 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeUni-SMART: Universal Science Multimodal Analysis and Research Transformer
Mar 15, 2024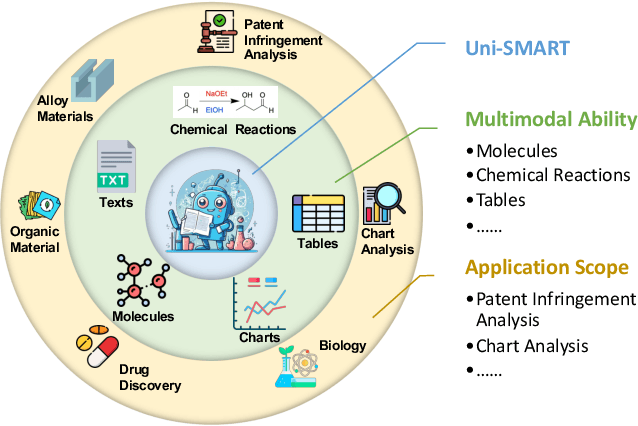
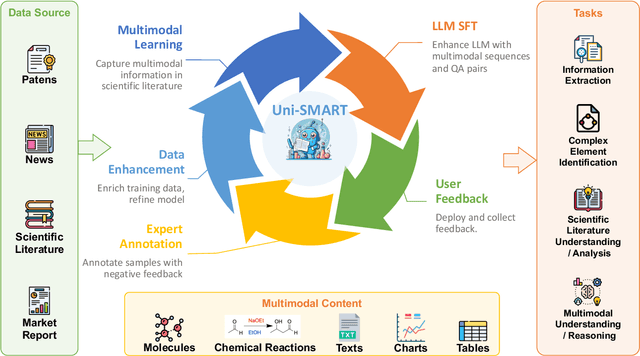
In scientific research and its application, scientific literature analysis is crucial as it allows researchers to build on the work of others. However, the fast growth of scientific knowledge has led to a massive increase in scholarly articles, making in-depth literature analysis increasingly challenging and time-consuming. The emergence of Large Language Models (LLMs) has offered a new way to address this challenge. Known for their strong abilities in summarizing texts, LLMs are seen as a potential tool to improve the analysis of scientific literature. However, existing LLMs have their own limits. Scientific literature often includes a wide range of multimodal elements, such as molecular structure, tables, and charts, which are hard for text-focused LLMs to understand and analyze. This issue points to the urgent need for new solutions that can fully understand and analyze multimodal content in scientific literature. To answer this demand, we present Uni-SMART (Universal Science Multimodal Analysis and Research Transformer), an innovative model designed for in-depth understanding of multimodal scientific literature. Through rigorous quantitative evaluation across several domains, Uni-SMART demonstrates superior performance over leading text-focused LLMs. Furthermore, our exploration extends to practical applications, including patent infringement detection and nuanced analysis of charts. These applications not only highlight Uni-SMART's adaptability but also its potential to revolutionize how we interact with scientific literature.
SciAssess: Benchmarking LLM Proficiency in Scientific Literature Analysis
Mar 15, 2024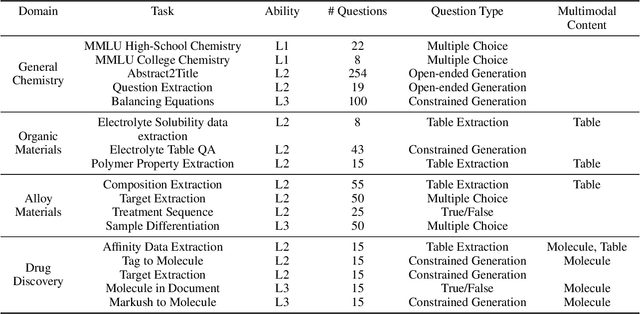
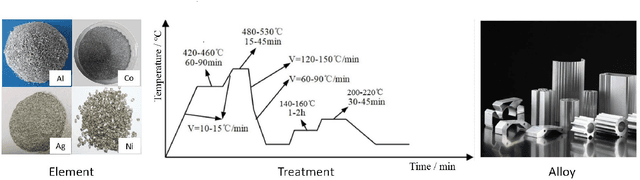

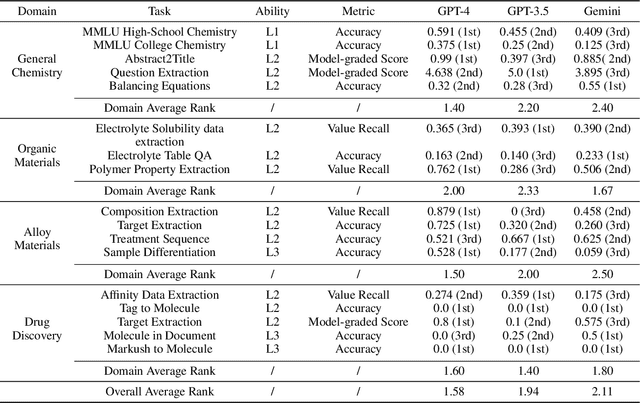
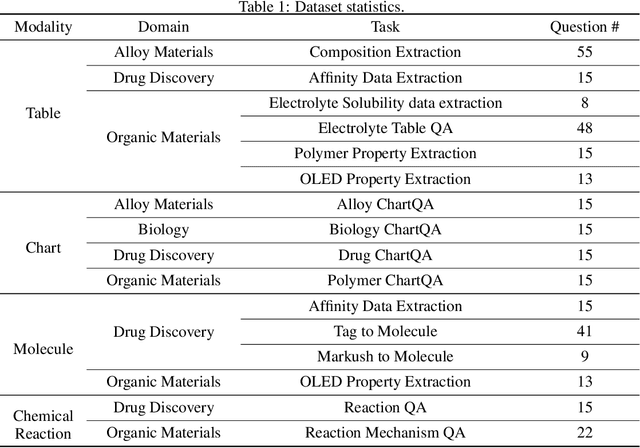
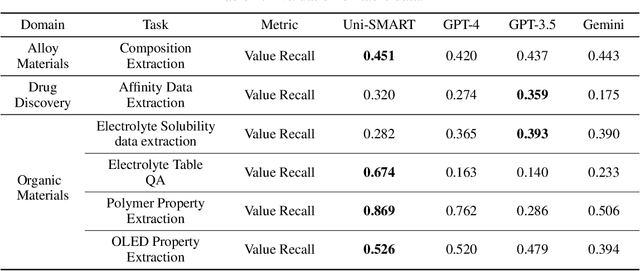
Recent breakthroughs in Large Language Models (LLMs) have revolutionized natural language understanding and generation, igniting a surge of interest in leveraging these technologies in the field of scientific literature analysis. Existing benchmarks, however, inadequately evaluate the proficiency of LLMs in scientific literature analysis, especially in scenarios involving complex comprehension and multimodal data. In response, we introduced SciAssess, a benchmark tailored for the in-depth analysis of scientific literature, crafted to provide a thorough assessment of LLMs' efficacy. SciAssess focuses on evaluating LLMs' abilities in memorization, comprehension, and analysis within the context of scientific literature analysis. It includes representative tasks from diverse scientific fields, such as general chemistry, organic materials, and alloy materials. And rigorous quality control measures ensure its reliability in terms of correctness, anonymization, and copyright compliance. SciAssess evaluates leading LLMs, including GPT-4, GPT-3.5, and Gemini, identifying their strengths and aspects for improvement and supporting the ongoing development of LLM applications in scientific literature analysis. SciAssess and its resources are made available at https://sci-assess.github.io, offering a valuable tool for advancing LLM capabilities in scientific literature analysis.
Cobra Effect in Reference-Free Image Captioning Metrics
Feb 18, 2024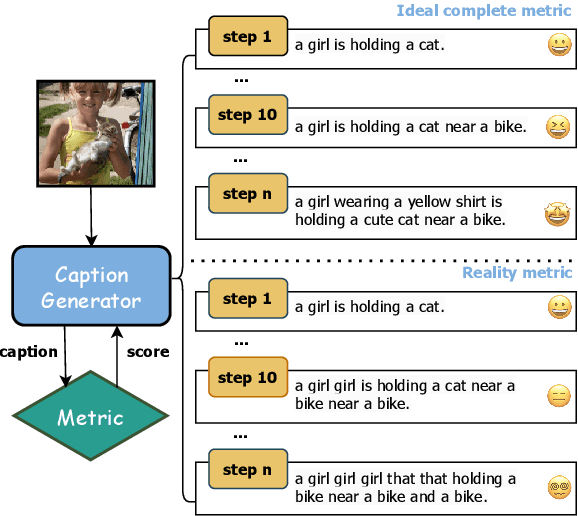

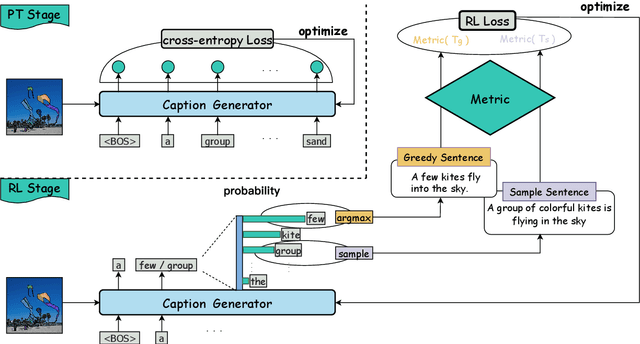
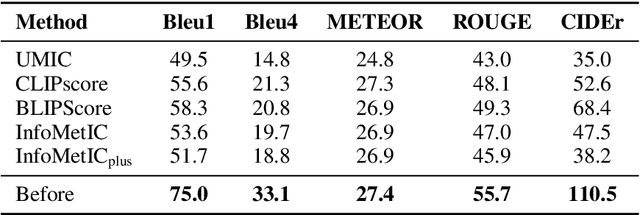
Evaluating the compatibility between textual descriptions and corresponding images represents a core endeavor within multi-modal research. In recent years, a proliferation of reference-free methods, leveraging visual-language pre-trained models (VLMs), has emerged. Empirical evidence has substantiated that these innovative approaches exhibit a higher correlation with human judgment, marking a significant advancement in the field. However, does a higher correlation with human evaluations alone sufficiently denote the complete of a metric? In response to this question, in this paper, we study if there are any deficiencies in reference-free metrics. Specifically, inspired by the Cobra Effect, we utilize metric scores as rewards to direct the captioning model toward generating descriptions that closely align with the metric's criteria. If a certain metric has flaws, it will be exploited by the model and reflected in the generated sentences. Our findings reveal that descriptions guided by these metrics contain significant flaws, e.g. incoherent statements and excessive repetition. Subsequently, we propose a novel method termed Self-Improving to rectify the identified shortcomings within these metrics. We employ GPT-4V as an evaluative tool to assess generated sentences and the result reveals that our approach achieves state-of-the-art (SOTA) performance. In addition, we also introduce a challenging evaluation benchmark called Flaws Caption to evaluate reference-free image captioning metrics comprehensively. Our code is available at https://github.com/aaronma2020/robust_captioning_metric
Bounding and Filling: A Fast and Flexible Framework for Image Captioning
Oct 15, 2023Most image captioning models following an autoregressive manner suffer from significant inference latency. Several models adopted a non-autoregressive manner to speed up the process. However, the vanilla non-autoregressive manner results in subpar performance, since it generates all words simultaneously, which fails to capture the relationships between words in a description. The semi-autoregressive manner employs a partially parallel method to preserve performance, but it sacrifices inference speed. In this paper, we introduce a fast and flexible framework for image captioning called BoFiCap based on bounding and filling techniques. The BoFiCap model leverages the inherent characteristics of image captioning tasks to pre-define bounding boxes for image regions and their relationships. Subsequently, the BoFiCap model fills corresponding words in each box using two-generation manners. Leveraging the box hints, our filling process allows each word to better perceive other words. Additionally, our model offers flexible image description generation: 1) by employing different generation manners based on speed or performance requirements, 2) producing varied sentences based on user-specified boxes. Experimental evaluations on the MS-COCO benchmark dataset demonstrate that our framework in a non-autoregressive manner achieves the state-of-the-art on task-specific metric CIDEr (125.6) while speeding up 9.22x than the baseline model with an autoregressive manner; in a semi-autoregressive manner, our method reaches 128.4 on CIDEr while a 3.69x speedup. Our code and data is available at https://github.com/ChangxinWang/BoFiCap.