 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeWhen Simulation Lies: A Sim-to-Real Benchmark and Domain-Randomized RL Recipe for Tool-Use Agents
May 12, 2026Tool-use language agents are evaluated on benchmarks that assume clean inputs, unambiguous tool registries, and reliable APIs. Real deployments violate all these assumptions: user typos propagate into hallucinated tool names, a misconfigured request timeout can stall an agent indefinitely, and duplicate tool names across servers can freeze an SDK. We study these failures as a sim-to-real gap in the tool-use partially observable Markov decision process (POMDP), where deployment noise enters through the observation, action space, reward-relevant metadata, or transition dynamics. We introduce RobustBench-TC, a benchmark with 22 perturbation types organized by these four POMDP components, each grounded in a verified GitHub issue or documented tool-calling failure. Across 21 models from 1.5B to 32B parameters (including the closed-source o4-mini), the robustness profile is sharply uneven: observation perturbations reduce accuracy by less than 5%, while reward-relevant and transition perturbations reduce accuracy by roughly 40% and 30%, respectively; scale alone does not close these gaps. We then propose ToolRL-DR, a domain-randomization reinforcement learning (RL) recipe that trains a tool-use agent on perturbation-augmented trajectories spanning the three statically encodable POMDP components. On a 3B backbone, ToolRL-DR-Full retains roughly three-quarters of clean accuracy and reaches an aggregate perturbed accuracy comparable to open-source 14B function-calling baselines while substantially narrowing the gap to o4-mini. It closes approximately 27% of the Transition gap despite never seeing transition perturbations in training, suggesting that RL on adversarial static tool-use inputs induces a more persistent retry policy that transfers to unseen runtime failures. The dataset, code and benchmark leaderboard are publicly available.
Unveiling the Resilience of LLM-Enhanced Search Engines against Black-Hat SEO Manipulation
Mar 26, 2026The emergence of Large Language Model-enhanced Search Engines (LLMSEs) has revolutionized information retrieval by integrating web-scale search capabilities with AI-powered summarization. While these systems demonstrate improved efficiency over traditional search engines, their security implications against well-established black-hat Search Engine Optimization (SEO) attacks remain unexplored. In this paper, we present the first systematic study of SEO attacks targeting LLMSEs. Specifically, we examine ten representative LLMSE products (e.g., ChatGPT, Gemini) and construct SEO-Bench, a benchmark comprising 1,000 real-world black-hat SEO websites, to evaluate both open- and closed-source LLMSEs. Our measurements show that LLMSEs mitigate over 99.78% of traditional SEO attacks, with the phase of retrieval serving as the primary filter, intercepting the vast majority of malicious queries. We further propose and evaluate seven LLMSEO attack strategies, demonstrating that off-the-shelf LLMSEs are vulnerable to LLMSEO attacks, i.e., rewritten-query stuffing and segmented texts double the manipulation rate compared to the baseline. This work offers the first in-depth security analysis of the LLMSE ecosystem, providing practical insights for building more resilient AI-driven search systems. We have responsibly reported the identified issues to major vendors.
ERNIE 5.0 Technical Report
Feb 04, 2026In this report, we introduce ERNIE 5.0, a natively autoregressive foundation model desinged for unified multimodal understanding and generation across text, image, video, and audio. All modalities are trained from scratch under a unified next-group-of-tokens prediction objective, based on an ultra-sparse mixture-of-experts (MoE) architecture with modality-agnostic expert routing. To address practical challenges in large-scale deployment under diverse resource constraints, ERNIE 5.0 adopts a novel elastic training paradigm. Within a single pre-training run, the model learns a family of sub-models with varying depths, expert capacities, and routing sparsity, enabling flexible trade-offs among performance, model size, and inference latency in memory- or time-constrained scenarios. Moreover, we systematically address the challenges of scaling reinforcement learning to unified foundation models, thereby guaranteeing efficient and stable post-training under ultra-sparse MoE architectures and diverse multimodal settings. Extensive experiments demonstrate that ERNIE 5.0 achieves strong and balanced performance across multiple modalities. To the best of our knowledge, among publicly disclosed models, ERNIE 5.0 represents the first production-scale realization of a trillion-parameter unified autoregressive model that supports both multimodal understanding and generation. To facilitate further research, we present detailed visualizations of modality-agnostic expert routing in the unified model, alongside comprehensive empirical analysis of elastic training, aiming to offer profound insights to the community.
Matterhorn: Efficient Analog Sparse Spiking Transformer Architecture with Masked Time-To-First-Spike Encoding
Jan 30, 2026Spiking neural networks (SNNs) have emerged as a promising candidate for energy-efficient LLM inference. However, current energy evaluations for SNNs primarily focus on counting accumulate operations, and fail to account for real-world hardware costs such as data movement, which can consume nearly 80% of the total energy. In this paper, we propose Matterhorn, a spiking transformer that integrates a novel masked time-to-first-spike (M-TTFS) encoding method to reduce spike movement and a memristive synapse unit (MSU) to eliminate weight access overhead. M-TTFS employs a masking strategy that reassigns the zero-energy silent state (a spike train of all 0s) to the most frequent membrane potential rather than the lowest. This aligns the coding scheme with the data distribution, minimizing spike movement energy without information loss. We further propose a `dead zone' strategy that maximizes sparsity by mapping all values within a given range to the silent state. At the hardware level, the MSU utilizes compute-in-memory (CIM) technology to perform analog integration directly within memory, effectively removing weight access costs. On the GLUE benchmark, Matterhorn establishes a new state-of-the-art, surpassing existing SNNs by 1.42% in average accuracy while delivering a 2.31 times improvement in energy efficiency.
MakeupAttack: Feature Space Black-box Backdoor Attack on Face Recognition via Makeup Transfer
Aug 22, 2024Backdoor attacks pose a significant threat to the training process of deep neural networks (DNNs). As a widely-used DNN-based application in real-world scenarios, face recognition systems once implanted into the backdoor, may cause serious consequences. Backdoor research on face recognition is still in its early stages, and the existing backdoor triggers are relatively simple and visible. Furthermore, due to the perceptibility, diversity, and similarity of facial datasets, many state-of-the-art backdoor attacks lose effectiveness on face recognition tasks. In this work, we propose a novel feature space backdoor attack against face recognition via makeup transfer, dubbed MakeupAttack. In contrast to many feature space attacks that demand full access to target models, our method only requires model queries, adhering to black-box attack principles. In our attack, we design an iterative training paradigm to learn the subtle features of the proposed makeup-style trigger. Additionally, MakeupAttack promotes trigger diversity using the adaptive selection method, dispersing the feature distribution of malicious samples to bypass existing defense methods. Extensive experiments were conducted on two widely-used facial datasets targeting multiple models. The results demonstrate that our proposed attack method can bypass existing state-of-the-art defenses while maintaining effectiveness, robustness, naturalness, and stealthiness, without compromising model performance.
The Victim and The Beneficiary: Exploiting a Poisoned Model to Train a Clean Model on Poisoned Data
Apr 17, 2024



Recently, backdoor attacks have posed a serious security threat to the training process of deep neural networks (DNNs). The attacked model behaves normally on benign samples but outputs a specific result when the trigger is present. However, compared with the rocketing progress of backdoor attacks, existing defenses are difficult to deal with these threats effectively or require benign samples to work, which may be unavailable in real scenarios. In this paper, we find that the poisoned samples and benign samples can be distinguished with prediction entropy. This inspires us to propose a novel dual-network training framework: The Victim and The Beneficiary (V&B), which exploits a poisoned model to train a clean model without extra benign samples. Firstly, we sacrifice the Victim network to be a powerful poisoned sample detector by training on suspicious samples. Secondly, we train the Beneficiary network on the credible samples selected by the Victim to inhibit backdoor injection. Thirdly, a semi-supervised suppression strategy is adopted for erasing potential backdoors and improving model performance. Furthermore, to better inhibit missed poisoned samples, we propose a strong data augmentation method, AttentionMix, which works well with our proposed V&B framework. Extensive experiments on two widely used datasets against 6 state-of-the-art attacks demonstrate that our framework is effective in preventing backdoor injection and robust to various attacks while maintaining the performance on benign samples. Our code is available at https://github.com/Zixuan-Zhu/VaB.
* 13 pages, 6 figures, published to ICCV
CuriousLLM: Elevating Multi-Document QA with Reasoning-Infused Knowledge Graph Prompting
Apr 13, 2024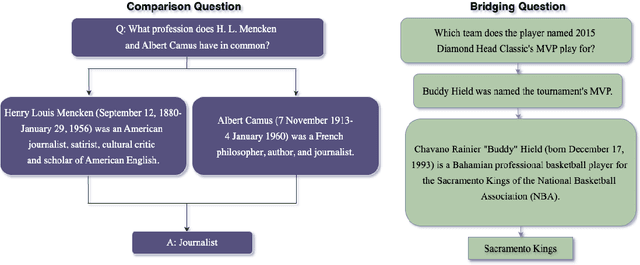

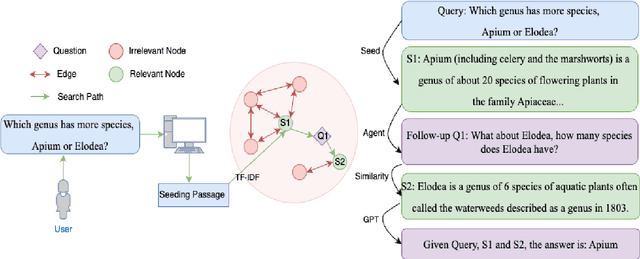

In the field of Question Answering (QA), unifying large language models (LLMs) with external databases has shown great success. However, these methods often fall short in providing the advanced reasoning needed for complex QA tasks. To address these issues, we improve over a novel approach called Knowledge Graph Prompting (KGP), which combines knowledge graphs with a LLM-based agent to improve reasoning and search accuracy. Nevertheless, the original KGP framework necessitates costly fine-tuning with large datasets yet still suffers from LLM hallucination. Therefore, we propose a reasoning-infused LLM agent to enhance this framework. This agent mimics human curiosity to ask follow-up questions to more efficiently navigate the search. This simple modification significantly boosts the LLM performance in QA tasks without the high costs and latency associated with the initial KGP framework. Our ultimate goal is to further develop this approach, leading to more accurate, faster, and cost-effective solutions in the QA domain.
Bounding and Filling: A Fast and Flexible Framework for Image Captioning
Oct 15, 2023Most image captioning models following an autoregressive manner suffer from significant inference latency. Several models adopted a non-autoregressive manner to speed up the process. However, the vanilla non-autoregressive manner results in subpar performance, since it generates all words simultaneously, which fails to capture the relationships between words in a description. The semi-autoregressive manner employs a partially parallel method to preserve performance, but it sacrifices inference speed. In this paper, we introduce a fast and flexible framework for image captioning called BoFiCap based on bounding and filling techniques. The BoFiCap model leverages the inherent characteristics of image captioning tasks to pre-define bounding boxes for image regions and their relationships. Subsequently, the BoFiCap model fills corresponding words in each box using two-generation manners. Leveraging the box hints, our filling process allows each word to better perceive other words. Additionally, our model offers flexible image description generation: 1) by employing different generation manners based on speed or performance requirements, 2) producing varied sentences based on user-specified boxes. Experimental evaluations on the MS-COCO benchmark dataset demonstrate that our framework in a non-autoregressive manner achieves the state-of-the-art on task-specific metric CIDEr (125.6) while speeding up 9.22x than the baseline model with an autoregressive manner; in a semi-autoregressive manner, our method reaches 128.4 on CIDEr while a 3.69x speedup. Our code and data is available at https://github.com/ChangxinWang/BoFiCap.
Beyond Generic: Enhancing Image Captioning with Real-World Knowledge using Vision-Language Pre-Training Model
Aug 02, 2023



Current captioning approaches tend to generate correct but "generic" descriptions that lack real-world knowledge, e.g., named entities and contextual information. Considering that Vision-Language Pre-Training (VLP) models master massive such knowledge from large-scale web-harvested data, it is promising to utilize the generalizability of VLP models to incorporate knowledge into image descriptions. However, using VLP models faces challenges: zero-shot inference suffers from knowledge hallucination that leads to low-quality descriptions, but the generic bias in downstream task fine-tuning hinders the VLP model from expressing knowledge. To address these concerns, we propose a simple yet effective method called Knowledge-guided Replay (K-Replay), which enables the retention of pre-training knowledge during fine-tuning. Our approach consists of two parts: (1) a knowledge prediction task on automatically collected replay exemplars to continuously awaken the VLP model's memory about knowledge, thus preventing the model from collapsing into the generic pattern; (2) a knowledge distillation constraint to improve the faithfulness of generated descriptions hence alleviating the knowledge hallucination. To evaluate knowledge-enhanced descriptions, we construct a novel captioning benchmark KnowCap, containing knowledge of landmarks, famous brands, special foods and movie characters. Experimental results show that our approach effectively incorporates knowledge into descriptions, outperforming strong VLP baseline by 20.9 points (78.7->99.6) in CIDEr score and 20.5 percentage points (34.0%->54.5%) in knowledge recognition accuracy. Our code and data is available at https://github.com/njucckevin/KnowCap.