 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAPEX: Learning Adaptive Priorities for Multi-Objective Alignment in Vision-Language Generation
Jan 10, 2026Multi-objective alignment for text-to-image generation is commonly implemented via static linear scalarization, but fixed weights often fail under heterogeneous rewards, leading to optimization imbalance where models overfit high-variance, high-responsiveness objectives (e.g., OCR) while under-optimizing perceptual goals. We identify two mechanistic causes: variance hijacking, where reward dispersion induces implicit reweighting that dominates the normalized training signal, and gradient conflicts, where competing objectives produce opposing update directions and trigger seesaw-like oscillations. We propose APEX (Adaptive Priority-based Efficient X-objective Alignment), which stabilizes heterogeneous rewards with Dual-Stage Adaptive Normalization and dynamically schedules objectives via P^3 Adaptive Priorities that combine learning potential, conflict penalty, and progress need. On Stable Diffusion 3.5, APEX achieves improved Pareto trade-offs across four heterogeneous objectives, with balanced gains of +1.31 PickScore, +0.35 DeQA, and +0.53 Aesthetics while maintaining competitive OCR accuracy, mitigating the instability of multi-objective alignment.
SciLitLLM: How to Adapt LLMs for Scientific Literature Understanding
Aug 30, 2024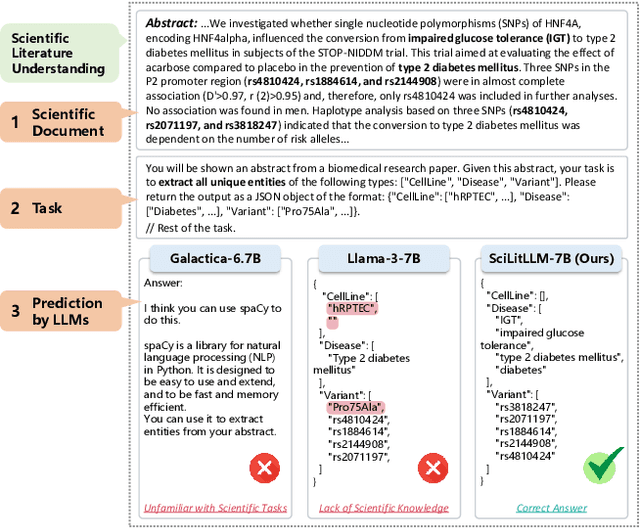
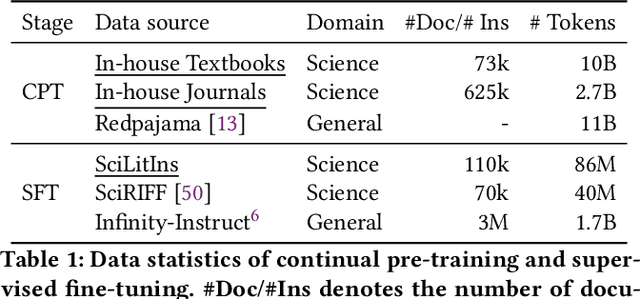
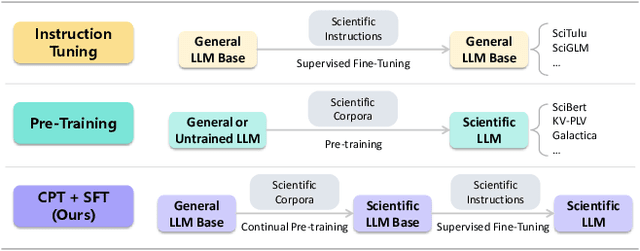
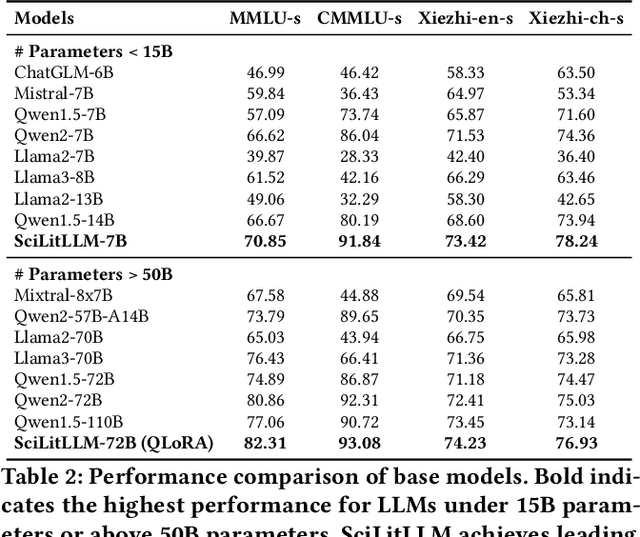
Scientific literature understanding is crucial for extracting targeted information and garnering insights, thereby significantly advancing scientific discovery. Despite the remarkable success of Large Language Models (LLMs), they face challenges in scientific literature understanding, primarily due to (1) a lack of scientific knowledge and (2) unfamiliarity with specialized scientific tasks. To develop an LLM specialized in scientific literature understanding, we propose a hybrid strategy that integrates continual pre-training (CPT) and supervised fine-tuning (SFT), to simultaneously infuse scientific domain knowledge and enhance instruction-following capabilities for domain-specific tasks.cIn this process, we identify two key challenges: (1) constructing high-quality CPT corpora, and (2) generating diverse SFT instructions. We address these challenges through a meticulous pipeline, including PDF text extraction, parsing content error correction, quality filtering, and synthetic instruction creation. Applying this strategy, we present a suite of LLMs: SciLitLLM, specialized in scientific literature understanding. These models demonstrate promising performance on scientific literature understanding benchmarks. Our contributions are threefold: (1) We present an effective framework that integrates CPT and SFT to adapt LLMs to scientific literature understanding, which can also be easily adapted to other domains. (2) We propose an LLM-based synthesis method to generate diverse and high-quality scientific instructions, resulting in a new instruction set -- SciLitIns -- for supervised fine-tuning in less-represented scientific domains. (3) SciLitLLM achieves promising performance improvements on scientific literature understanding benchmarks.