 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAPEX: Learning Adaptive Priorities for Multi-Objective Alignment in Vision-Language Generation
Jan 10, 2026Multi-objective alignment for text-to-image generation is commonly implemented via static linear scalarization, but fixed weights often fail under heterogeneous rewards, leading to optimization imbalance where models overfit high-variance, high-responsiveness objectives (e.g., OCR) while under-optimizing perceptual goals. We identify two mechanistic causes: variance hijacking, where reward dispersion induces implicit reweighting that dominates the normalized training signal, and gradient conflicts, where competing objectives produce opposing update directions and trigger seesaw-like oscillations. We propose APEX (Adaptive Priority-based Efficient X-objective Alignment), which stabilizes heterogeneous rewards with Dual-Stage Adaptive Normalization and dynamically schedules objectives via P^3 Adaptive Priorities that combine learning potential, conflict penalty, and progress need. On Stable Diffusion 3.5, APEX achieves improved Pareto trade-offs across four heterogeneous objectives, with balanced gains of +1.31 PickScore, +0.35 DeQA, and +0.53 Aesthetics while maintaining competitive OCR accuracy, mitigating the instability of multi-objective alignment.
SID: Benchmarking Guided Instruction Capabilities in STEM Education with a Socratic Interdisciplinary Dialogues Dataset
Aug 06, 2025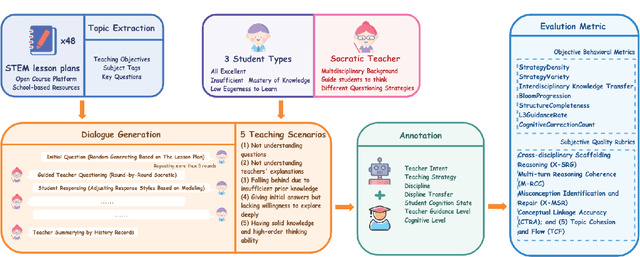
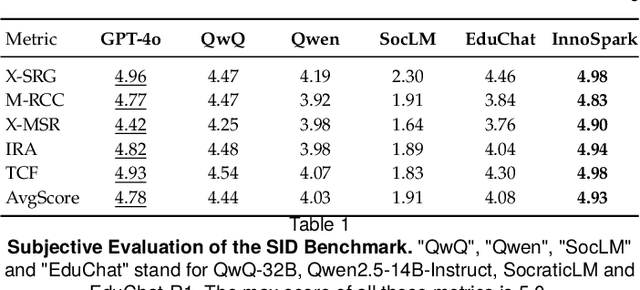
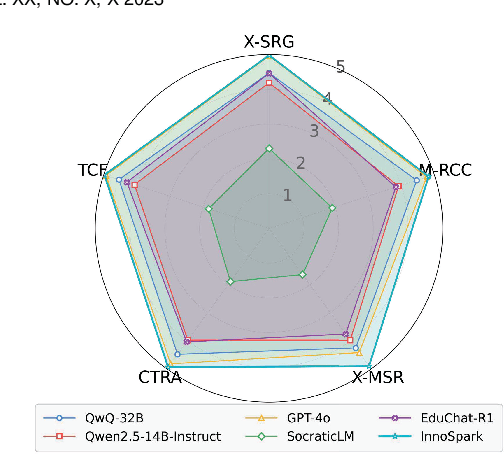
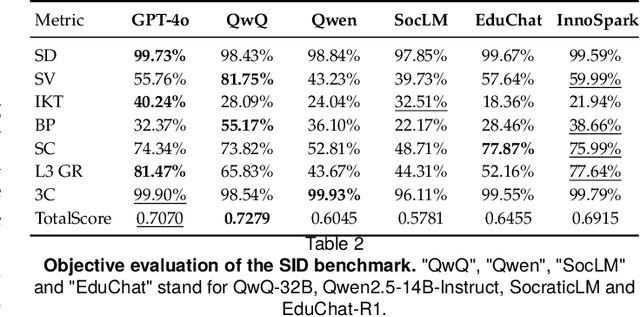
Fostering students' abilities for knowledge integration and transfer in complex problem-solving scenarios is a core objective of modern education, and interdisciplinary STEM is a key pathway to achieve this, yet it requires expert guidance that is difficult to scale. While LLMs offer potential in this regard, their true capability for guided instruction remains unclear due to the lack of an effective evaluation benchmark. To address this, we introduce SID, the first benchmark designed to systematically evaluate the higher-order guidance capabilities of LLMs in multi-turn, interdisciplinary Socratic dialogues. Our contributions include a large-scale dataset of 10,000 dialogue turns across 48 complex STEM projects, a novel annotation schema for capturing deep pedagogical features, and a new suite of evaluation metrics (e.g., X-SRG). Baseline experiments confirm that even state-of-the-art LLMs struggle to execute effective guided dialogues that lead students to achieve knowledge integration and transfer. This highlights the critical value of our benchmark in driving the development of more pedagogically-aware LLMs.
Meta-rater: A Multi-dimensional Data Selection Method for Pre-training Language Models
Apr 19, 2025The composition of pre-training datasets for large language models (LLMs) remains largely undisclosed, hindering transparency and efforts to optimize data quality, a critical driver of model performance. Current data selection methods, such as natural language quality assessments, diversity-based filters, and classifier-based approaches, are limited by single-dimensional evaluation or redundancy-focused strategies. To address these gaps, we propose PRRC to evaluate data quality across Professionalism, Readability, Reasoning, and Cleanliness. We further introduce Meta-rater, a multi-dimensional data selection method that integrates these dimensions with existing quality metrics through learned optimal weightings. Meta-rater employs proxy models to train a regression model that predicts validation loss, enabling the identification of optimal combinations of quality scores. Experiments demonstrate that Meta-rater doubles convergence speed for 1.3B parameter models and improves downstream task performance by 3.23, with scalable benefits observed in 3.3B models trained on 100B tokens. Additionally, we release the annotated SlimPajama-627B dataset, labeled across 25 quality metrics (including PRRC), to advance research in data-centric LLM development. Our work establishes that holistic, multi-dimensional quality integration significantly outperforms conventional single-dimension approaches, offering a scalable paradigm for enhancing pre-training efficiency and model capability.
Physics-informed deep learning for infectious disease forecasting
Jan 16, 2025



Accurate forecasting of contagious illnesses has become increasingly important to public health policymaking, and better prediction could prevent the loss of millions of lives. To better prepare for future pandemics, it is essential to improve forecasting methods and capabilities. In this work, we propose a new infectious disease forecasting model based on physics-informed neural networks (PINNs), an emerging area of scientific machine learning. The proposed PINN model incorporates dynamical systems representations of disease transmission into the loss function, thereby assimilating epidemiological theory and data using neural networks (NNs). Our approach is designed to prevent model overfitting, which often occurs when training deep learning models with observation data alone. In addition, we employ an additional sub-network to account for mobility, vaccination, and other covariates that influence the transmission rate, a key parameter in the compartment model. To demonstrate the capability of the proposed model, we examine the performance of the model using state-level COVID-19 data in California. Our simulation results show that predictions of PINN model on the number of cases, deaths, and hospitalizations are consistent with existing benchmarks. In particular, the PINN model outperforms the basic NN model and naive baseline forecast. We also show that the performance of the PINN model is comparable to a sophisticated Gaussian infection state space with time dependence (GISST) forecasting model that integrates the compartment model with a data observation model and a regression model for inferring parameters in the compartment model. Nonetheless, the PINN model offers a simpler structure and is easier to implement. Our results show that the proposed forecaster could potentially serve as a new computational tool to enhance the current capacity of infectious disease forecasting.
multiPI-TransBTS: A Multi-Path Learning Framework for Brain Tumor Image Segmentation Based on Multi-Physical Information
Sep 18, 2024Brain Tumor Segmentation (BraTS) plays a critical role in clinical diagnosis, treatment planning, and monitoring the progression of brain tumors. However, due to the variability in tumor appearance, size, and intensity across different MRI modalities, automated segmentation remains a challenging task. In this study, we propose a novel Transformer-based framework, multiPI-TransBTS, which integrates multi-physical information to enhance segmentation accuracy. The model leverages spatial information, semantic information, and multi-modal imaging data, addressing the inherent heterogeneity in brain tumor characteristics. The multiPI-TransBTS framework consists of an encoder, an Adaptive Feature Fusion (AFF) module, and a multi-source, multi-scale feature decoder. The encoder incorporates a multi-branch architecture to separately extract modality-specific features from different MRI sequences. The AFF module fuses information from multiple sources using channel-wise and element-wise attention, ensuring effective feature recalibration. The decoder combines both common and task-specific features through a Task-Specific Feature Introduction (TSFI) strategy, producing accurate segmentation outputs for Whole Tumor (WT), Tumor Core (TC), and Enhancing Tumor (ET) regions. Comprehensive evaluations on the BraTS2019 and BraTS2020 datasets demonstrate the superiority of multiPI-TransBTS over the state-of-the-art methods. The model consistently achieves better Dice coefficients, Hausdorff distances, and Sensitivity scores, highlighting its effectiveness in addressing the BraTS challenges. Our results also indicate the need for further exploration of the balance between precision and recall in the ET segmentation task. The proposed framework represents a significant advancement in BraTS, with potential implications for improving clinical outcomes for brain tumor patients.
Adaptive Inference: Theoretical Limits and Unexplored Opportunities
Feb 06, 2024This paper introduces the first theoretical framework for quantifying the efficiency and performance gain opportunity size of adaptive inference algorithms. We provide new approximate and exact bounds for the achievable efficiency and performance gains, supported by empirical evidence demonstrating the potential for 10-100x efficiency improvements in both Computer Vision and Natural Language Processing tasks without incurring any performance penalties. Additionally, we offer insights on improving achievable efficiency gains through the optimal selection and design of adaptive inference state spaces.
CasCIFF: A Cross-Domain Information Fusion Framework Tailored for Cascade Prediction in Social Networks
Aug 09, 2023Existing approaches for information cascade prediction fall into three main categories: feature-driven methods, point process-based methods, and deep learning-based methods. Among them, deep learning-based methods, characterized by its superior learning and representation capabilities, mitigates the shortcomings inherent of the other methods. However, current deep learning methods still face several persistent challenges. In particular, accurate representation of user attributes remains problematic due to factors such as fake followers and complex network configurations. Previous algorithms that focus on the sequential order of user activations often neglect the rich insights offered by activation timing. Furthermore, these techniques often fail to holistically integrate temporal and structural aspects, thus missing the nuanced propagation trends inherent in information cascades.To address these issues, we propose the Cross-Domain Information Fusion Framework (CasCIFF), which is tailored for information cascade prediction. This framework exploits multi-hop neighborhood information to make user embeddings robust. When embedding cascades, the framework intentionally incorporates timestamps, endowing it with the ability to capture evolving patterns of information diffusion. In particular, the CasCIFF seamlessly integrates the tasks of user classification and cascade prediction into a consolidated framework, thereby allowing the extraction of common features that prove useful for all tasks, a strategy anchored in the principles of multi-task learning.