 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeThe Interspeech 2026 Audio Encoder Capability Challenge for Large Audio Language Models
Mar 24, 2026This paper presents the Interspeech 2026 Audio Encoder Capability Challenge, a benchmark specifically designed to evaluate and advance the performance of pre-trained audio encoders as front-end modules for Large Audio Language Models (LALMs). While LALMs have shown remarkable understanding of complex acoustic scenes, their performance depends on the semantic richness of the underlying audio encoder representations. This challenge addresses the integration gap by providing a unified generative evaluation framework, XARES-LLM, which assesses submitted encoders across a diverse suite of downstream classification and generation tasks. By decoupling encoder development from LLM fine-tuning, the challenge establishes a standardized protocol for general-purpose audio representations that can effectively be used for the next generation of multimodal language models.
SupScene: Learning Overlap-Aware Global Descriptor for Unconstrained SfM
Jan 17, 2026Image retrieval is a critical step for alleviating the quadratic complexity of image matching in unconstrained Structure-from-Motion (SfM). However, in this context, image retrieval typically focuses more on the image pairs of geometric matchability than on those of semantic similarity, a nuance that most existing deep learning-based methods guided by batched binaries (overlapping vs. non-overlapping pairs) fail to capture. In this paper, we introduce SupScene, a novel solution that learns global descriptors tailored for finding overlapping image pairs of similar geometric nature for SfM. First, to better underline co-visible regions, we employ a subgraph-based training strategy that moves beyond equally important isolated pairs, leveraging ground-truth geometric overlapping relationships with various weights to provide fine-grained supervision via a soft supervised contrastive loss. Second, we introduce DiVLAD, a DINO-inspired VLAD aggregator that leverages the inherent multi-head attention maps from the last block of ViT. And then, a learnable gating mechanism is designed to adaptively utilize these semantically salient cues with visual features, enabling a more discriminative global descriptor. Extensive experiments on the GL3D dataset demonstrate that our method achieves state-of-the-art performance, significantly outperforming NetVLAD while introducing a negligible number of additional trainable parameters. Furthermore, we show that the proposed training strategy brings consistent gains across different aggregation techniques. Code and models are available at https://anonymous.4open.science/r/SupScene-5B73.
Reinforced Reasoning for Embodied Planning
May 28, 2025
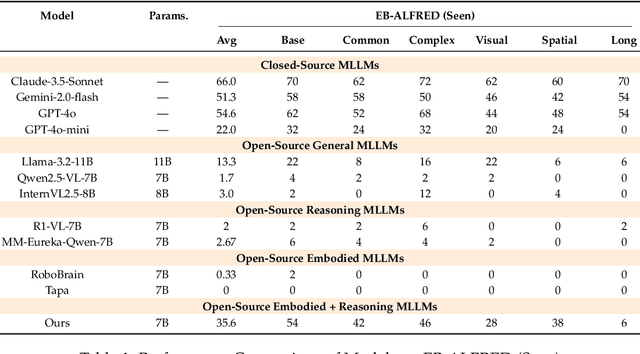


Embodied planning requires agents to make coherent multi-step decisions based on dynamic visual observations and natural language goals. While recent vision-language models (VLMs) excel at static perception tasks, they struggle with the temporal reasoning, spatial understanding, and commonsense grounding needed for planning in interactive environments. In this work, we introduce a reinforcement fine-tuning framework that brings R1-style reasoning enhancement into embodied planning. We first distill a high-quality dataset from a powerful closed-source model and perform supervised fine-tuning (SFT) to equip the model with structured decision-making priors. We then design a rule-based reward function tailored to multi-step action quality and optimize the policy via Generalized Reinforced Preference Optimization (GRPO). Our approach is evaluated on Embench, a recent benchmark for interactive embodied tasks, covering both in-domain and out-of-domain scenarios. Experimental results show that our method significantly outperforms models of similar or larger scale, including GPT-4o-mini and 70B+ open-source baselines, and exhibits strong generalization to unseen environments. This work highlights the potential of reinforcement-driven reasoning to advance long-horizon planning in embodied AI.
Dolphin: A Large-Scale Automatic Speech Recognition Model for Eastern Languages
Mar 26, 2025This report introduces Dolphin, a large-scale multilingual automatic speech recognition (ASR) model that extends the Whisper architecture to support a wider range of languages. Our approach integrates in-house proprietary and open-source datasets to refine and optimize Dolphin's performance. The model is specifically designed to achieve notable recognition accuracy for 40 Eastern languages across East Asia, South Asia, Southeast Asia, and the Middle East, while also supporting 22 Chinese dialects. Experimental evaluations show that Dolphin significantly outperforms current state-of-the-art open-source models across various languages. To promote reproducibility and community-driven innovation, we are making our trained models and inference source code publicly available.
Efficient Randomized Experiments Using Foundation Models
Feb 06, 2025



Randomized experiments are the preferred approach for evaluating the effects of interventions, but they are costly and often yield estimates with substantial uncertainty. On the other hand, in silico experiments leveraging foundation models offer a cost-effective alternative that can potentially attain higher statistical precision. However, the benefits of in silico experiments come with a significant risk: statistical inferences are not valid if the models fail to accurately predict experimental responses to interventions. In this paper, we propose a novel approach that integrates the predictions from multiple foundation models with experimental data while preserving valid statistical inference. Our estimator is consistent and asymptotically normal, with asymptotic variance no larger than the standard estimator based on experimental data alone. Importantly, these statistical properties hold even when model predictions are arbitrarily biased. Empirical results across several randomized experiments show that our estimator offers substantial precision gains, equivalent to a reduction of up to 20% in the sample size needed to match the same precision as the standard estimator based on experimental data alone.
Structured Learning in Time-dependent Cox Models
Jun 21, 2023Cox models with time-dependent coefficients and covariates are widely used in survival analysis. In high-dimensional settings, sparse regularization techniques are employed for variable selection, but existing methods for time-dependent Cox models lack flexibility in enforcing specific sparsity patterns (i.e., covariate structures). We propose a flexible framework for variable selection in time-dependent Cox models, accommodating complex selection rules. Our method can adapt to arbitrary grouping structures, including interaction selection, temporal, spatial, tree, and directed acyclic graph structures. It achieves accurate estimation with low false alarm rates. We develop the sox package, implementing a network flow algorithm for efficiently solving models with complex covariate structures. Sox offers a user-friendly interface for specifying grouping structures and delivers fast computation. Through examples, including a case study on identifying predictors of time to all-cause death in atrial fibrillation patients, we demonstrate the practical application of our method with specific selection rules.
CLARE: Conservative Model-Based Reward Learning for Offline Inverse Reinforcement Learning
Feb 21, 2023


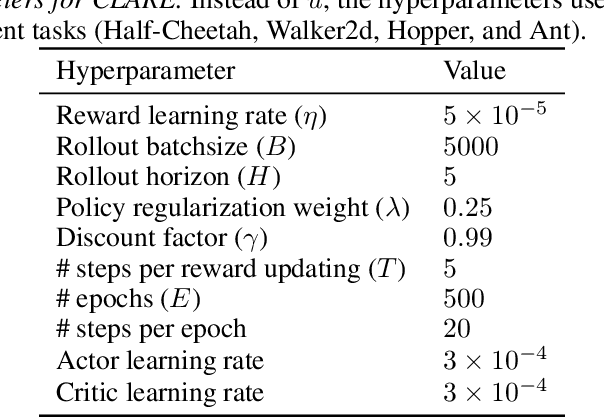
This work aims to tackle a major challenge in offline Inverse Reinforcement Learning (IRL), namely the reward extrapolation error, where the learned reward function may fail to explain the task correctly and misguide the agent in unseen environments due to the intrinsic covariate shift. Leveraging both expert data and lower-quality diverse data, we devise a principled algorithm (namely CLARE) that solves offline IRL efficiently via integrating "conservatism" into a learned reward function and utilizing an estimated dynamics model. Our theoretical analysis provides an upper bound on the return gap between the learned policy and the expert policy, based on which we characterize the impact of covariate shift by examining subtle two-tier tradeoffs between the exploitation (on both expert and diverse data) and exploration (on the estimated dynamics model). We show that CLARE can provably alleviate the reward extrapolation error by striking the right exploitation-exploration balance therein. Extensive experiments corroborate the significant performance gains of CLARE over existing state-of-the-art algorithms on MuJoCo continuous control tasks (especially with a small offline dataset), and the learned reward is highly instructive for further learning.
Multi-Phase EMTR-based Fault Location Method Using Direct Convolution Considering Frequency-Dependent Parameters and Lossy Ground
Dec 29, 2022



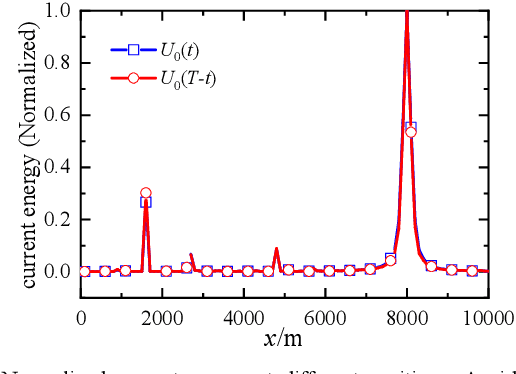
Many Electromagnetic time reversal (EMTR)-based fault location methods were proposed in the latest decade. In this paper, we briefly review the EMTR-based fault location method using direct convolution (EMTR-conv) and generalize it to multi-phase transmission lines. Moreover, noting that the parameters of real transmission lines are frequency-dependent, while constant-parameters were often used during the reverse process of EMTR-based methods in the previous studies, we investigate the influence of this simplification to the fault location performance by considering frequency-dependent parameters and lossy ground in the forward process which shows the location error increases as the distance between the observation point and the fault position increases, especially when the ground resistivity is high. Therefore, we propose a correction method to reduce the location error by using double observation points. Numerical experiments are carried out in a 3-phase 300-km transmission line considering different ground resistivities, fault types and fault conditions, which shows the method gives good location errors and works efficiently via direct convolution of the signals collected from the fault and the pre-stored calculated transient signals.
A Fault Location Method Using Direct Convolution: Electromagnetic Time Reversal or Not Reversal
Nov 27, 2021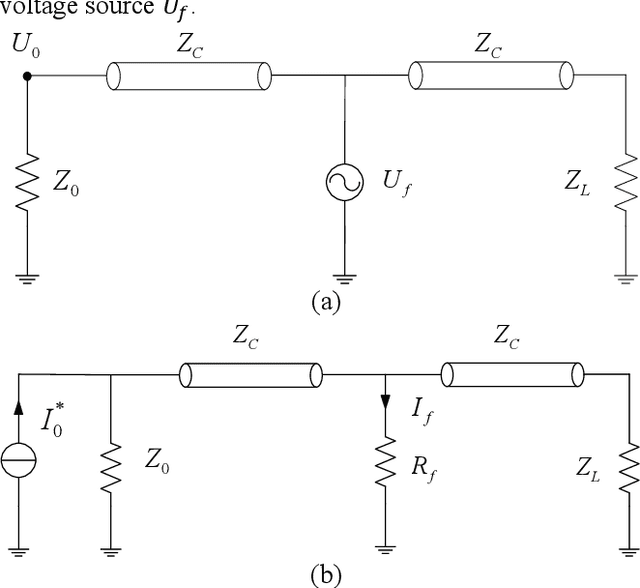
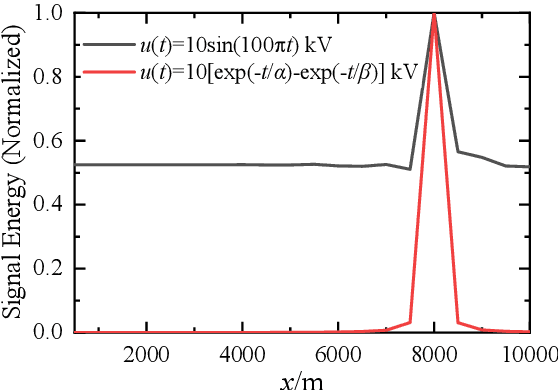
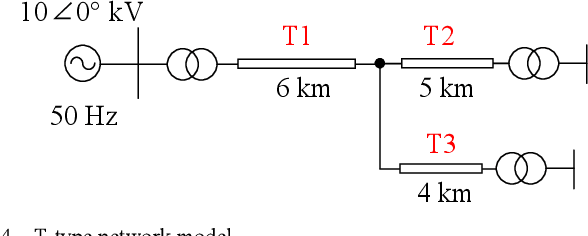
Electromagnetic time reversal (EMTR) is drawing increasing interest in short-circuit fault location. In this letter, we investigate the classic EMTR fault location methods and find that it is not necessary to reverse the obtained signal in time which is a standard operation in these methods before injecting it into the network. The effectiveness of EMTR fault location method results from the specific similarity of the transfer functions in the forward and reverse processes. Therefore, we can inject an arbitrary type and length of source in the reverse process to locate the fault. Based on this observation, we propose a new EMTR fault location method using direct convolution. This method is different from the traditional methods, and it only needs to pre-calculate the assumed fault transients for a given network, which can be stored in embedded hardware. The faults can be located efficiently via direct convolution of the signal collected from a fault and the pre-stored calculated transients, even using a fraction of the fault signal.
GigaSpeech: An Evolving, Multi-domain ASR Corpus with 10,000 Hours of Transcribed Audio
Jun 13, 2021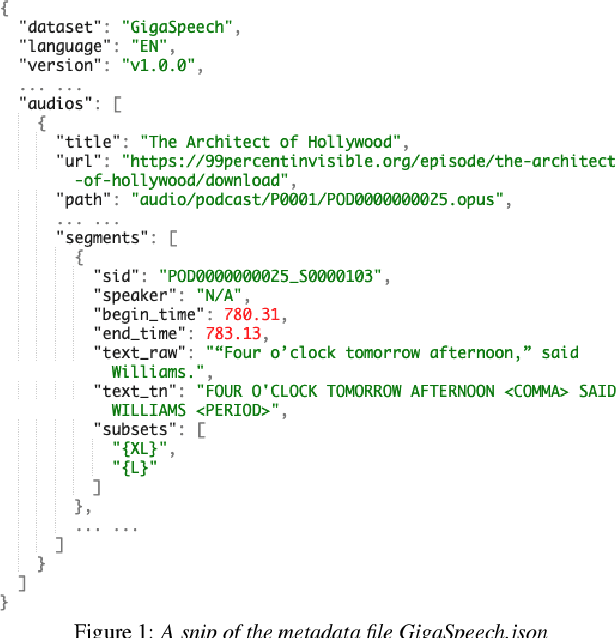
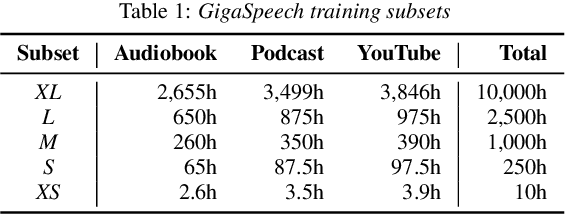
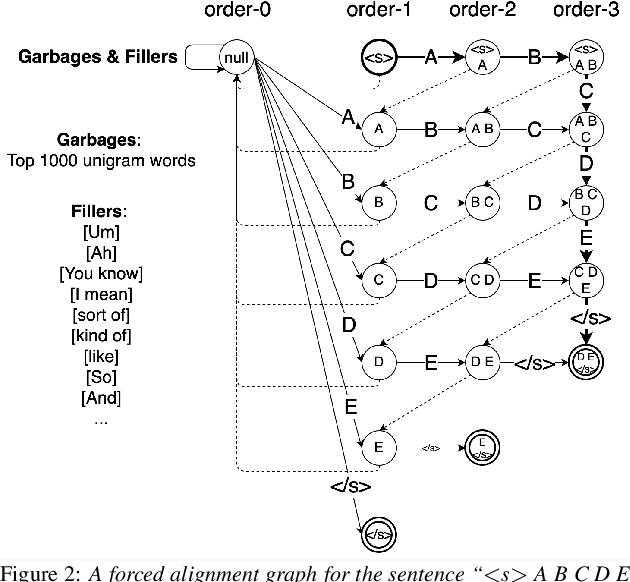
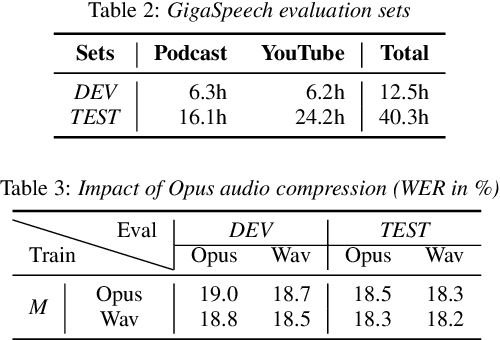
This paper introduces GigaSpeech, an evolving, multi-domain English speech recognition corpus with 10,000 hours of high quality labeled audio suitable for supervised training, and 40,000 hours of total audio suitable for semi-supervised and unsupervised training. Around 40,000 hours of transcribed audio is first collected from audiobooks, podcasts and YouTube, covering both read and spontaneous speaking styles, and a variety of topics, such as arts, science, sports, etc. A new forced alignment and segmentation pipeline is proposed to create sentence segments suitable for speech recognition training, and to filter out segments with low-quality transcription. For system training, GigaSpeech provides five subsets of different sizes, 10h, 250h, 1000h, 2500h, and 10000h. For our 10,000-hour XL training subset, we cap the word error rate at 4% during the filtering/validation stage, and for all our other smaller training subsets, we cap it at 0%. The DEV and TEST evaluation sets, on the other hand, are re-processed by professional human transcribers to ensure high transcription quality. Baseline systems are provided for popular speech recognition toolkits, namely Athena, ESPnet, Kaldi and Pika.