 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFùxì: A Benchmark for Evaluating Language Models on Ancient Chinese Text Understanding and Generation
Mar 20, 2025



Ancient Chinese text processing presents unique challenges for large language models (LLMs) due to its distinct linguistic features, complex structural constraints, and rich cultural context. While existing benchmarks have primarily focused on evaluating comprehension through multiple-choice questions, there remains a critical gap in assessing models' generative capabilities in classical Chinese. We introduce F\`ux\`i, a comprehensive benchmark that evaluates both understanding and generation capabilities across 21 diverse tasks. Our benchmark distinguishes itself through three key contributions: (1) balanced coverage of both comprehension and generation tasks, including novel tasks like poetry composition and couplet completion, (2) specialized evaluation metrics designed specifically for classical Chinese text generation, combining rule-based verification with fine-tuned LLM evaluators, and (3) a systematic assessment framework that considers both linguistic accuracy and cultural authenticity. Through extensive evaluation of state-of-the-art LLMs, we reveal significant performance gaps between understanding and generation tasks, with models achieving promising results in comprehension but struggling considerably in generation tasks, particularly those requiring deep cultural knowledge and adherence to classical formats. Our findings highlight the current limitations in ancient Chinese text processing and provide insights for future model development. The benchmark, evaluation toolkit, and baseline results are publicly available to facilitate research in this domain.
BIBench: Benchmarking Data Analysis Knowledge of Large Language Models
Jan 01, 2024Large Language Models (LLMs) have demonstrated impressive capabilities across a wide range of tasks. However, their proficiency and reliability in the specialized domain of Data Analysis, particularly with a focus on data-driven thinking, remain uncertain. To bridge this gap, we introduce BIBench, a comprehensive benchmark designed to evaluate the data analysis capabilities of LLMs within the context of Business Intelligence (BI). BIBench assesses LLMs across three dimensions: 1) BI foundational knowledge, evaluating the models' numerical reasoning and familiarity with financial concepts; 2) BI knowledge application, determining the models' ability to quickly comprehend textual information and generate analysis questions from multiple views; and 3) BI technical skills, examining the models' use of technical knowledge to address real-world data analysis challenges. BIBench comprises 11 sub-tasks, spanning three categories of task types: classification, extraction, and generation. Additionally, we've developed BIChat, a domain-specific dataset with over a million data points, to fine-tune LLMs. We will release BIBenchmark, BIChat, and the evaluation scripts at \url{https://github.com/cubenlp/BIBench}. This benchmark aims to provide a measure for in-depth analysis of LLM abilities and foster the advancement of LLMs in the field of data analysis.
Adversarial Self-Supervised Data-Free Distillation for Text Classification
Oct 10, 2020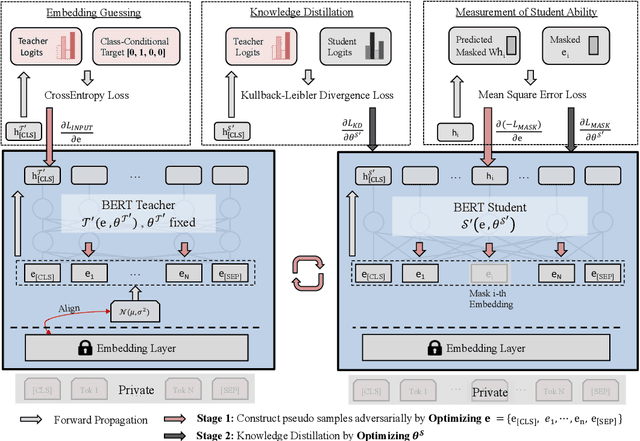



Large pre-trained transformer-based language models have achieved impressive results on a wide range of NLP tasks. In the past few years, Knowledge Distillation(KD) has become a popular paradigm to compress a computationally expensive model to a resource-efficient lightweight model. However, most KD algorithms, especially in NLP, rely on the accessibility of the original training dataset, which may be unavailable due to privacy issues. To tackle this problem, we propose a novel two-stage data-free distillation method, named Adversarial self-Supervised Data-Free Distillation (AS-DFD), which is designed for compressing large-scale transformer-based models (e.g., BERT). To avoid text generation in discrete space, we introduce a Plug & Play Embedding Guessing method to craft pseudo embeddings from the teacher's hidden knowledge. Meanwhile, with a self-supervised module to quantify the student's ability, we adapt the difficulty of pseudo embeddings in an adversarial training manner. To the best of our knowledge, our framework is the first data-free distillation framework designed for NLP tasks. We verify the effectiveness of our method on several text classification datasets.