 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Survey on Temporal Knowledge Graph: Representation Learning and Applications
Mar 02, 2024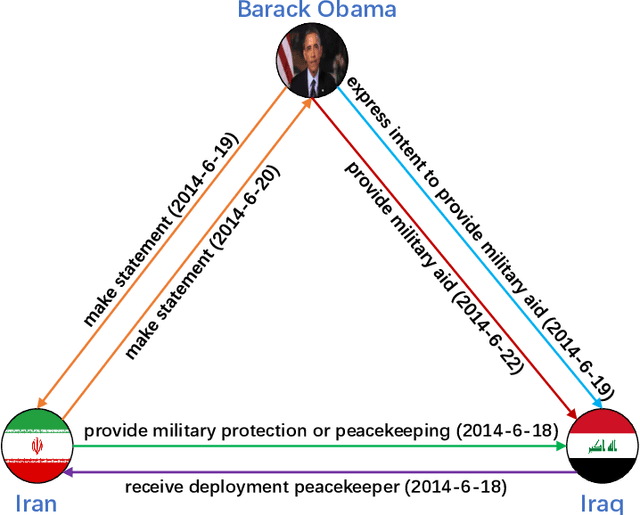
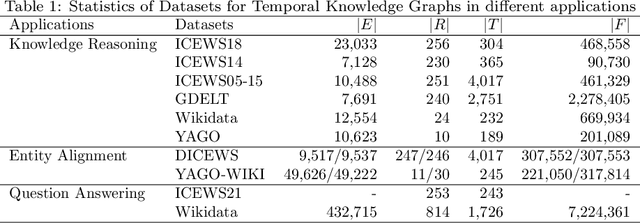
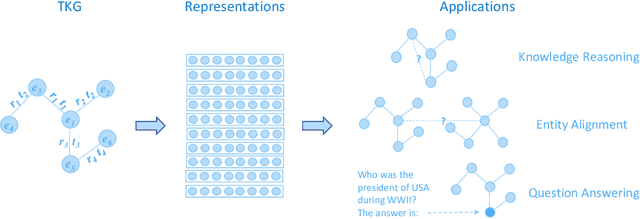

Knowledge graphs have garnered significant research attention and are widely used to enhance downstream applications. However, most current studies mainly focus on static knowledge graphs, whose facts do not change with time, and disregard their dynamic evolution over time. As a result, temporal knowledge graphs have attracted more attention because a large amount of structured knowledge exists only within a specific period. Knowledge graph representation learning aims to learn low-dimensional vector embeddings for entities and relations in a knowledge graph. The representation learning of temporal knowledge graphs incorporates time information into the standard knowledge graph framework and can model the dynamics of entities and relations over time. In this paper, we conduct a comprehensive survey of temporal knowledge graph representation learning and its applications. We begin with an introduction to the definitions, datasets, and evaluation metrics for temporal knowledge graph representation learning. Next, we propose a taxonomy based on the core technologies of temporal knowledge graph representation learning methods, and provide an in-depth analysis of different methods in each category. Finally, we present various downstream applications related to the temporal knowledge graphs. In the end, we conclude the paper and have an outlook on the future research directions in this area.
BIBench: Benchmarking Data Analysis Knowledge of Large Language Models
Jan 01, 2024Large Language Models (LLMs) have demonstrated impressive capabilities across a wide range of tasks. However, their proficiency and reliability in the specialized domain of Data Analysis, particularly with a focus on data-driven thinking, remain uncertain. To bridge this gap, we introduce BIBench, a comprehensive benchmark designed to evaluate the data analysis capabilities of LLMs within the context of Business Intelligence (BI). BIBench assesses LLMs across three dimensions: 1) BI foundational knowledge, evaluating the models' numerical reasoning and familiarity with financial concepts; 2) BI knowledge application, determining the models' ability to quickly comprehend textual information and generate analysis questions from multiple views; and 3) BI technical skills, examining the models' use of technical knowledge to address real-world data analysis challenges. BIBench comprises 11 sub-tasks, spanning three categories of task types: classification, extraction, and generation. Additionally, we've developed BIChat, a domain-specific dataset with over a million data points, to fine-tune LLMs. We will release BIBenchmark, BIChat, and the evaluation scripts at \url{https://github.com/cubenlp/BIBench}. This benchmark aims to provide a measure for in-depth analysis of LLM abilities and foster the advancement of LLMs in the field of data analysis.