 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeVisionPangu: A Compact and Fine-Grained Multimodal Assistant with 1.7B Parameters
Mar 05, 2026Large Multimodal Models (LMMs) have achieved strong performance in vision-language understanding, yet many existing approaches rely on large-scale architectures and coarse supervision, which limits their ability to generate detailed image captions. In this work, we present VisionPangu, a compact 1.7B-parameter multimodal model designed to improve detailed image captioning through efficient multimodal alignment and high-quality supervision. Our model combines an InternVL-derived vision encoder with the OpenPangu-Embedded language backbone via a lightweight MLP projector and adopts an instruction-tuning pipeline inspired by LLaVA. By incorporating dense human-authored descriptions from the DOCCI dataset, VisionPangu improves semantic coherence and descriptive richness without relying on aggressive model scaling. Experimental results demonstrate that compact multimodal models can achieve competitive performance while producing more structured and detailed captions. The code and model weights will be publicly available at https://www.modelscope.cn/models/asdfgh007/visionpangu.
Reinforced Reasoning for Embodied Planning
May 28, 2025
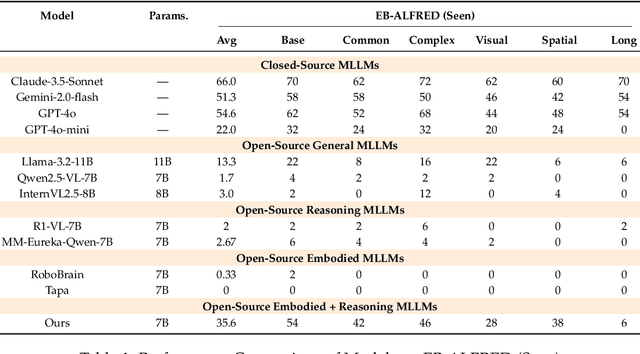


Embodied planning requires agents to make coherent multi-step decisions based on dynamic visual observations and natural language goals. While recent vision-language models (VLMs) excel at static perception tasks, they struggle with the temporal reasoning, spatial understanding, and commonsense grounding needed for planning in interactive environments. In this work, we introduce a reinforcement fine-tuning framework that brings R1-style reasoning enhancement into embodied planning. We first distill a high-quality dataset from a powerful closed-source model and perform supervised fine-tuning (SFT) to equip the model with structured decision-making priors. We then design a rule-based reward function tailored to multi-step action quality and optimize the policy via Generalized Reinforced Preference Optimization (GRPO). Our approach is evaluated on Embench, a recent benchmark for interactive embodied tasks, covering both in-domain and out-of-domain scenarios. Experimental results show that our method significantly outperforms models of similar or larger scale, including GPT-4o-mini and 70B+ open-source baselines, and exhibits strong generalization to unseen environments. This work highlights the potential of reinforcement-driven reasoning to advance long-horizon planning in embodied AI.
CapArena: Benchmarking and Analyzing Detailed Image Captioning in the LLM Era
Mar 16, 2025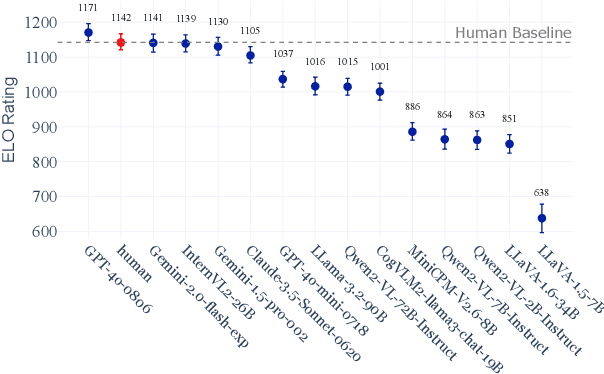

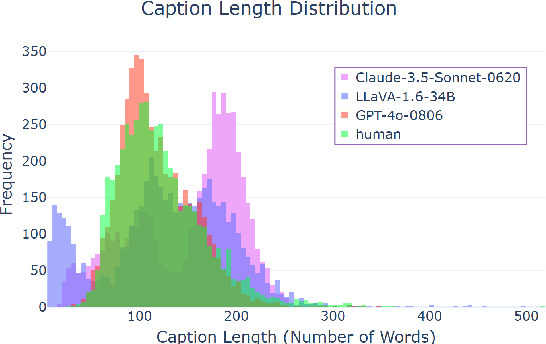
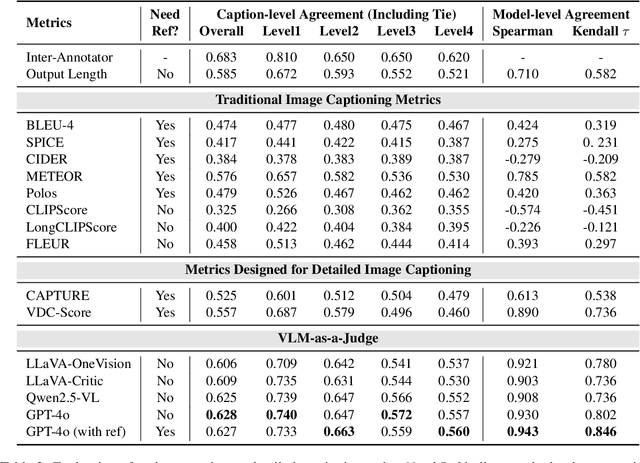
Image captioning has been a longstanding challenge in vision-language research. With the rise of LLMs, modern Vision-Language Models (VLMs) generate detailed and comprehensive image descriptions. However, benchmarking the quality of such captions remains unresolved. This paper addresses two key questions: (1) How well do current VLMs actually perform on image captioning, particularly compared to humans? We built CapArena, a platform with over 6000 pairwise caption battles and high-quality human preference votes. Our arena-style evaluation marks a milestone, showing that leading models like GPT-4o achieve or even surpass human performance, while most open-source models lag behind. (2) Can automated metrics reliably assess detailed caption quality? Using human annotations from CapArena, we evaluate traditional and recent captioning metrics, as well as VLM-as-a-Judge. Our analysis reveals that while some metrics (e.g., METEOR) show decent caption-level agreement with humans, their systematic biases lead to inconsistencies in model ranking. In contrast, VLM-as-a-Judge demonstrates robust discernment at both the caption and model levels. Building on these insights, we release CapArena-Auto, an accurate and efficient automated benchmark for detailed captioning, achieving 94.3% correlation with human rankings at just $4 per test. Data and resources will be open-sourced at https://caparena.github.io.
Boosting Chinese ASR Error Correction with Dynamic Error Scaling Mechanism
Aug 07, 2023
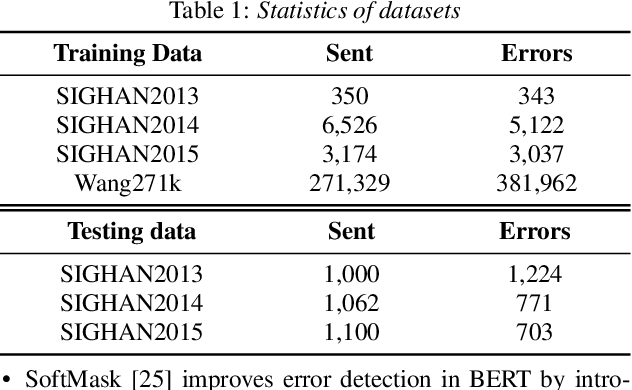
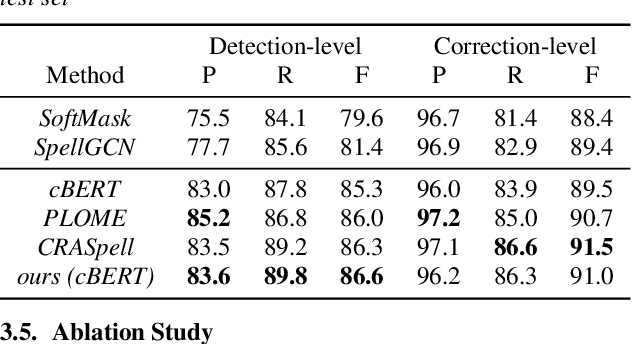
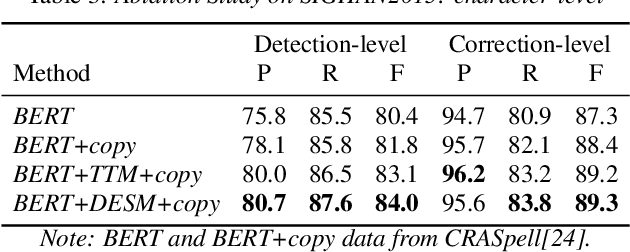
Chinese Automatic Speech Recognition (ASR) error correction presents significant challenges due to the Chinese language's unique features, including a large character set and borderless, morpheme-based structure. Current mainstream models often struggle with effectively utilizing word-level features and phonetic information. This paper introduces a novel approach that incorporates a dynamic error scaling mechanism to detect and correct phonetically erroneous text generated by ASR output. This mechanism operates by dynamically fusing word-level features and phonetic information, thereby enriching the model with additional semantic data. Furthermore, our method implements unique error reduction and amplification strategies to address the issues of matching wrong words caused by incorrect characters. Experimental results indicate substantial improvements in ASR error correction, demonstrating the effectiveness of our proposed method and yielding promising results on established datasets.
PVT-COV19D: Pyramid Vision Transformer for COVID-19 Diagnosis
Jun 30, 2022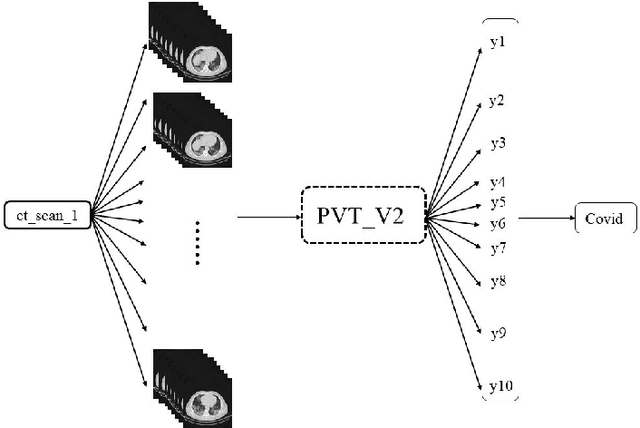

With the outbreak of COVID-19, a large number of relevant studies have emerged in recent years. We propose an automatic COVID-19 diagnosis framework based on lung CT scan images, the PVT-COV19D. In order to accommodate the different dimensions of the image input, we first classified the images using Transformer models, then sampled the images in the dataset according to normal distribution, and fed the sampling results into the modified PVTv2 model for training. A large number of experiments on the COV19-CT-DB dataset demonstrate the effectiveness of the proposed method.