 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAPEX: Learning Adaptive Priorities for Multi-Objective Alignment in Vision-Language Generation
Jan 10, 2026Multi-objective alignment for text-to-image generation is commonly implemented via static linear scalarization, but fixed weights often fail under heterogeneous rewards, leading to optimization imbalance where models overfit high-variance, high-responsiveness objectives (e.g., OCR) while under-optimizing perceptual goals. We identify two mechanistic causes: variance hijacking, where reward dispersion induces implicit reweighting that dominates the normalized training signal, and gradient conflicts, where competing objectives produce opposing update directions and trigger seesaw-like oscillations. We propose APEX (Adaptive Priority-based Efficient X-objective Alignment), which stabilizes heterogeneous rewards with Dual-Stage Adaptive Normalization and dynamically schedules objectives via P^3 Adaptive Priorities that combine learning potential, conflict penalty, and progress need. On Stable Diffusion 3.5, APEX achieves improved Pareto trade-offs across four heterogeneous objectives, with balanced gains of +1.31 PickScore, +0.35 DeQA, and +0.53 Aesthetics while maintaining competitive OCR accuracy, mitigating the instability of multi-objective alignment.
Phenome-Wide Multi-Omics Integration Uncovers Distinct Archetypes of Human Aging
Oct 14, 2025Aging is a highly complex and heterogeneous process that progresses at different rates across individuals, making biological age (BA) a more accurate indicator of physiological decline than chronological age. While previous studies have built aging clocks using single-omics data, they often fail to capture the full molecular complexity of human aging. In this work, we leveraged the Human Phenotype Project, a large-scale cohort of 12,000 adults aged 30--70 years, with extensive longitudinal profiling that includes clinical, behavioral, environmental, and multi-omics datasets -- spanning transcriptomics, lipidomics, metabolomics, and the microbiome. By employing advanced machine learning frameworks capable of modeling nonlinear biological dynamics, we developed and rigorously validated a multi-omics aging clock that robustly predicts diverse health outcomes and future disease risk. Unsupervised clustering of the integrated molecular profiles from multi-omics uncovered distinct biological subtypes of aging, revealing striking heterogeneity in aging trajectories and pinpointing pathway-specific alterations associated with different aging patterns. These findings demonstrate the power of multi-omics integration to decode the molecular landscape of aging and lay the groundwork for personalized healthspan monitoring and precision strategies to prevent age-related diseases.
Towards Robust Visual Continual Learning with Multi-Prototype Supervision
Sep 19, 2025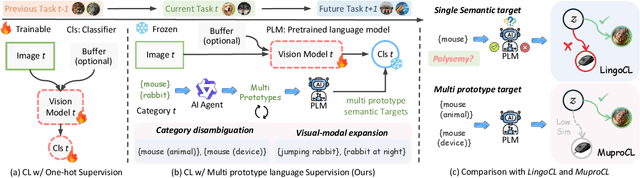
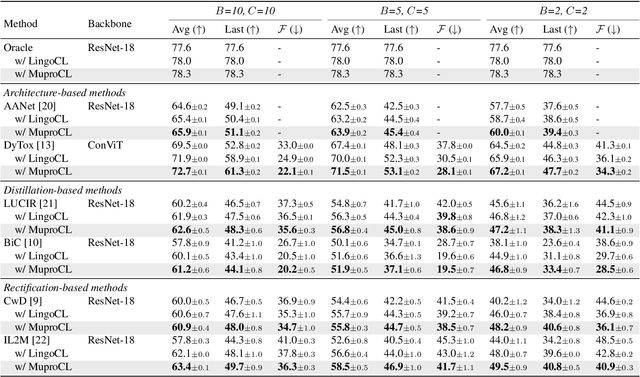
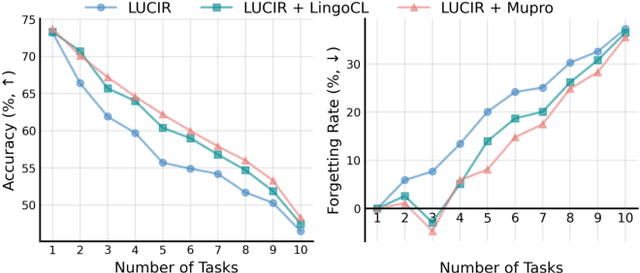
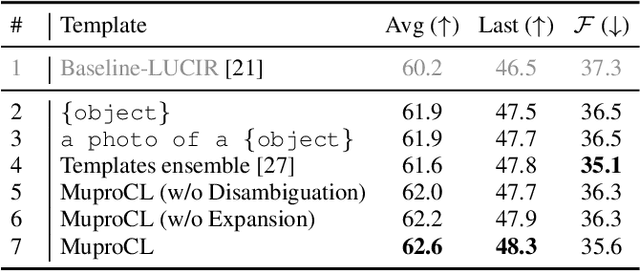
Language-guided supervision, which utilizes a frozen semantic target from a Pretrained Language Model (PLM), has emerged as a promising paradigm for visual Continual Learning (CL). However, relying on a single target introduces two critical limitations: 1) semantic ambiguity, where a polysemous category name results in conflicting visual representations, and 2) intra-class visual diversity, where a single prototype fails to capture the rich variety of visual appearances within a class. To this end, we propose MuproCL, a novel framework that replaces the single target with multiple, context-aware prototypes. Specifically, we employ a lightweight LLM agent to perform category disambiguation and visual-modal expansion to generate a robust set of semantic prototypes. A LogSumExp aggregation mechanism allows the vision model to adaptively align with the most relevant prototype for a given image. Extensive experiments across various CL baselines demonstrate that MuproCL consistently enhances performance and robustness, establishing a more effective path for language-guided continual learning.
Meta-rater: A Multi-dimensional Data Selection Method for Pre-training Language Models
Apr 19, 2025The composition of pre-training datasets for large language models (LLMs) remains largely undisclosed, hindering transparency and efforts to optimize data quality, a critical driver of model performance. Current data selection methods, such as natural language quality assessments, diversity-based filters, and classifier-based approaches, are limited by single-dimensional evaluation or redundancy-focused strategies. To address these gaps, we propose PRRC to evaluate data quality across Professionalism, Readability, Reasoning, and Cleanliness. We further introduce Meta-rater, a multi-dimensional data selection method that integrates these dimensions with existing quality metrics through learned optimal weightings. Meta-rater employs proxy models to train a regression model that predicts validation loss, enabling the identification of optimal combinations of quality scores. Experiments demonstrate that Meta-rater doubles convergence speed for 1.3B parameter models and improves downstream task performance by 3.23, with scalable benefits observed in 3.3B models trained on 100B tokens. Additionally, we release the annotated SlimPajama-627B dataset, labeled across 25 quality metrics (including PRRC), to advance research in data-centric LLM development. Our work establishes that holistic, multi-dimensional quality integration significantly outperforms conventional single-dimension approaches, offering a scalable paradigm for enhancing pre-training efficiency and model capability.
Unsupervised Topic Models are Data Mixers for Pre-training Language Models
Feb 24, 2025The performance of large language models (LLMs) is significantly affected by the quality and composition of their pre-training data, which is inherently diverse, spanning various domains, sources, and topics. Effectively integrating these heterogeneous data sources is crucial for optimizing LLM performance. Previous research has predominantly concentrated on domain-based data mixing, often neglecting the nuanced topic-level characteristics of the data. To address this gap, we propose a simple yet effective topic-based data mixing strategy that utilizes fine-grained topics generated through our topic modeling method, DataWeave. DataWeave employs a multi-stage clustering process to group semantically similar documents and utilizes LLMs to generate detailed topics, thereby facilitating a more nuanced understanding of dataset composition. Our strategy employs heuristic methods to upsample or downsample specific topics, which significantly enhances LLM performance on downstream tasks, achieving superior results compared to previous, more complex data mixing approaches. Furthermore, we confirm that the topics Science and Relationships are particularly effective, yielding the most substantial performance improvements. We will make our code and datasets publicly available.
Multi-Agent Collaborative Data Selection for Efficient LLM Pretraining
Oct 10, 2024



Efficient data selection is crucial to accelerate the pretraining of large language models (LLMs). While various methods have been proposed to enhance data efficiency, limited research has addressed the inherent conflicts between these approaches to achieve optimal data selection for LLM pretraining. To tackle this problem, we propose a novel multi-agent collaborative data selection mechanism. In this framework, each data selection method serves as an independent agent, and an agent console is designed to dynamically integrate the information from all agents throughout the LLM training process. We conduct extensive empirical studies to evaluate our multi-agent framework. The experimental results demonstrate that our approach significantly improves data efficiency, accelerates convergence in LLM training, and achieves an average performance gain of 10.5% across multiple language model benchmarks compared to the state-of-the-art methods.
Harnessing Diversity for Important Data Selection in Pretraining Large Language Models
Sep 25, 2024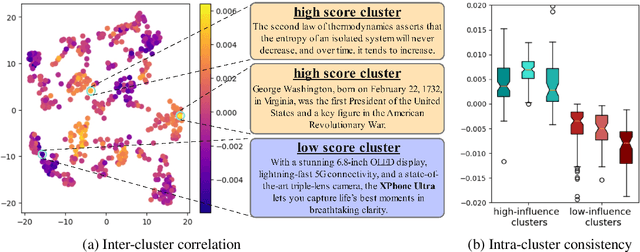
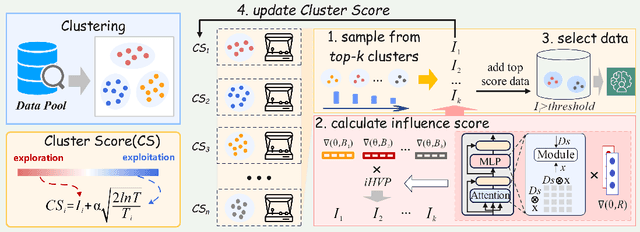
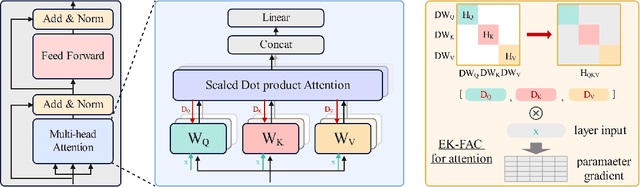
Data selection is of great significance in pre-training large language models, given the variation in quality within the large-scale available training corpora. To achieve this, researchers are currently investigating the use of data influence to measure the importance of data instances, $i.e.,$ a high influence score indicates that incorporating this instance to the training set is likely to enhance the model performance. Consequently, they select the top-$k$ instances with the highest scores. However, this approach has several limitations. (1) Computing the influence of all available data is time-consuming. (2) The selected data instances are not diverse enough, which may hinder the pre-trained model's ability to generalize effectively to various downstream tasks. In this paper, we introduce \texttt{Quad}, a data selection approach that considers both quality and diversity by using data influence to achieve state-of-the-art pre-training results. In particular, noting that attention layers capture extensive semantic details, we have adapted the accelerated $iHVP$ computation methods for attention layers, enhancing our ability to evaluate the influence of data, $i.e.,$ its quality. For the diversity, \texttt{Quad} clusters the dataset into similar data instances within each cluster and diverse instances across different clusters. For each cluster, if we opt to select data from it, we take some samples to evaluate the influence to prevent processing all instances. To determine which clusters to select, we utilize the classic Multi-Armed Bandit method, treating each cluster as an arm. This approach favors clusters with highly influential instances (ensuring high quality) or clusters that have been selected less frequently (ensuring diversity), thereby well balancing between quality and diversity.
Cause-Aware Empathetic Response Generation via Chain-of-Thought Fine-Tuning
Aug 21, 2024



Empathetic response generation endows agents with the capability to comprehend dialogue contexts and react to expressed emotions. Previous works predominantly focus on leveraging the speaker's emotional labels, but ignore the importance of emotion cause reasoning in empathetic response generation, which hinders the model's capacity for further affective understanding and cognitive inference. In this paper, we propose a cause-aware empathetic generation approach by integrating emotions and causes through a well-designed Chain-of-Thought (CoT) prompt on Large Language Models (LLMs). Our approach can greatly promote LLMs' performance of empathy by instruction tuning and enhancing the role awareness of an empathetic listener in the prompt. Additionally, we propose to incorporate cause-oriented external knowledge from COMET into the prompt, which improves the diversity of generation and alleviates conflicts between internal and external knowledge at the same time. Experimental results on the benchmark dataset demonstrate that our approach on LLaMA-7b achieves state-of-the-art performance in both automatic and human evaluations.
BIBench: Benchmarking Data Analysis Knowledge of Large Language Models
Jan 01, 2024Large Language Models (LLMs) have demonstrated impressive capabilities across a wide range of tasks. However, their proficiency and reliability in the specialized domain of Data Analysis, particularly with a focus on data-driven thinking, remain uncertain. To bridge this gap, we introduce BIBench, a comprehensive benchmark designed to evaluate the data analysis capabilities of LLMs within the context of Business Intelligence (BI). BIBench assesses LLMs across three dimensions: 1) BI foundational knowledge, evaluating the models' numerical reasoning and familiarity with financial concepts; 2) BI knowledge application, determining the models' ability to quickly comprehend textual information and generate analysis questions from multiple views; and 3) BI technical skills, examining the models' use of technical knowledge to address real-world data analysis challenges. BIBench comprises 11 sub-tasks, spanning three categories of task types: classification, extraction, and generation. Additionally, we've developed BIChat, a domain-specific dataset with over a million data points, to fine-tune LLMs. We will release BIBenchmark, BIChat, and the evaluation scripts at \url{https://github.com/cubenlp/BIBench}. This benchmark aims to provide a measure for in-depth analysis of LLM abilities and foster the advancement of LLMs in the field of data analysis.