 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCobra Effect in Reference-Free Image Captioning Metrics
Paper and Code
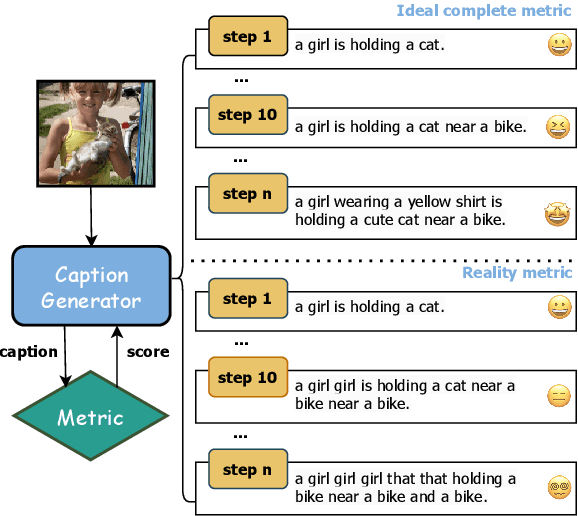

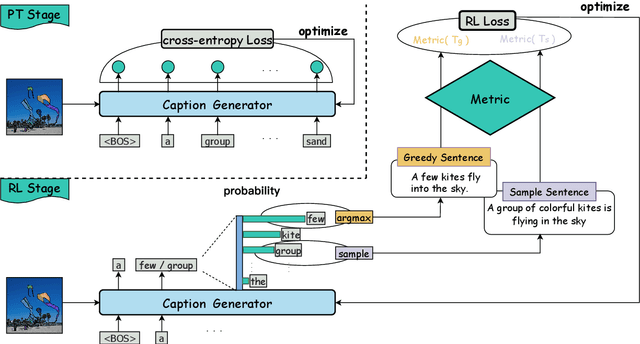
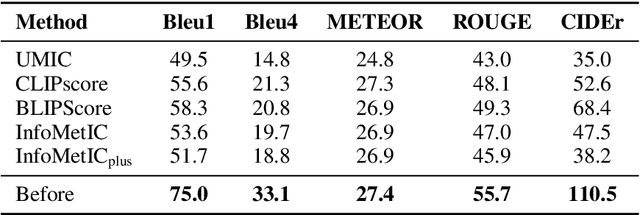
Evaluating the compatibility between textual descriptions and corresponding images represents a core endeavor within multi-modal research. In recent years, a proliferation of reference-free methods, leveraging visual-language pre-trained models (VLMs), has emerged. Empirical evidence has substantiated that these innovative approaches exhibit a higher correlation with human judgment, marking a significant advancement in the field. However, does a higher correlation with human evaluations alone sufficiently denote the complete of a metric? In response to this question, in this paper, we study if there are any deficiencies in reference-free metrics. Specifically, inspired by the Cobra Effect, we utilize metric scores as rewards to direct the captioning model toward generating descriptions that closely align with the metric's criteria. If a certain metric has flaws, it will be exploited by the model and reflected in the generated sentences. Our findings reveal that descriptions guided by these metrics contain significant flaws, e.g. incoherent statements and excessive repetition. Subsequently, we propose a novel method termed Self-Improving to rectify the identified shortcomings within these metrics. We employ GPT-4V as an evaluative tool to assess generated sentences and the result reveals that our approach achieves state-of-the-art (SOTA) performance. In addition, we also introduce a challenging evaluation benchmark called Flaws Caption to evaluate reference-free image captioning metrics comprehensively. Our code is available at https://github.com/aaronma2020/robust_captioning_metric