 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLeveraging Biases in Large Language Models: "bias-kNN'' for Effective Few-Shot Learning
Jan 18, 2024Large Language Models (LLMs) have shown significant promise in various applications, including zero-shot and few-shot learning. However, their performance can be hampered by inherent biases. Instead of traditionally sought methods that aim to minimize or correct these biases, this study introduces a novel methodology named ``bias-kNN''. This approach capitalizes on the biased outputs, harnessing them as primary features for kNN and supplementing with gold labels. Our comprehensive evaluations, spanning diverse domain text classification datasets and different GPT-2 model sizes, indicate the adaptability and efficacy of the ``bias-kNN'' method. Remarkably, this approach not only outperforms conventional in-context learning in few-shot scenarios but also demonstrates robustness across a spectrum of samples, templates and verbalizers. This study, therefore, presents a unique perspective on harnessing biases, transforming them into assets for enhanced model performance.
Boosting Chinese ASR Error Correction with Dynamic Error Scaling Mechanism
Aug 07, 2023Chinese Automatic Speech Recognition (ASR) error correction presents significant challenges due to the Chinese language's unique features, including a large character set and borderless, morpheme-based structure. Current mainstream models often struggle with effectively utilizing word-level features and phonetic information. This paper introduces a novel approach that incorporates a dynamic error scaling mechanism to detect and correct phonetically erroneous text generated by ASR output. This mechanism operates by dynamically fusing word-level features and phonetic information, thereby enriching the model with additional semantic data. Furthermore, our method implements unique error reduction and amplification strategies to address the issues of matching wrong words caused by incorrect characters. Experimental results indicate substantial improvements in ASR error correction, demonstrating the effectiveness of our proposed method and yielding promising results on established datasets.
PVT-COV19D: Pyramid Vision Transformer for COVID-19 Diagnosis
Jun 30, 2022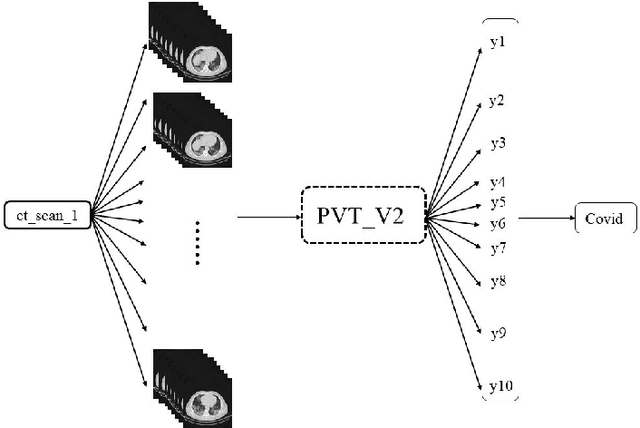

With the outbreak of COVID-19, a large number of relevant studies have emerged in recent years. We propose an automatic COVID-19 diagnosis framework based on lung CT scan images, the PVT-COV19D. In order to accommodate the different dimensions of the image input, we first classified the images using Transformer models, then sampled the images in the dataset according to normal distribution, and fed the sampling results into the modified PVTv2 model for training. A large number of experiments on the COV19-CT-DB dataset demonstrate the effectiveness of the proposed method.