models was evaluated on the powerful MediaTek Dimensity 9000 platform with a dedicated AI processing unit capable of accelerating floating-point and quantized neural networks. All proposed solutions are fully compatible with the above NPU, demonstrating an up to 500 FPS rate and 0.2 [Watt / 30 FPS] power consumption. A detailed description of all models developed in the challenge is provided in this paper.