 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCapArena: Benchmarking and Analyzing Detailed Image Captioning in the LLM Era
Mar 16, 2025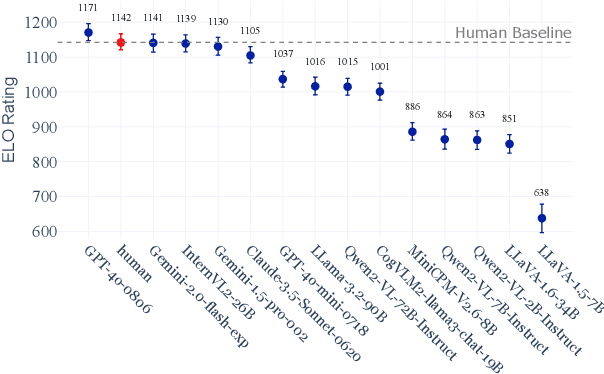

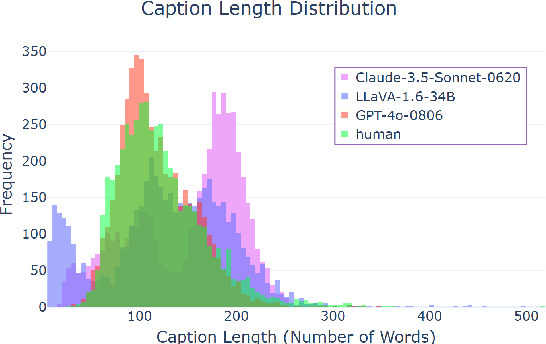
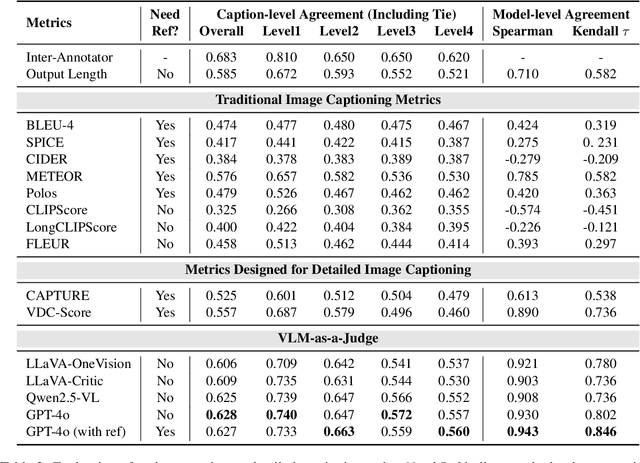
Image captioning has been a longstanding challenge in vision-language research. With the rise of LLMs, modern Vision-Language Models (VLMs) generate detailed and comprehensive image descriptions. However, benchmarking the quality of such captions remains unresolved. This paper addresses two key questions: (1) How well do current VLMs actually perform on image captioning, particularly compared to humans? We built CapArena, a platform with over 6000 pairwise caption battles and high-quality human preference votes. Our arena-style evaluation marks a milestone, showing that leading models like GPT-4o achieve or even surpass human performance, while most open-source models lag behind. (2) Can automated metrics reliably assess detailed caption quality? Using human annotations from CapArena, we evaluate traditional and recent captioning metrics, as well as VLM-as-a-Judge. Our analysis reveals that while some metrics (e.g., METEOR) show decent caption-level agreement with humans, their systematic biases lead to inconsistencies in model ranking. In contrast, VLM-as-a-Judge demonstrates robust discernment at both the caption and model levels. Building on these insights, we release CapArena-Auto, an accurate and efficient automated benchmark for detailed captioning, achieving 94.3% correlation with human rankings at just $4 per test. Data and resources will be open-sourced at https://caparena.github.io.
Beyond Generic: Enhancing Image Captioning with Real-World Knowledge using Vision-Language Pre-Training Model
Aug 02, 2023



Current captioning approaches tend to generate correct but "generic" descriptions that lack real-world knowledge, e.g., named entities and contextual information. Considering that Vision-Language Pre-Training (VLP) models master massive such knowledge from large-scale web-harvested data, it is promising to utilize the generalizability of VLP models to incorporate knowledge into image descriptions. However, using VLP models faces challenges: zero-shot inference suffers from knowledge hallucination that leads to low-quality descriptions, but the generic bias in downstream task fine-tuning hinders the VLP model from expressing knowledge. To address these concerns, we propose a simple yet effective method called Knowledge-guided Replay (K-Replay), which enables the retention of pre-training knowledge during fine-tuning. Our approach consists of two parts: (1) a knowledge prediction task on automatically collected replay exemplars to continuously awaken the VLP model's memory about knowledge, thus preventing the model from collapsing into the generic pattern; (2) a knowledge distillation constraint to improve the faithfulness of generated descriptions hence alleviating the knowledge hallucination. To evaluate knowledge-enhanced descriptions, we construct a novel captioning benchmark KnowCap, containing knowledge of landmarks, famous brands, special foods and movie characters. Experimental results show that our approach effectively incorporates knowledge into descriptions, outperforming strong VLP baseline by 20.9 points (78.7->99.6) in CIDEr score and 20.5 percentage points (34.0%->54.5%) in knowledge recognition accuracy. Our code and data is available at https://github.com/njucckevin/KnowCap.